

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn how human pose estimation works in a computer vision system. We shall comprehend how we can infer a human pose and its corresponding meaning from a collection of pictures or a video. We’ll also talk about how the pipeline for pose estimation is altering as a result of cutting-edge deep-learning approaches.
The objective of Pose Estimation, a general problem in computer vision, is to identify the location and orientation of an item or human. In the case of human pose estimation, we typically accomplish this by estimating the locations of various key points like hands, heads, elbows, and so on. These key points in photos and videos are what our machine-learning models seek to track:
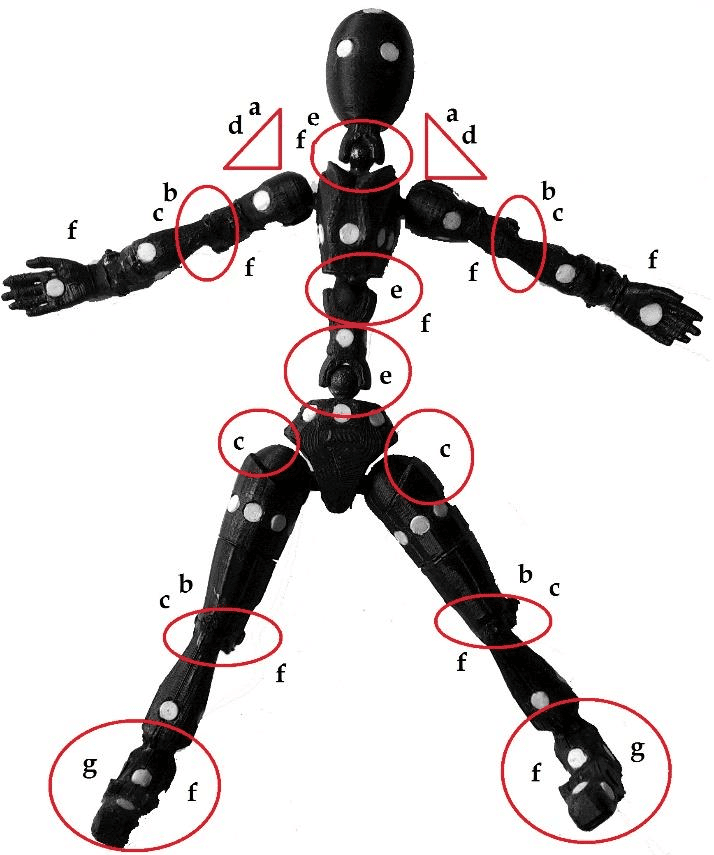
The pose estimator model receives an image or video as input and outputs the coordinates of any joints and body parts that it detects. It also generates a confidence score indicating the accuracy of the estimates. We can alternatively define pose estimation as the challenge of figuring out the location and orientation of a camera concerning a specific person or item.
A common task in computer vision is pose estimation. Computer vision is an area of Artificial Intelligence that allows machines to process images to mimic human vision. Computer vision tasks like human position estimate and tracking include finding, connecting, and following semantic key points.
In photos or videos, human pose estimation recognizes and categorizes the positions of human body components and joints. To represent and infer human body positions in 2D and 3D space, a model-based technique is typically used. One particular class of flexible objects includes people. Keypoints will be in different positions concerning others when we bend our arms or legs.
The goal of human pose estimation is to foretell the positions of joints and body parts in still photos and moving pictures. Knowing a person’s body pose is essential for identifying actions since certain human behaviors frequently influence pose motions.
Human pose estimation involves describing the joints of the human body, such as the wrist, shoulder, knees, eyes, ears, ankles, and arms, which are crucial in pictures and videos that can depict a person’s position.
2D human pose estimation is estimating the 2D position or spatial placement of key points on the human body from visuals like photos and movies. It is simply the estimations of keypoint locations in 2D space concerning an image or video frame. For every key point, the model predicts an X and Y coordinate.
