

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll write about how neural networks process and recognize images. Neural networks are capable of solving various types of problems with images. For instance, some of the most popular are image classification and object detection. We’ll explore how neural networks solve these problems, explaining the process and its mechanics.
Firstly, we’ll introduce all the problems, and after that, we’ll explain each of them in more detail. Also, we’ll present some of the most popular applications and examples.
Neural networks have revolutionized the field of computer vision by enabling machines to recognize and analyze images. They have become increasingly popular due to their ability to learn complex patterns and features. Especially convolutional neural networks (CNN), are the most popular type of neural network used in image processing.
But also vision transformers (ViT) have become more and more popular in recent times due to the breakthrough achievements of generative pre-trained transformers (GPT) and other transformer-based architectures in natural language processing.
Generally speaking, neural networks process and recognize images in different ways. It depends on the network architecture and the problem we must solve. Some of the most common problems that neural networks solve with images include:
There are some other problems that neural networks solve with images, including image captioning, image restoration, landmark detection, human pose estimation, and style transfer, but we won’t cover them in this article.
Image classification is the most popular task in computer vision, where we train a neural network to assign a label or category to an input image. This can be accomplished using various techniques, but the most common are convolutional neural networks (CNN).
CNNs comprise multiple layers, including convolutional layers, pooling layers, and fully connected layers. The convolutional layers are the heart of the network and are responsible for learning features from the input image. Specifically, they apply a series of filters to the image, each capturing a particular pattern or feature, such as edges, textures, or shapes.
