

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Attention Mechanism in the Transformers Model
Last updated: August 9, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
The transformer model is a neural network architecture that made a radical shift in the field of machine learning. When writing this article, transformer variants have long dominated popular performance leaderboards in almost every natural language processing task. What is more, recent transformer-like architectures have become the state of the art in the computer vision field as well.
The paper that introduced transformers back in 2016 included information about several other important techniques that go along with the architecture, like positional encoding and masking.
However, in this tutorial, we’re going to focus on the main thing that made the architecture so successful – its self-attention mechanism.
2. What Is Attention?
Attention, in general, refers to the ability to focus on one thing and ignore other things that seem irrelevant at the time. In machine learning, this concept is applied by teaching the model to focus on certain parts of the input data and disregard others to better solve the task at hand.
In tasks like machine translation, for example, the input data is a sequence of some text. When we humans read a piece of text, it seems natural to attend to some parts more than others. Usually, it’s the who, when, and where part of a sentence that captures our attention.
Since this is a skill we develop from birth, we don’t acknowledge its importance. But without it, we wouldn’t be able to contextualize.
For instance, if we see the word bank, in our heads, we might think about a financial institution or a place where blood donations are stored, or even a portable battery. But if we read the sentence ” I am going to the bank to apply for a loan”, we immediately catch up on what bank is mentioned. This is because we implicitly attended to a few clues. From the “going to” part, we understood that a bank is a place in this context, and from the “apply for a loan” part, we got that you can receive a loan there.
The whole sentence gives out information that adds up to create a mental picture of what a bank is. Suppose a machine could do the same thing as go as we do. In that case, most of the significant natural language processing problems like words with multiple meanings, sentences with multiple grammatical structures, and uncertainty about what a pronoun refers to will be solved.
3. A Primer on Transformers
While far from perfect, transformers are our best current solution to contextualization. The type of attention used in them is called self-attention. This mechanism relates different positions of a single sequence to compute a representation of the same sequence. It is instrumental in machine reading, abstractive summarization, and even image description generation.
Since they were used initially for machine translation, the Transformers are based on the encoder-decoder architecture, meaning that they have two major components. The first component is an encoder which takes a sequence as input and transforms it into a state with a fixed shape. The second component is the decoder. It maps the encoded state of a fixed shape to an output sequence. Here is a diagram:
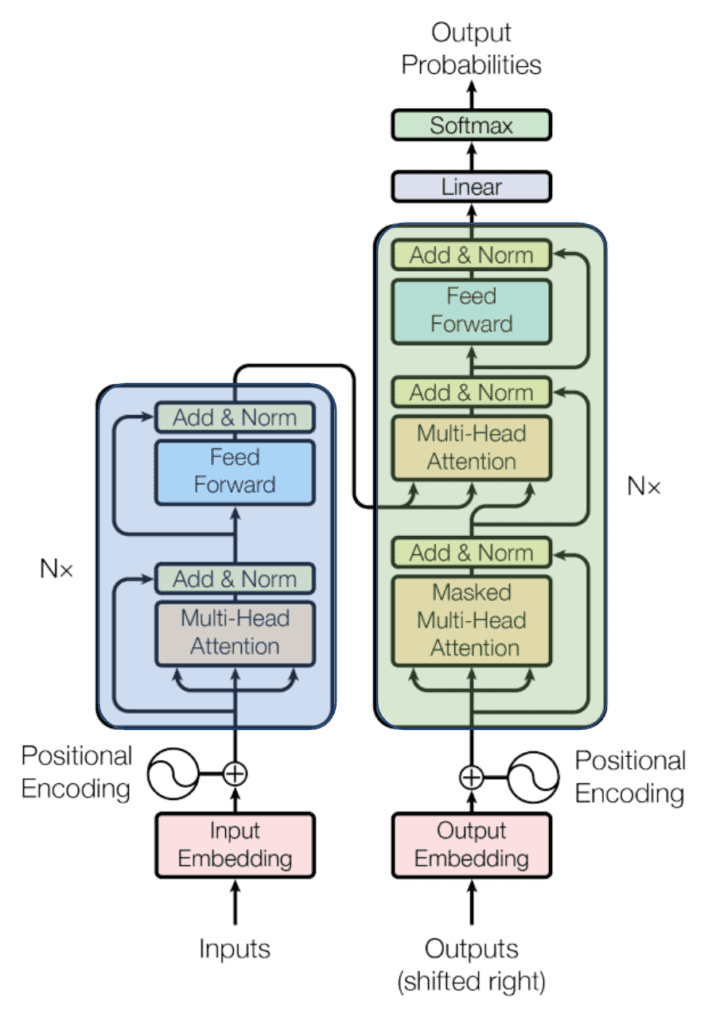
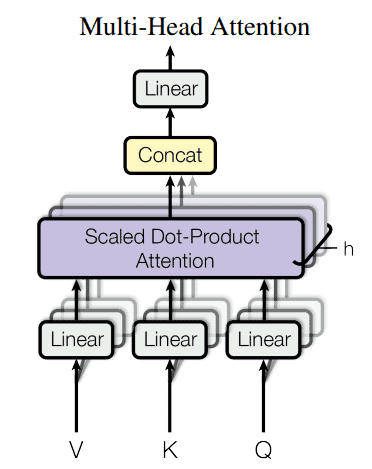
A lot is going on in the diagram, but for our purposes, it’s only worth noticing that the encoder module here is painted in blue while the decoder is in green. We can also see that both the encoder and decoder modules use a layer called Multi-Head Attention. Let’s also forget about the multi-headed part for now and focus only on what is inside one “head”.