We use different hand-crafted feature extraction approaches for each body part in traditional 2D human pose estimate methods. To get global pose structures, early computer vision works represent the human body as a stick figure. Modern deep learning-based techniques, however, have made important strides by greatly enhancing performance for both single-person and multi-person pose estimation.
By including a z-dimension in the prediction, 3D pose estimation makes an item in a 2D image appear to be 3D. The intricacy involved in creating datasets and algorithms that estimate several parameters, such as the backdrop scene of an image or video, light conditions, and context, makes 3D pose estimation a big problem for machine learning developers.
For many years, the main topic of debate for numerous classical object detection applications has been the detection of persons. Using stance detection and pose tracking, computers can now read human body language thanks to recent advancements in machine learning algorithms.
These detections’ accuracy and hardware needs have now improved to the point where they are economically practical. Autonomous driving is one such application where this method has already demonstrated its viability. Computers can recognize and track human poses in real time, which allows them to more accurately perceive and forecast pedestrian behavior.
Pose estimation also differs in some significant ways from other typical computer vision tasks. Object detection is a task that locates objects in an image. However, this localization is usually coarse-grained and consists of a bounding box that contains the object. Pose estimation takes a step further by foretelling the precise location of the object’s key points.
Bottom-up and top-down approaches are the two main categories into which all human pose estimation techniques fall. Bottom-up approaches first assess each body joint, then organize them into a certain stance. Top-down approaches first run a body detector and then identify body joints inside the identified bounding boxes.
The model uses a bottom-up technique to identify every instance of a specific keypoint (for example, all left hands) in an image before attempting to put together clusters of keypoints into skeletons for different objects.
In contrast, a top-down technique involves first using an object detector to crop each instance of an item, after which the network estimates the key points within each cropped region.
We refer to the combination of an object’s position and orientation as its pose in computer vision and robotics. We use the phrase occasionally to refer to just the orientation. Pose estimate is the process of figuring out an object’s position concerning a given coordinate system.
We refer to any mathematical or logical framework that aids in uniquely defining a specific position as a pose definition. We can define a pose using a variety of models. The pose definition must be strong enough to withstand difficult real-world variables such as body types, relative lengths, and occlusion. If an estimated pose can be specifically specified and defined in a model, we can only infer its meaning from it.
The issue of estimating human pose has many potential answers. Overall, though, we can divide the methods that are now in use into three groups: absolute pose estimate, relative pose estimation, and appropriate pose estimation, which combines the two.
Fundamentally, most algorithms anticipate a person’s position concerning the background using their pose and orientation. It is a two-step approach that first recognizes human bounding boxes before assessing the pose of each box.
Area models are models with contours that are used to estimate 2D pose. The appearance and shape of the human body are shown using planar models. Typically, we represent the bodily parts by several rectangles that roughly approximate the contours of the human body. With the help of limits and rectangles that depict a person’s contour, these models depict the appearance and shape of a human body.
The Active Shape Model (ASM), which uses principal component analysis to record the whole human body graph and the silhouette deformations, is a well-known example.
For estimating 3D poses, there are models called volumetric models. Many well-known 3D human body models are available and are utilized for deep learning-based 3D human pose estimation to recover 3D human mesh.
A completely trainable, modular, deep learning framework houses the GHUM pipeline, a statistical, articulated 3D human form modeling system. It comprises a variety of common 3D human body models and poses that we represent by geometric meshes and shapes of people. Often, we record these models and poses for deep learning-based 3D human pose estimation.
