

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll define faults and failures in distributed systems and discuss how to mitigate them.
Formally speaking, a distributed system is a set of physically separated and interconnected devices that collaborate over a network to achieve a shared task, such as providing a service. Although the devices are independent, with their memory and resources, they appear as a single system to the end user.
We always characterize distributed systems by their high-level complexity because of their large number of components and their use of different hardware and software platforms. This complexity makes them prone to many issues. Typically, we find three types of issues that can emerge in a distributed system: fault, error, and failure:
The three concepts above are interrelated, as depicted in the following figure:
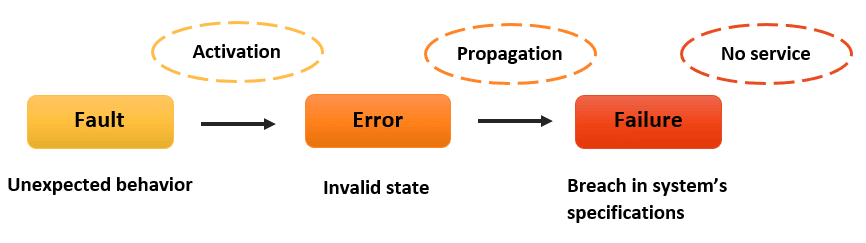
A failure in one node can spread throughout the network, affecting other nodes and potentially resulting in a chain of failures and even the entire system breakdown. Therefore, it’s crucial to ensure the system continues operating even when faults exist. This is achieved by first understanding the types and categories of possible faults in order to design systems that tolerate them. Then, we need to be aware of potential ways our system can fail to anticipate and plan for the failure scenarios.
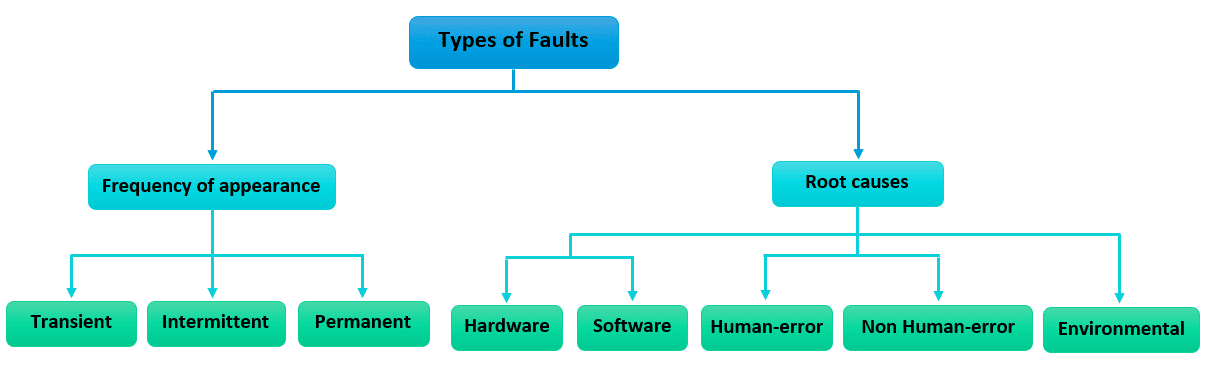
We can classify faults by their frequency of appearance into transient, intermittent, and permanent faults. Transient faults happen once and disappear, while intermittent faults appear and disappear repeatedly. As for permanent faults, they appear and remain until they’re fixed.
Transient faults and intermittent faults are very hard to locate, yet they’re not of much danger to our system. For example, network problems and media issues are transient faults, while a computer that stops operating or a loose contact on a connector are intermittent faults. When it comes to permanent faults, they’re easy to locate but can cause significant harm to our system. We give examples of burnt-out chips, software bugs, and disk head crashes.
