

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll examine the importance of consensus algorithms in distributed systems. It requires us to understand the implications of choosing a particular algorithm. In the process, we’ll also discuss the board classification of consensus algorithms and some of them in detail.
Let’s begin by defining consensus. It refers to an agreement on any subject by a group of participants. For example, a bunch of friends deciding which café to visit next is an agreement. On a different scale, citizens of a nation electing a government also constitutes an agreement. Of course, the methods we choose to reach the agreement are different in each case.
Fundamentally, the term has a similar meaning for the world of computer science. A complex system can consist of multiple processes that work independently and often in a distributed setup. To achieve a common objective, they have to agree on several decisions.
For instance, which transactions to commit to the database and in which order:
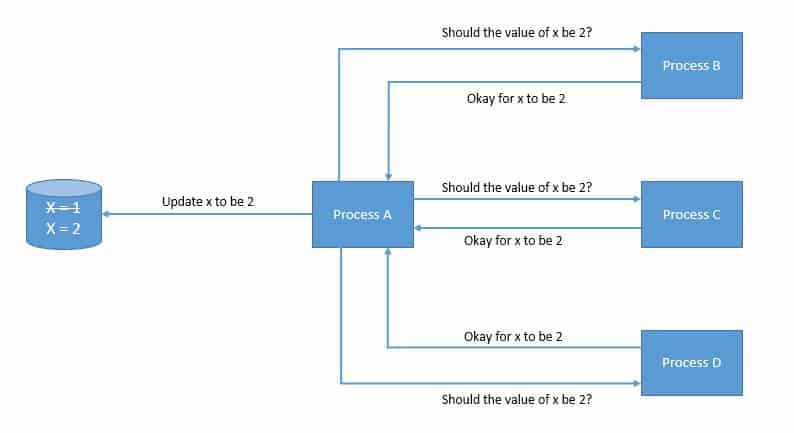
The problem is compounded by the fact that some of these processes can fail randomly or become unreliable in many other ways. However, the system as a whole still needs to continue functioning. This requires the consensus mechanism we choose to be fault-tolerant or resilient. Hence, the choice of protocol to solve the consensus problem is guided by the faults it needs to tolerate.
We expect a consensus algorithm to exhibit certain properties:
There are many ways in which processes in a distributed system can reach a consensus. However, there is usually a constant struggle between security and performance. The more we want our algorithm to be secure against ways in which failure can happen, the less performant it tends to become. Then, there are considerations like resource consumption and the size of messages.
Consensus algorithms for distributed systems have been an active area of research for several decades. Possibly, it started in the 1970s, when Leslie Lamport began reasoning about the chaotic world of distributed systems. It led to the development of several key algorithms, which remain a milestone in the family of classical consensus algorithms.
However, the turn of the Millennium brought new technologies like blockchain. This propelled the world of distributed computing to an unimaginable scale. It led to the development of numerous tailor-made consensus algorithms. To make sense of this, it’s quite useful to understand the computation model in which the consensus algorithms are expected to operate.
As we’ve seen earlier, distributed systems are prone to faults that a consensus algorithm needs to be resilient against. Now, it’s important to understand the types of faults a process may undergo. There are several types of failures, like crash failures and byzantine failures.
A crash fault occurs when a process abruptly stops and does not resume. On the contrary, a Byzantine fault is much more arbitrary and disruptive. It may occur for several reasons, like malicious activity on the part of an adversary. For instance, when members send conflicting views of reality:
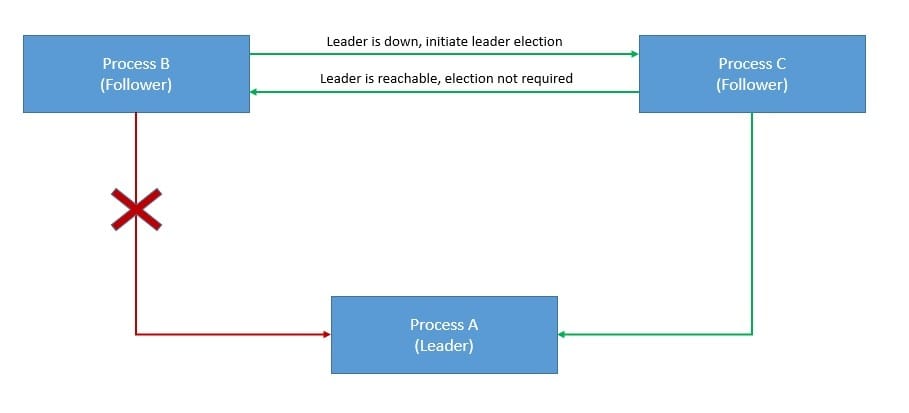
The Byzantine failure derives its name from the “Byzantine generals problem”. It’s a game theory problem that describes how actors in a decentralized system arrive at a consensus without a trusted central party. Some of the actors here can be unreliable.
