

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In computer vision, we aim to extract useful information from images. We can do that by isolating or detecting objects within a frame, through the implementation of image segmentation.
In this tutorial, we’ll explain why and how we can do that. Then, we’ll discuss the two main types of this technique, namely, instance and semantic segmentation methods.
In image-segmentation tasks, we identify each pixel’s class.
A group of pixels belonging to the same class constitutes a segment. Usually, we aim to create segments by isolating objects in an image. By doing that, we change the image’s representation into a new one. Instead of actual pixel values, pixels in a segmented image can be thought of as containing class labels.
There are several methods of doing that, and the simplest one is thresholding. If we have a gray-scale image in which we want to split the foreground from the background, we define a threshold, let’s say 149. All the pixels below this value will be considered to belong to the foreground. In contrast, the background will consist of every pixel with a value above 149. For example:

Biology gives us one of the oldest applications of image segmentation. If we have a sample from human tissue, we might need to isolate cancer cells from healthy ones. Segmentation is warranted in this case because the structure of a cancer cell differs from that of a normal cell, so an image would reflect that.
So, after we isolate the cells with segmentation tools, we can continue with the morphological analysis.
There are two main types of segmentation: instance segmentation and semantic segmentation.
In semantic segmentation, all the objects that belong to the same class share the label. So, if we’re working with autonomous vehicle applications, all pedestrians will receive the same label. The same goes for cars. For instance:

In both semantic and instance segmentations, deep-learning methods have achieved the best performance.
One such tool for semantic segmentation is SegNet. It’s an encoder-decoder network:
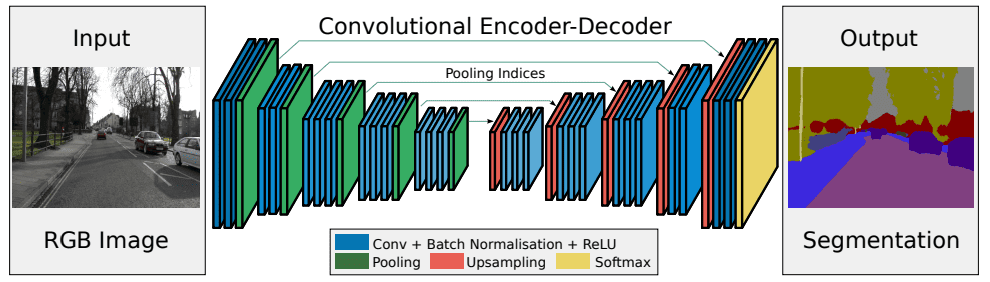
During the encoder phase, it downsamples the input image with max-pooling layers after the convolution through 13 layers. After each pooling step, it saves the indices from each filter together with the maximum values in each subgrid. The indices indicate where the pixels originally were.
Then, the decoder stage starts. After applying max-pooling filters during encoding, we get low-resolution feature maps that need to be upsampled. To perform this upsample, SegNet uses the indices it saved during encoding. It restores the pixels that defined the max-pooling and fills the rest with zeros:
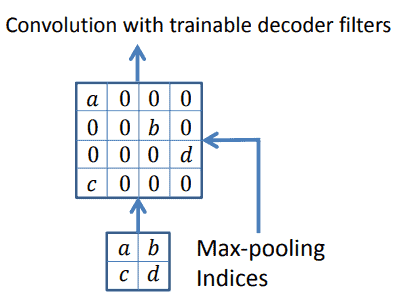
Lastly, this sparse map, made of zeros and the max-pooling values, is convolved to provide us with dense feature maps.
In instance segmentation, each detected object receives its unique label. We usually implement this type of segmentation when the number of objects or their independence is relevant. For instance, we may want to count people at a concert. To do so, we need to isolate and differentiate each visitor.
Returning to our example with an autonomous vehicle, each pedestrian and car will receive unique labels (which we represent using different colors):

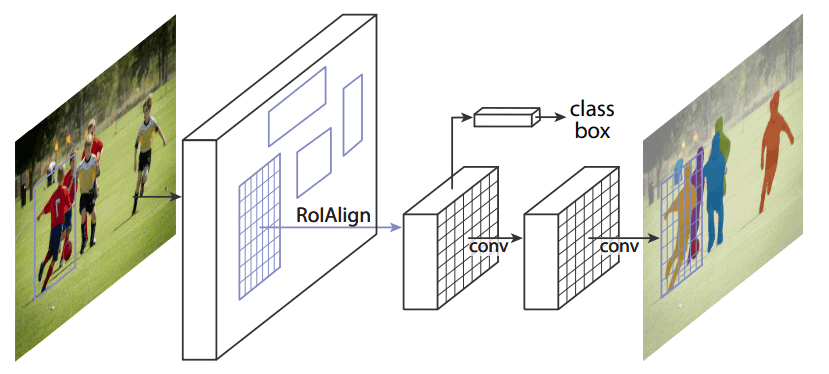
One of the most eminent methods for instance segmentation is Mask R-CNN.
Mask R-CNN works in stages. The first stage is the Region Proposal Network (RPN), which defines the candidates for bounding.
In the next step, the class is predicted along with the bounding box offset and a mask for each Region of Interest. The main novelty of this method is the parallel bounding-box classification and regression:
In this article, we talked about segmentation. That’s a relevant challenge in the computer vision field due to its large number of applications.
We should always define first if our application demands instance or semantic segmentation. This will define the following steps and more importantly, the method to use.
If we need to know the number of objects in a scene, we should go for instance segmentation. But, if we only need to group the objects of the same class, we’ll use semantic segmentation algorithms.