Furthermore, we can group faults according to the types of root causes to better understand them. First, software errors like data corruption or hanging processes and hardware errors like insufficient disk space. Next, there are faults resulting from human errors like coding mistakes and non-human errors such as power outages. Finally, there are faults caused by external environmental perturbations, such as an earthquake happening in servers’ geographical location.
Tolerating faults, or fault tolerance, is the ability to persist in proper functioning even when faults exist. It’s one of the basic requirements we must consider when designing a distributed system. That said, fault tolerance will provide four features for these systems: availability, reliability, safety, and maintainability.
So, how can we tolerate faults? There is a set of available mechanisms we can use based on the encountered fault type:
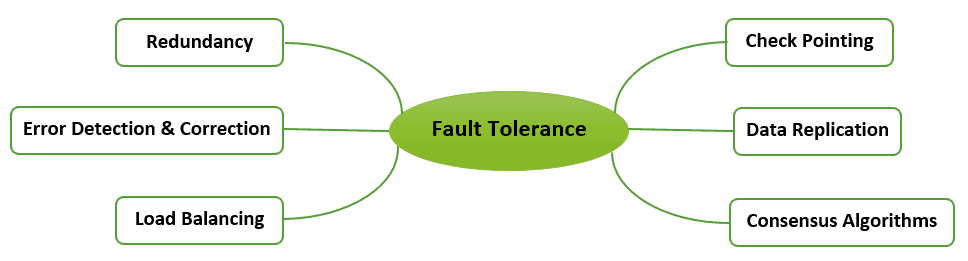
Data replication is making several copies of data and storing them at different locations. The objective is to guarantee data availability even when some nodes fail. A major issue in data replication is data consistency.
A checkpoint is a set of information defining a system in a consistent state that’s saved in a safe location. This information includes environment, process state, active registers and variables, etc. Whenever the system breaks down, we restore it to a recently created checkpoint. Although it benefits us by saving computational power, it’s time-consuming.
Redundancy refers to having backup systems or components, such as databases or servers, take over when other components fail. Primarily, it increases the system’s reliability.
Data corruption is a potential fault when transmitting data due to several causes, such as noise or cross-talk. Error detection helps recognize such corruptions using several mechanisms, namely parity bits, checksum, hamming code, and cyclic redundancy checks (CRC).
This process includes distributing traffic among nodes. More specifically, if a node fails or gets overloaded, we can redirect the traffic to another functioning node to prevent a single failure from harming the entire system.
Consensus algorithms enable distributed systems to agree on the sequence of operations and guarantee data accuracy even with a component failure or a network partition. For example, we can use methods such as Paxos and Raft.
We define safe failure as the property of not causing damage in the occurrence of a failure. Handling failures properly in a distributed system requires first detecting them and then recovering from them.
Detecting failures means knowing which component and how it has failed. Failure models help us illustrate how a system could fail. Typically, we find five models in distributed systems:
| Failure model | Description |
|---|---|
| Timing failure | A system’s component transmits a message way before or after the expected time interval. |
| Omission failure | A message that never seems to be transmitted. We call it also an “infinitely late” timing failure. It takes two forms, send omission and receive omission failures. |
| Crash failure | A component faces an omission failure and then quits replying entirely. |
| Response failure | A component delivers an erroneous response, whether by giving an incorrect value or transferring it through a wrong control flow. |
| Arbitrary failure | A component generates random responses at random times. It’s the worst failure scenario, known also as a byzantine failure, because of its behavior’s inconsistency. |
A common way to build fail-safe systems is to resolve the failure by finding the faults roots causing it and tolerate them. Fault Tree Analysis is an example of a technique used to identify combinations of faults and errors that caused the failure.
In this tutorial, we discussed fault tolerance mechanisms and failure models in a distributed system. Fault and failure terms are frequently used interchangeably. Generally, the former refers to problems perceived by developers while the latter presents problems seen by customers or end users. A fault doesn’t always lead to a failure, but a failure can only happen if there is a fault. Hence, a fault is a state, and a failure is an event.