Interestingly, in case of a Byzantine failure, a process can inconsistently appear both failed and functioning to the rest of the system. Hence, it becomes much more challenging for a consensus algorithm to be resilient to Byzantine failures than crash failures.
Another important aspect of the computation model is how processes communicate with each other. A synchronous system is where each process runs using the same clock or perfectly synchronized clocks. This naturally puts an upper bound on each processing step and message transmission.
However, in a distributed system, communication between processes is inherently asynchronous. There is no global clock nor consistent clock rate. Hence, each process handles communication at different rates, thus making the communication asynchronous:
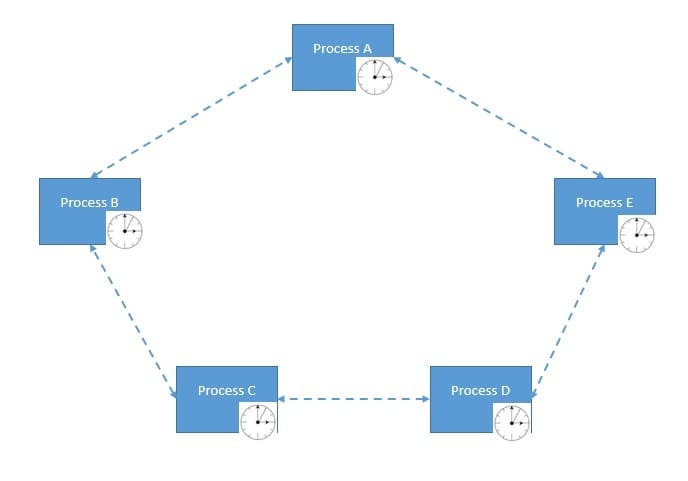
The famous FLP Impossibility Theorem, accredited to Fischer, Lynch, and Paterson, has proved that in a fully asynchronous distributed system where even a single process may have a crash failure, it’s impossible to have a deterministic algorithm for achieving consensus.
Another important consideration of the computation model is the topology of the system itself. By definition, a permissioned network is a closed one. Here, participating processes are fixed and given at the outset, and participants can authenticate each other as group members.
On the contrary, a permissionless network allows anyone to join dynamically and participate without prior permission. Typically, such networks impose some barrier to mitigate the Sybil attack. Sybil attack refers to gaining influence in a network through many pseudonymous identities:
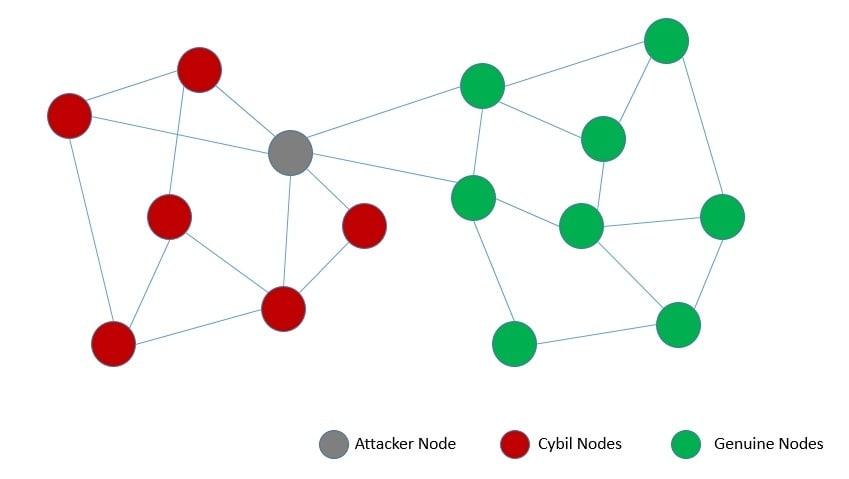
It’s noteworthy that even a sophisticated consensus algorithm created for the permissioned network would fail in a permissionless network. It requires more careful considerations to avoid the Sybil attack on top of all existing considerations for the permissioned network.
