

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll walk through pooling, a machine-learning technique widely used that reduces the size of the input and, thus the complexity of deep learning models while preserving important features and relationships in the input data. In particular, we’ll introduce pooling, explain its usage, highlight its importance, and give brief examples of how it works.
2. What Are Pooling Layers?
Depending on the type of the pooling layer, an operation is performed on each channel of the input data independently to summarize its values into a single one and thus keep the most important features. These values are driven as input to the next layer of the model and so on. The pooling process may be repeated several times, and each iteration reduces the spatial dimensions. The value aggregation can be performed by using different techniques.
3. Types of Pooling Layers
There are many pooling operations and different extensions that have been developed to address specific challenges in different applications.
3.1. Max Pooling
Max pooling is a convolution technique that chooses the maximum value from the patch of the input data and summarizes these values into a feature map:
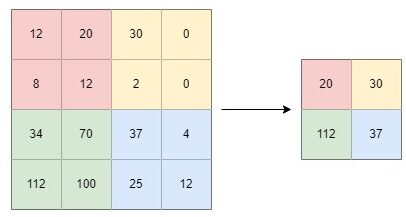
This method maintains the most significant features of the input by reducing its dimensions. The mathematical formula of max pooling is:

where  is the input,
is the input,  are the indices of the output,
are the indices of the output,  is the channel index,
is the channel index,  and
and  are the stride values in the horizontal and vertical directions, respectively, and the pooling window is defined by the filter size
are the stride values in the horizontal and vertical directions, respectively, and the pooling window is defined by the filter size  and
and  centered at the output index .
centered at the output index .
3.2. Average Pooling
Average pooling calculates the average value from a patch of input data and summarizes these values into a feature map:
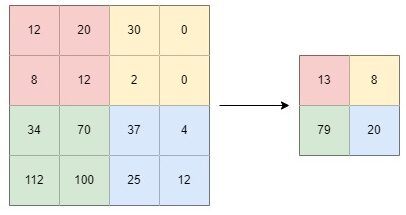
This method is preferable in cases in which smoothing the input data is necessary as it helps to identify the presence of outliers. The mathematical formula of average pooling is:

where is the input, are the indices of the output, is the channel index, and are the stride values in the horizontal and vertical directions, respectively, and the pooling window is defined by the filter size and centered at the output index .
3.3. Global Pooling
Global pooling summarizes the values of all neurons for each patch of the input data into a feature map, regardless of their spatial location. This technique is also used to reduce the dimensionality of the input and can be performed either by using the maximum or average pooling operation. The mathematical formula of global pooling is:

where is the input, is the channel index, and  is a function that aggregates the values in the feature map into a single value, such as average or max pooling, that was introduced before.
is a function that aggregates the values in the feature map into a single value, such as average or max pooling, that was introduced before.
3.4. Stochastic Pooling
Stochastic pooling is a deterministic pooling operation that introduces randomness into the max pooling process. This technique helps in improving the robustness of the model to small variations in the input data. The mathematical formula of stochastic pooling is:

where is the input, are the indices of the output tensor, is the channel index, and  is the probability of retaining the value at position in the input feature map. The probabilities are generated randomly for each pooling window and are typically proportional to the values in the window.
is the probability of retaining the value at position in the input feature map. The probabilities are generated randomly for each pooling window and are typically proportional to the values in the window.
4. Advantages and Disadvantages
In machine learning, pooling layers offer several advantages and disadvantages as well.
First of all, pooling layers help in keeping the most important characteristics of the input data. Furthermore, the addition of pooling layers in the neural network offers translation invariance, which means that the model can generate the same outputs regardless of small changes in the input. Moreover, these techniques help in reducing the impact of outliers.
On the other hand, the pooling processes may lead to information loss, increased training complexity, and limited model interpretability.
The main benefits and limitations are summarized in the table below:
| Advantages | Disadvantages |
|---|---|
| Dimensionality reduction | Information loss |
| Improved robustness | Difficulty in training |
| Translation invariance | Reduced interpretability |
5. Usages of Pooling Layers in Machine Learning
Pooling layers play a critical role in the size and complexity of the model and are widely used in several machine-learning tasks. They are usually employed after the convolutional layers in the convolutional neural network’s structure and are mainly used for downsampling the output.
These techniques are commonly used in convolutional neural networks and deep learning models of computer vision, speech recognition, and natural language processing.
6. Conclusion
In conclusion, pooling layers play a critical role in reducing the size and complexity of deep learning models while preserving important features and relationships in the input data.
In this article, we walked through pooling layers, a powerful and widely used technique in machine learning that offers many advantages for a wide range of applications. In particular, we introduced pooling layers, mentioned the most common pooling techniques, and summarized their main benefits and limitations.