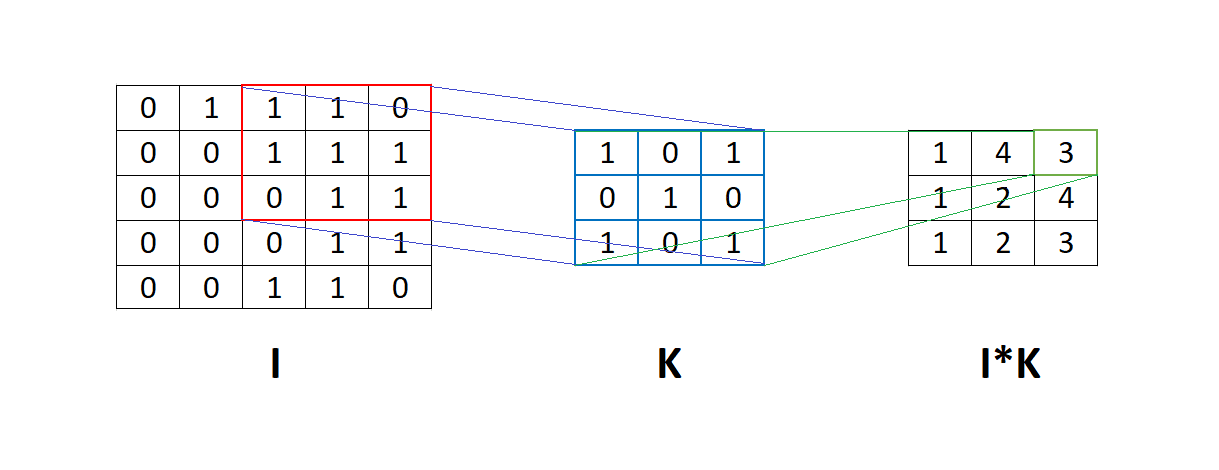
For example, in the image below, we see the matrix  to which we apply convolution with the filter
to which we apply convolution with the filter  . It means that the filter goes through the whole matrix , and element-wise multiplication is applied between the corresponding elements of the matrix and the filter . After that, we sum the result of this element-wise multiplication into one number:
. It means that the filter goes through the whole matrix , and element-wise multiplication is applied between the corresponding elements of the matrix and the filter . After that, we sum the result of this element-wise multiplication into one number:
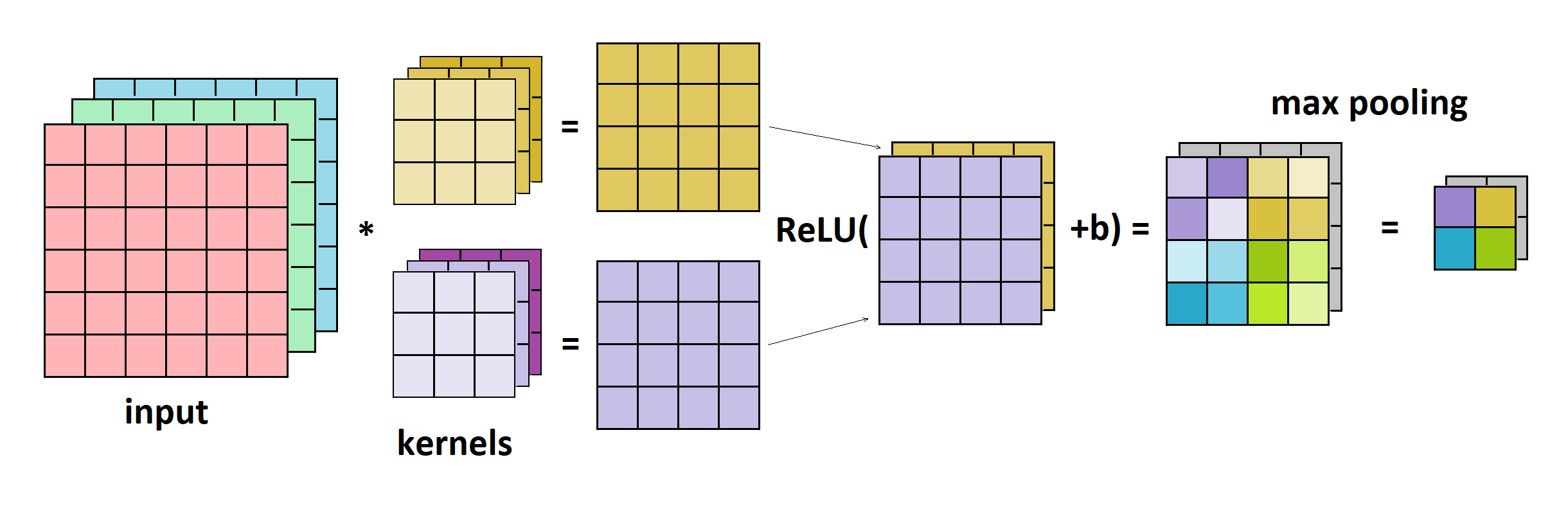
The ReLU activation function is commonly used after the convolutional layer, followed by a pooling layer. The pooling layer applies filters in the same way as the convolutional layer but only calculates the maximal or average item instead of convolution. In the image below, we can see the example of the convolutional layer, ReLU, and max pooling:
Over the years, several CNN architectures have been developed, each with its own unique features and advantages. Some of the most popular are:
The key idea behind vision transformers is to apply the transformer architecture, originally designed for natural language processing tasks, to image processing tasks. The transformer architecture consists of self-attention mechanisms, which allow the model to attend to different parts of the input sequence when making predictions.
In image processing, the input to the transformer model is a sequence of image patches rather than the entire image. These patches are then processed by a series of transformer blocks, enabling the model to capture local and global information:
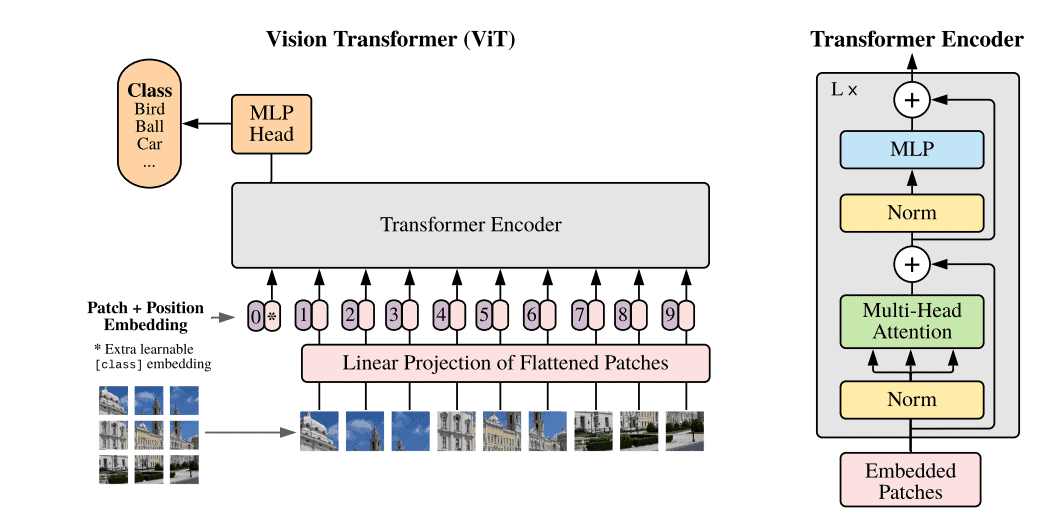
Vision transformers have achieved state-of-the-art performance on benchmark datasets, including ImageNet and COCO. However, they typically require significantly more computational resources than traditional CNNs, which can make them less practical for certain applications.