As the consensus in distributed systems has widened significantly, it’s important to draw some broad categories to understand them better. Some of the earliest implementations of consensus algorithms started to use different voting-based mechanisms.
These provide reasonable fault tolerance and have strong mathematical proofs to ensure security and stability. However, the very democratic nature of these algorithms makes them incredibly slow and inefficient, especially as the network grows larger.
Practical Byzantine Fault Tolerance (pBFT) is a consensus algorithm proposed by Barbara Liskov and Miguel Castro back in 1999 as a practical solution to the Byzantine general’s problem in distributed systems. It works by providing a practical Byzantine state machine replication with a voting mechanism when the state changes.
The algorithm works on the condition that the maximum number of faulty nodes must not be greater than or equal to one-third of all nodes in the system. The nodes are sequentially ordered, with one node designated as the primary and the others being secondaries.
Now, the algorithms divide the core consensus rounds into three phases:
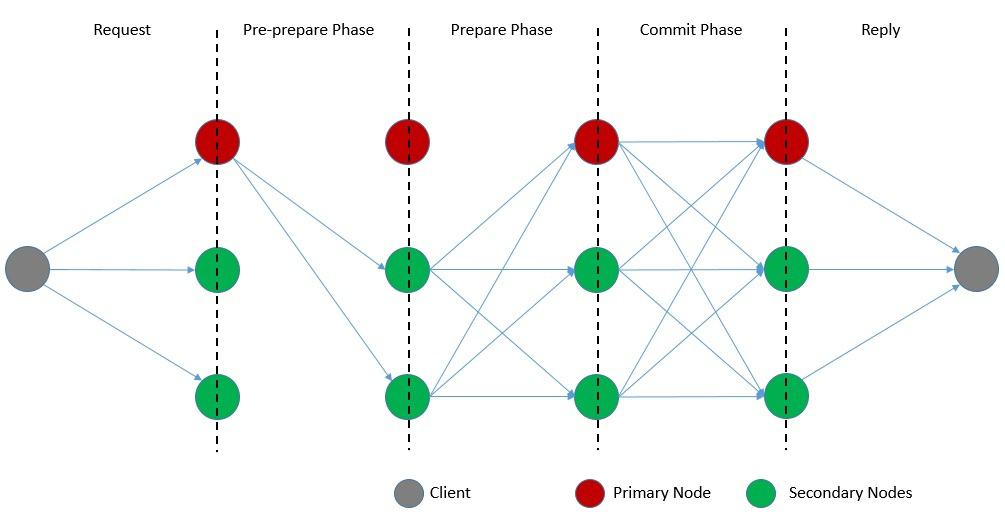
It begins when a client sends a request to begin a transaction. The primary broadcasts “pre-prepare” messages to all the secondaries. Then, the secondaries start to send the “prepare” messages. Every node receiving a threshold of “prepare” messages starts to send “commit” messages. Finally, on receiving a threshold of “commit” messages, nodes execute the state transition and respond back to the client.
Interestingly, the algorithm changes the primary node in every consensus round. This is referred to as view change and follows a separate process other than the primary process. Overall, the algorithm is quite efficient with optimizations for low overhead time. However, it does suffer from limitations like susceptibility to the Sybil attacks, and restrictions in terms of scalability.
HotStuff is another leader-based Byzantine fault-tolerant replication protocol. It was proposed by VMware research in their paper, back in 2018. It’s very similar to pBFT in the environment it operates in and the objectives it serves. However, it tries to improve upon the shortcomings of pBFT, especially with the complex peer-to-peer communication and the view change process for leader reelection.
The pBFT performs two rounds of peer-to-peer message exchange to achieve consensus. HotStuff proposed to replace this with all messages flowing through the primary. Also, pBFT has a separate view change process. HotStuff proposed simplifying this by merging the view change process with the normal process. These changes resulted in different phases in a HotStuff consensus round:

The algorithm begins with the primary collecting the “new view” messages from enough secondaries. Then, it starts a new view and sends the “prepare” message to other nodes. On receiving “prepare” votes, the primary creates and ends the “pre-commit” messages to all nodes. On receiving “pre-commit” votes, the primary creates and sends the “commit” messages.