Both 2D and 3D pose estimation use the kinematic model, also referred to as a skeleton-based model. We use a set of joint positions and limb orientations to represent the human body structure in this adaptable and intuitive model of the human body:
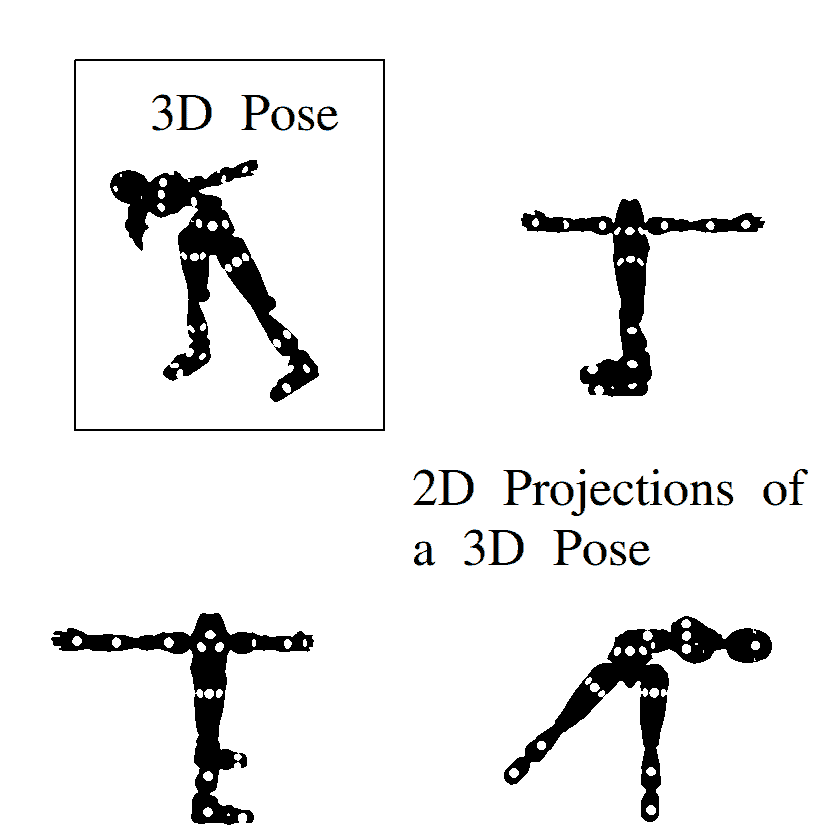
Fields interested in human motion place a high value on kinematic data, such as joint angles and joint velocities. For instance, athletes can request an analysis of their throwing or jumping actions to determine injury risk or improve performance. In such circumstances, skeleton-based models are routinely employed.
A multi-person pose estimate is a task of estimating the poses of numerous persons in a single frame.
Utilizing a cutting-edge, effective convolutional network design, the first stage processes the entire input frame at each time step. It forecasts the 2D body joint locations and their relationships, as well as an intermediate 3D depiction of each subject’s body part:

We use the anticipated 2D pose and the intermediate 3D representation in the second stage, which employs a fully connected network to predict the 3D stance for each subject.
We’ll go over the fundamental processes in pose estimation in this section. With a general pose-defining model in mind, we’re presenting the pipeline. Nevertheless, regardless of the pose definition model employed, the concepts are the same.
There are four main steps in the pose estimation pipeline:

Let’s discuss them below.
To extract bounding boxes over one or more human subjects, we need to analyze images or video frames:

At the end of this step, we have acquired a bounding box sub-image that contains only one human subject. This is important since the pose definition models are (generally) defined for only one pose subject.
We use a human pose definition model to identify the key points for each bounding box:

We generate the visual representation of the detected pose using the key points, together with the information from the pose definition model.