Object detection is detecting objects within an image or video by assigning a class label and a bounding box. For example, it takes an image as input and generates one or more bounding boxes, each with the class label attached.
Object detection is a combination of two tasks:
Algorithms for object localization identify an object’s location in an image and indicate its position by drawing a box around it. These algorithms take an image containing one or more objects as input and provide the location of the objects by specifying the position, height, and width of the bounding boxes:

Similar to image classification, CNNs are commonly used for this task. We can train the CNN on a dataset of labelled images, each with bounding boxes and class labels identifying the objects in the image. During training, the network learns to identify and classify objects in the image and locate them using bounding boxes.
The most popular neural network architectures for object detection are:
YOLO is one of the most popular neural network architectures and object detection algorithms. The YOLO algorithm divides the input image into a grid and predicts bounding boxes and class probabilities for each grid cell. It predicts the class probabilities and locations of multiple objects in a single pass through the network, making it faster and more efficient than other object detection algorithms.
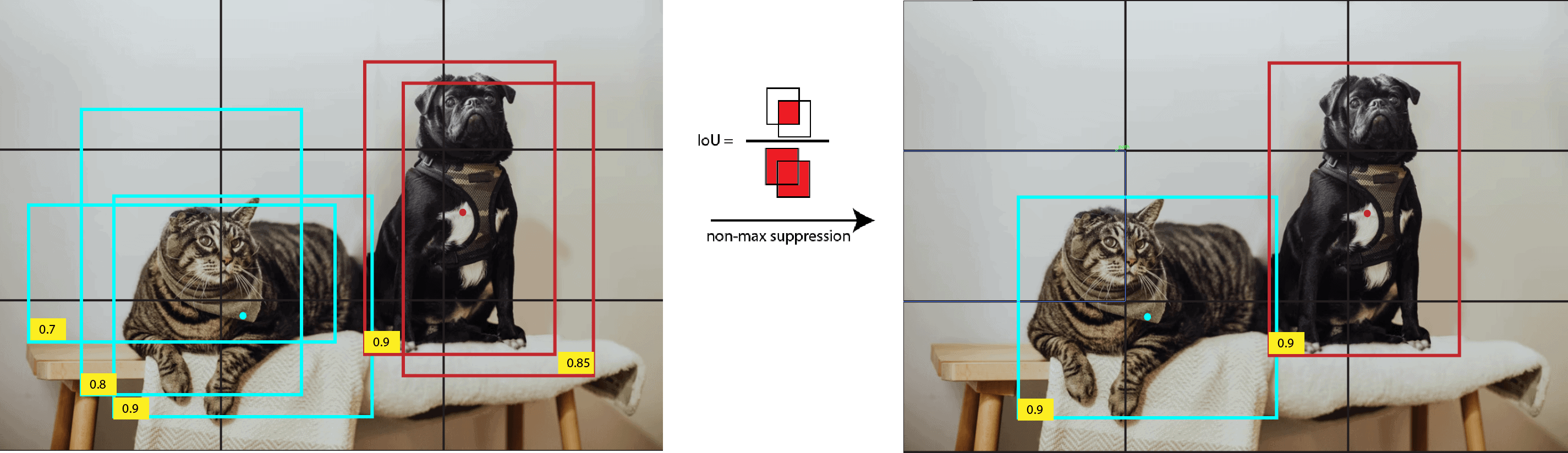
To filter out overlapping bounding boxes and select the most accurate one, it uses a technique called non-max suppression. Non-max suppression works by selecting the bounding box with the highest confidence score. After that, it removes any other boxes that overlap with it by more than a certain threshold:
YOLO has multiple versions, with each version improving upon the previous one. More information on YOLO algorithms can be found in our article here.