Finally, on receiving enough “commit” votes, the primary creates and sends the “decide” messages to all nodes. On receiving the “decide” message, secondaries execute the state transition. Now, HotStuff also adds other improvements, like threshold signature and pipelining of the consensus phases. However, it still suffers from the limitations of scaling arbitrarily.
While we’ve focused only on Byzantine fault-tolerant consensus protocols, there are other voting-based consensus algorithms that only address crash failures. Some of the popular algorithms for networks with known participants include Paxos and Raft. Paxos was originally proposed by Leslie Lamport in 1989. Raft was introduced by Diego Ongaro in 2014 as a simpler version of Paxos.
Then, there is also a family of distributed hash table protocols that address networks with unknown participants and limited attack modes. One of the earliest such algorithms was Chord, introduced in 2001 by Ion Stoica et al. Other notable peer-to-peer distributed hash table protocols proposed were CAN, Tapestry, and Pastry. It’s difficult to cover them in detail here.
For Byzantine fault tolerance there are notable efforts other than the ones we’ve discussed. For instance, several variants for pBFT have been proposed, like RBFT, Q/U, Adapt, Zyzzyva, and Aardvark. Interestingly, there were also efforts to Byzantizing Paxos by Refinement! As it’s apparent, even today, this remains a large area of academic research.
The advent of blockchain technology and distributed ledgers presented far larger and permissionless networks. A proof-based consensus algorithm was more suited for these conditions. Here, a participant needs to provide sufficient proof of something to be able to contribute to decision-making.
There have been several proof-based algorithms have been proposed over time, and they all have their pros and cons. Many have been proposed to cover one or the other drawbacks of the original work, like security, fairness, efficiency, and resource footprint.
Proof-of-Work (PoW) refers to cryptographic proof in which one party proves to other parties that a specific computational effort has been expended. Others here can subsequently verify the proof with minimal effort on their part. The concept was originally proposed by Moni Naor and Cynthia Dwork in 1993 to deter attacks like denial-of-service.
This concept was first used by Satoshi Nakamoto in 2008 to build a consensus protocol for Bitcoin, a permissionless decentralized network. The Nakamoto Consensus, as it’s popularly known, proposed that the nodes compete to solve a cryptographic puzzle, and the winner is accepted as valid across the network. The winner is also rewarded for their effort:
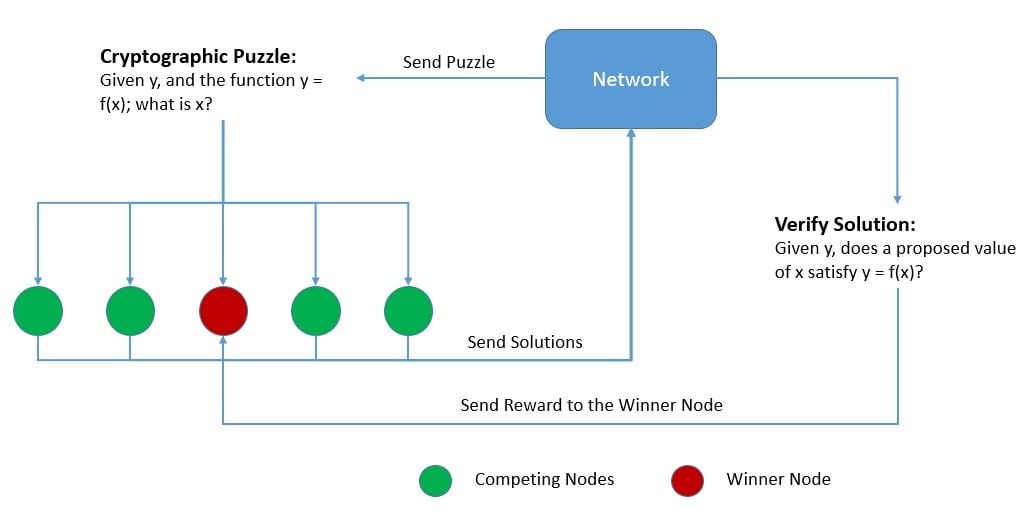
Bitcoin uses the Hashcash Proof-of-Work system, which was proposed by Adam Back in 1997. We can summarize the puzzle it employs as – “Given data A, find a number x such that the hash of x appended to A results in a number less than B“. The only way to solve this is brute force and the premise is that only honest nodes would spend the effort to do so.