The main component is called scaled dot-product attention and it’s very elegant in that it achieves so much with just a few linear algebra operations. It’s made up of three matrices,  ,
,  , and
, and  , which are called a query, key, and value matrices and each has a dimension of
, which are called a query, key, and value matrices and each has a dimension of  .
.
The concept of using queries, keys, and values is directly inspired by how databases work. Each database storage has its data values indexed by keys, and users can retrieve the data by making a query.
The self-attention operation is very similar, except that there isn’t a user or a controller issuing the query, but it’s learned from the data. By the use of backpropagation, the neural network updates its Q, K, and V matrices in order to mimic a user-database interaction. To prove that this is possible, let’s reimagine the retrieval process as a vector dot product:
![\[\vec{\alpha} \cdot \vec{v}\]](/wp-content/ql-cache/quicklatex.com-970c7af2fc77d26e2abf9ea99470546b_l3.svg "Rendered by QuickLaTeX.com")
where  is a one-hot vector consisting of only ones and zeroes, and
is a one-hot vector consisting of only ones and zeroes, and  is a vector with the values we’re retrieving.
is a vector with the values we’re retrieving.
In this case, the vector alpha is the de facto query because the output will consist only of the values of where is 1:
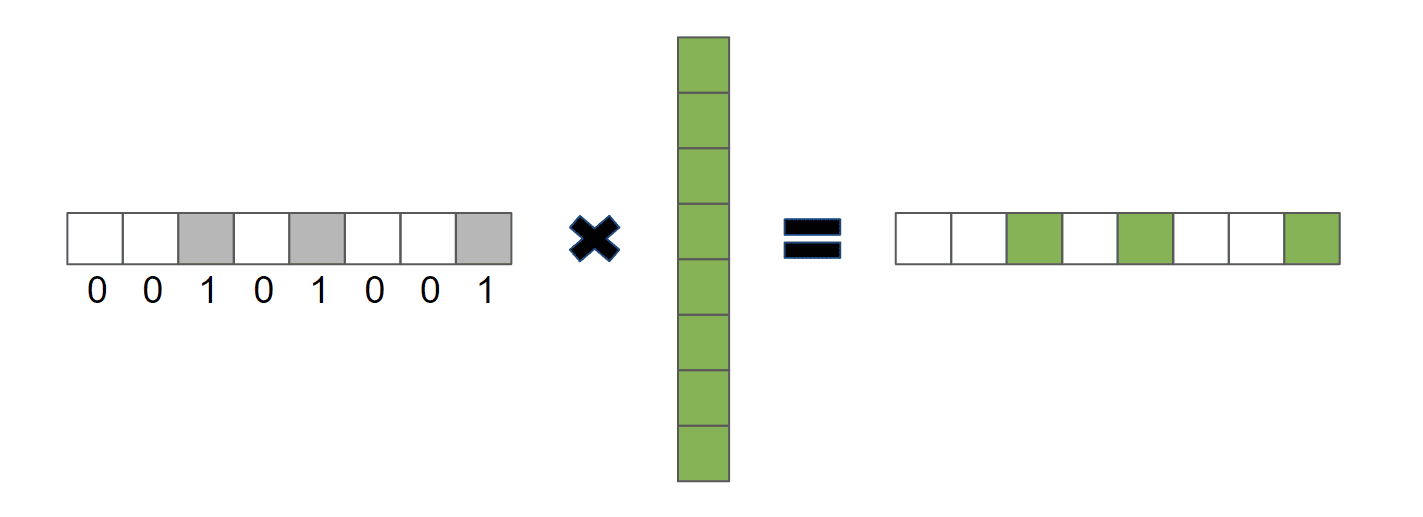
Now let’s remove the restriction for the query vector and allow float values between 0 and 1. By doing that, we would get a weighted proportional retrieval of the values:
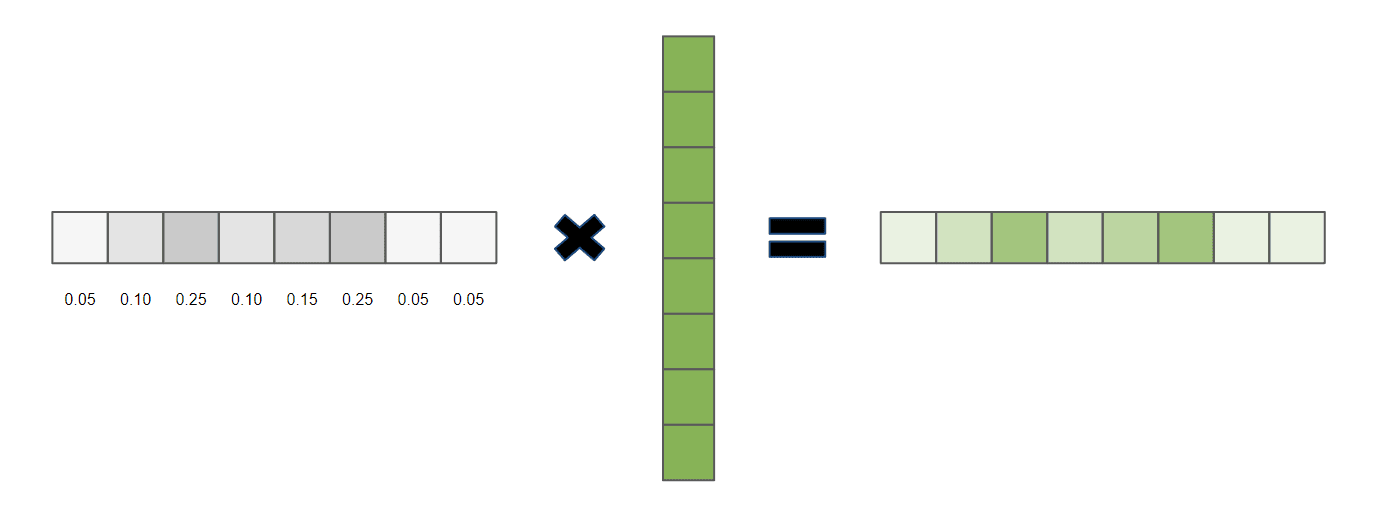