To give the detected pose meaning, we compare the mathematical or logical description of the model with already-existing descriptions in the database:
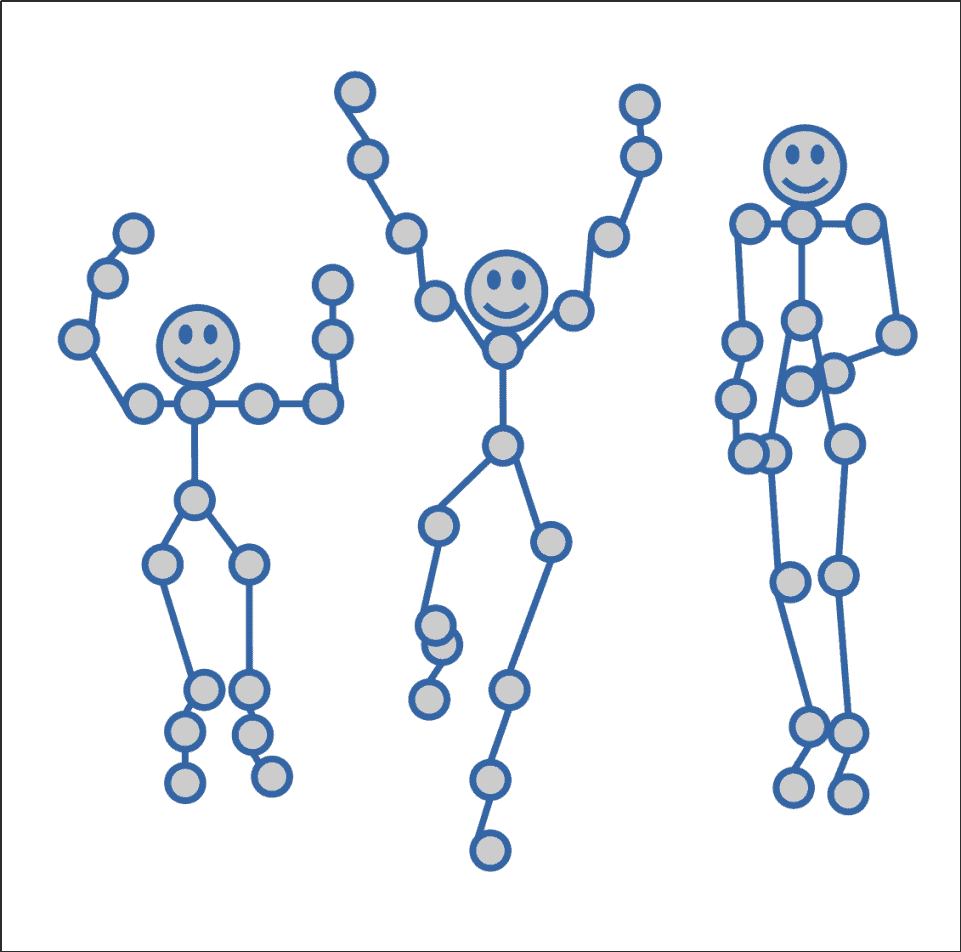
A pose definition model includes a mechanism to compare the closeness of two instances of the model. We use this information to locate the pose in the library of already defined poses with distinct meanings. The detected pose is now identified to belong to a particular meaningful class.
The capacity of deep learning-based methods to generalize any function is a key characteristic of these models (if a sufficient number of nodes are present in the given hidden layer). It is possible to use a general convolutional neural network, which was initially developed for classification tasks, for the distinct task of localization.
Despite the strong performance of recently established deep learning-based systems in estimating human pose, problems still exist due to a lack of training data, depth ambiguities, and occlusion.
The most urgent question in a deep learning project is usually always, “Can we collect enough labeled data?” Our model will perform better if we have more labeled data. After creating our dataset, we must preprocess it to provide features that will be helpful to our deep learning models.
After dividing our dataset, we may select our layers and loss function. We assess the model’s performance on our validation set after each training iteration. We can predict how well our model will perform on brand-new, untested data based on how well it performed on the validation set.
We chose activity as our preferred contextual information because different activities in humans typically entail noticeably distinct stances, which in turn tend to be more prevalent among some activities.
The question at hand is whether knowing an image involves a specific activity can enhance the model’s ability to estimate poses. For instance, we can inform a pose estimator that it will probably see more sprinting, diving, and kicking than sitting if it knows an image is from a rugby match.
In this article, we learned how human pose estimation works in a computer vision system. We understood different types of pose estimation techniques and models. We discussed how deep learning is altering the pose estimation approach and went through the fundamental pose estimation pipeline.