

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about two popular deep-learning models for image generation, Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). First, we’ll briefly introduce these two approaches, and we’ll mainly focus on their differences. We’ll discuss their behalves and limitations and mention their contributions to real-world applications.
Variational Autoencoder is a powerful type of generative model that was first introduced by Diederik P. Kingma and Max Welling in 2013. Generally, VAEs are widely used as unsupervised models to produce high-quality images by analyzing and retrieving the fundamental information of the input data. Mainly, VAEs are a probabilistic architecture that consists of two major aspects, the encoder, and the decoder network. The architecture of the VAE algorithm, along with its two main parts, looks as follows:
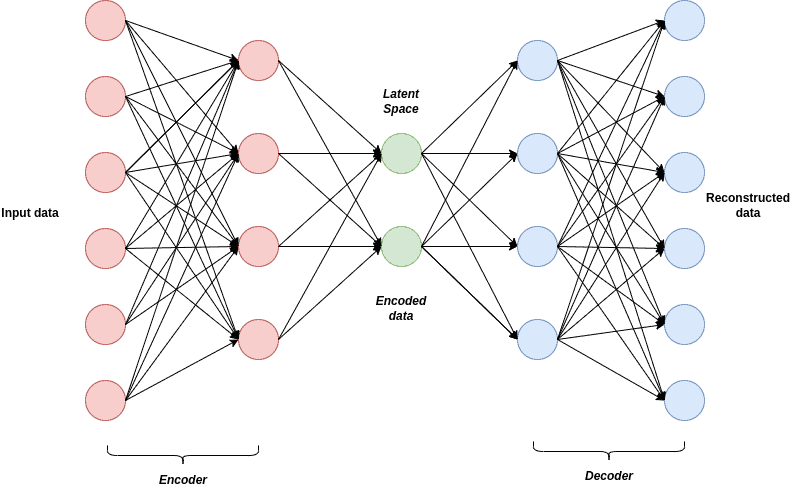
The first component of a VAE, the encoder, is usually built by a neural network architecture such as a feedforward convolutional network and is responsible for learning and encoding the representation of the input and driving it into a latent space. Also, the generated latent space is usually a mixture of Gaussian distributions.
The second component of a VAE is a Decoder, formed by a convolutional neural network as well. Once the latent space is formed by the encoder, the Decoder’s work is to convert the latent space in order to get back to the original input. Thus, it aims to generate an output that represents the input as well as possible by maximizing the likelihood of the newly created images with respect to the input data.
Generative Adversarial Networks were first introduced by Ian J. Goodfellow in 2014. Just like VAEs, they also consist of two major components that play a game of two, trying to learn the distribution of the input data to generate new synthetic ones. GANs consist of the generator and the discriminator that compete with each other and are trained together simultaneously. The architecture of the GAN algorithm looks as follows.
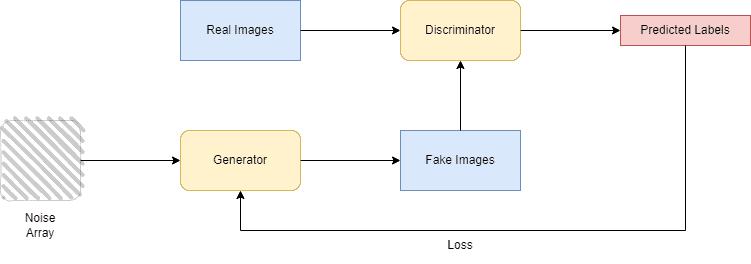
The discriminator’s purpose is to classify the images created by the generator and decide whether they are synthetic (fake), created by the generator, or original.
First of all, one of the key differences between VAEs and GANs lies in their training approach, as VAEs’ training follows an unsupervised approach in contrast with GANs that follow a supervised technique.
During their training phase VAEs aim to maximize the probability of the generated output with respect to the input and produce an output from a target distribution by compressing the input into a latent space. On the other hand, GANs try to find the balance point between the generator’s and discriminator’s two-player game in which the first tries to deceive the second one. In addition, VAE’s loss function is KL-divergence, while a GAN uses two loss functions, the generator’s and discriminator’s loss, respectively.
Moreover, VAEs are frequently simpler to train than GANs as they don’t need a good synchronization between their two components. Nevertheless, once this balancing is achieved, GANs are likely to recognize more complicated insights of the input and generate higher and more detailed plausible data than VAEs.
Furthermore, due to their superiority, GANs are used in more demanding tasks like super-resolution, and image-to-image translation, while VAEs are widely used in image denoising and generation.
VAEs are used in image generation, natural language processing, and anomaly detection. As they are able to learn complicated patterns of data, they can easily distinguish anomalies in it and identify potential frauds. They have also proven useful in medical datasets by detecting anomalies such as tumors and diseases.
On the other hand, GANs focus primarily on image generation by producing images that are identical to the original one with high resolution. They can also be useful in audio and text generation and create never before seen audio and text. Moreover, GANs are applicable in image editing and data augmentation.
In this article, we walked through VAE and GAN, a supervised and unsupervised framework for creating synthetic data from real. In particular, we focused on their different approach to image generation and discussed their main applications.