The scaled dot product attention uses vector multiplication in the same exact way. To obtain the final weights on the values, first, the dot product of the query with all keys is computed and then divided by  . Then a softmax function is applied.
. Then a softmax function is applied.
In practice, however, these vector multiplication happen simultaneously because the query keys and values are packed together into matrices, as already mentioned. The final computation is, therefore:
![\[\operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V\]](/wp-content/ql-cache/quicklatex.com-7dafb63f5ad61abbe87e8d7fb85a84f2_l3.svg "Rendered by QuickLaTeX.com")
The formula can also be viewed as the following diagram:
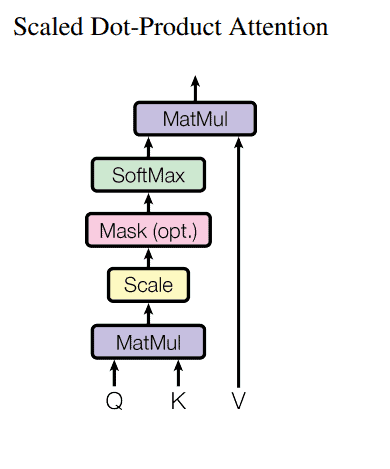
But there is more.
Why would we limit the model to learning just one type of relationship? What we can do is have multiple different sets of key, query, and value matrices. That way, each attention module can focus on calculating different types of relationships between the inputs and create specific contextualized embeddings. As shown in the diagram above, these embeddings can then be concatenated and put through an ordinary linear neural network layer, together making the final output of the so-called Multi-Headed Attention Module.
As it turns out, this approach not only improves the model’s performance but improves training stability as well:
4. Conclusion
In this article, we looked into arguably the most important part of the famous transformer architecture – the attention module. We glimpsed how it uses concepts from retrieval systems to effectively learn long-distance relationships and do something very close to what we humans do when it comes to working with natural text or any other sequence of data.