Compared to other Byzantine fault-tolerant consensus protocols, a Proof-of-Work based consensus protocol scales much better as it does not require a rotating election of leaders through a voting mechanism. However, nodes have to spend a lot of energy generating proof-of-work, which increases significantly as the network grows.
While Bitcoin spearheaded the adoption of consensus mechanisms based on the Proof-of-Work, soon, a growing number of blockchains were working on top of it. It started a global debate on the energy footprint of these networks as a larger user base started to participate actively. Soon, these networks started to look for alternate consensus protocols.
Proof-of-Stake (PoS), as the name suggests, is a mechanism where a participating node has to stake something valuable to the network, like a certain amount of cryptocurrency. The stake makes it a candidate in a larger pool, from which a fair algorithm picks the node entrusted with the task. If the task performed by the node is verified by other nodes, it gets back its stake along with the reward:
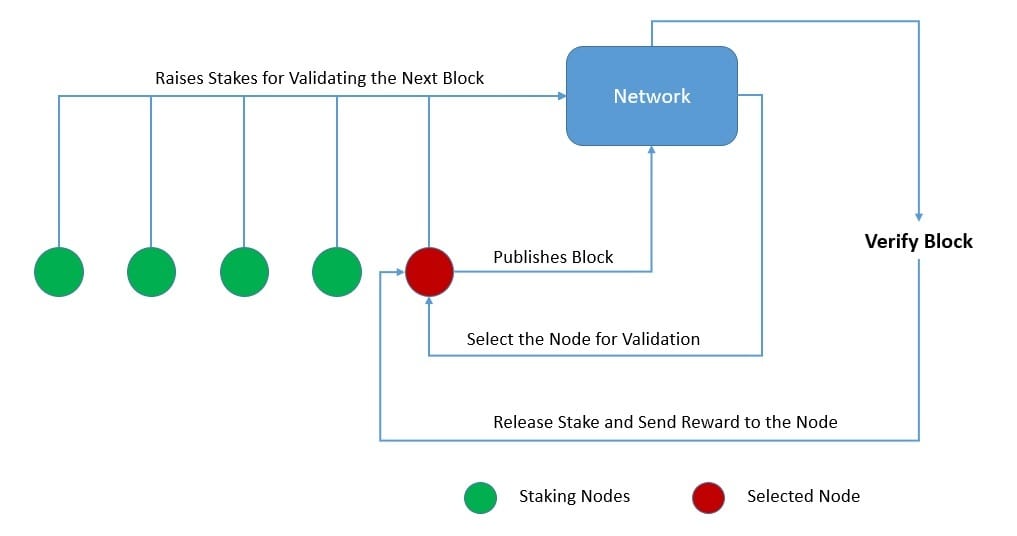
The stake here is collateral, as it can also be destroyed for misbehaving nodes! The nodes are not competing to solve some complex puzzle. Hence, it results in an energy-efficient mechanism. There are other advantages of such algorithms as well. For instance, it promotes decentralization, leads to a more secure network, and has lower barriers to entry.
Networks based on proof-of-stake still share some of the problems with proof-of-work. For instance, both are susceptible to the threat of a 51% attack, an attack possible by owning 51% of the nodes in a network. Nevertheless, Ethereum, a popular blockchain, recently completed “The Merge“, which upgraded from the original proof-of-work mechanism to the proof-of-stake mechanism.
While proof-of-work and proof-of-stake remain the basis for several proof-based consensus algorithms, there have been numerous other variants proposed over time. Many of them address the drawbacks of these fundamental algorithms and also propose using hybrid forms. But quite a few of them also try to address issues specific to a problem domain, like applications requiring low latency.
There are several other types of proof-based algorithms that have been proposed over time. For instance, “proof of burn”, “proof of space”, “proof of authority”, and “proof of elapsed time” to name a few. It’s difficult to cover them all, but the fundamental premise remains the same. A node interested in decision-making must provide sufficient proof of value to deter Sybil attacks.
As permissionless networks, like blockchain, are becoming more widespread and complex, these simpler consensus protocols are facing newer challenges. This is driving effort for developing hybrid consensus protocols that derive the benefits of both worlds. For instance, Tendermint, introduced by Jae Kwon in 2014, combines proof-of-stake with a variant of pBFT to achieve consensus.
In this tutorial, we understood why consensus algorithms play a significant role in a distributed system. Moreover, we went through different computing models where these algorithms are expected to work. Finally, we discussed some of the popular voting-based and proof-based consensus algorithms.