Neural networks are a popular tool for image segmentation, and there are several types of image segmentation that we can do using neural networks. Some of the most common types of image segmentation with neural networks are:
Semantic segmentation includes assigning a class label to every pixel in the image. Basically, it means that if there are two or more objects of the same class in the image, the semantic segmentation will return a single mask including all the objects of the same class:

Neural networks can perform semantic segmentation by training them to output a segmentation mask that assigns a class label to each pixel in the image. CNNs are the most common neural network for solving semantic segmentation. Some of the popular architectures are:
For example, the SegNet architecture looks like:
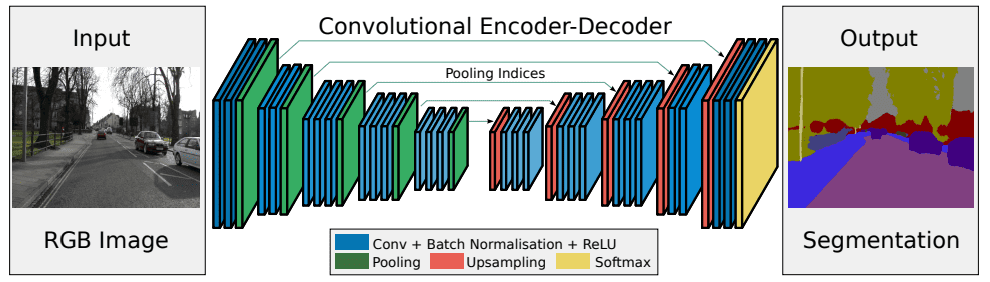
In addition to semantic segmentation, instance segmentation can distinguish different instances of the same class. Neural networks can perform instance segmentation by outputting a segmentation mask that assigns class and instance labels to each pixel in the image.
Specifically, the network is trained to detect and differentiate between multiple instances of objects in the image:

Some of the popular architectures for instance segmentation are:
Boundary detection is the process of identifying the edges or boundaries of objects in an image. Neural networks can perform boundary detection by training them to output a binary mask that highlights the boundaries of objects in the image. Several boundary detection architectures work well, including:
In summary, panoptic segmentation is a combination of semantic and instance segmentation. It means that this approach separates the image into distinct objects or things (instance segmentation) and amorphous background or stuff regions (semantic segmentation).
We can perform panoptic segmentation using neural networks by training them to output a segmentation mask that includes both object instances and stuff regions. Some of the most promising models are:
Neural networks have the ability to generate realistic images by learning from a large dataset of images. Image generation using neural networks is a complex process that involves modelling the probability distribution of the input images and generating new images that fit within that distribution. There are several neural network architectures that we can use for image generation:
Besides that, there are some hybrid solutions like DALL-E created by OpenAI.
GANs are a popular architecture for image generation that involves two neural networks: a generator and a discriminator. The generator learns to generate images from a random noise vector, similar to the real images in the dataset. At the same time, the discriminator learns to distinguish between the real and generated images. Through trial and error, the generator learns to generate images that fool the discriminator, resulting in realistic images being generated:

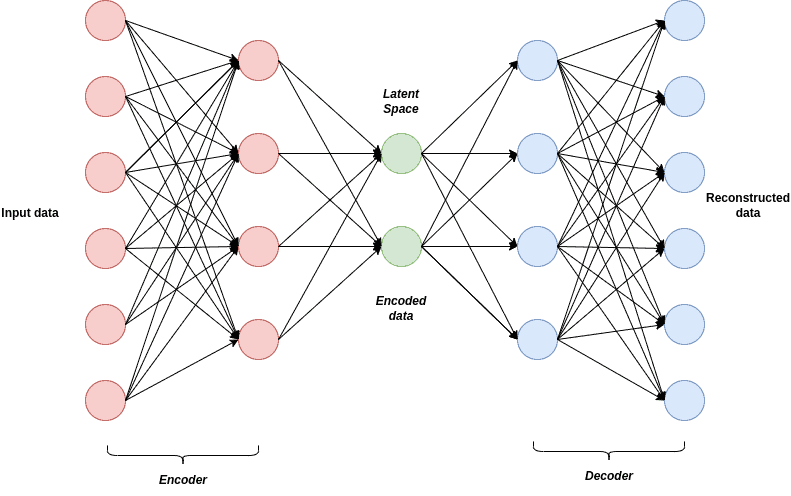
VAEs are neural networks that have two parts: an encoder and a decoder. The encoder network maps the input image to a lower-dimensional latent space vector. Afterward, the decoder network generates a new image from that vector. By sampling points from the latent space, the VAE can generate new images that are similar to the input images:
Autoregressive models generate images pixel-by-pixel, using the probability distribution of each pixel given the previous pixels as a guide. They can produce high-quality images but can be computationally expensive and time-consuming. Several types of autoregressive models can be used for image generation, including PixelCNN and PixelRNN.
DALL-E is a neural network architecture developed by OpenAI that can generate images from textual descriptions. The current version, DALL-E 2, primarily consists of two parts: Prior and Decoder. Prior converts the text input into the image embedding vector. After that, Decoder takes that vector and generates an image.
An example of one specific DALL-E output is presented below:
In this article, we’ve presented a broad outline of how neural networks process and recognize images through various applications. In general, we can distinguish these networks into two major types:
There is no concrete answer to how neural networks recognize images. Every neural network architecture has its own specific parts that make the difference between them. Also, neural networks in every computer vision application have some unique features and components.