

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss the lifecycle of a process in an operating system.
In an operating system, a process is an instance of a computer program that is currently being executed. So a computer program that has an active status is a process. For example, a user is opening a web browser for web surfing or playing music using some music player application.
When we want to run more than one process simultaneously, the processes are executed in a sequential fashion. For example, let’s have four processes  .
.
Let’s see the conceptual model of process execution:
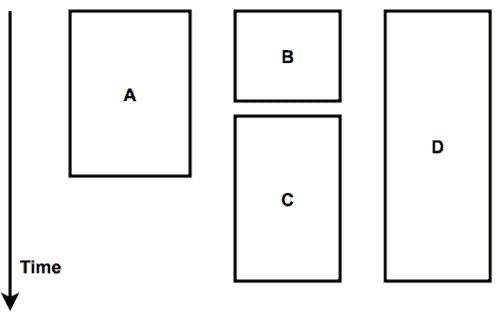
Here the size of the box of a process represents the execution time of the process. The OS starts executing the processes from left to right according to the execution time and the start time of the process:
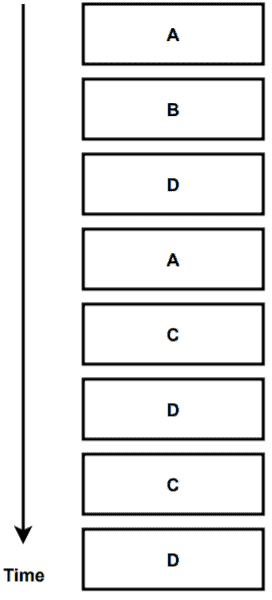
One important point to note before we move forward is that a process and a program are not the same. A program is an executable text file stored in the memory of an operating system. When we execute the text file, it becomes a process. A program contains some commands and instructions which are written to perform some specific tasks. A process is actually executing those tasks in the operating system.
Another fundamental difference between a process and a program is that multiple users can run the same program with the same text, but each execution of the program file creates a distinct process with a unique process ID.
When a program is executed by a user, it becomes a process and loaded into the main memory of an operating system. Inside the main memory, an implied process layout has four parts: stack, heap, data section, and text section. Each section includes some information corresponding to a process:
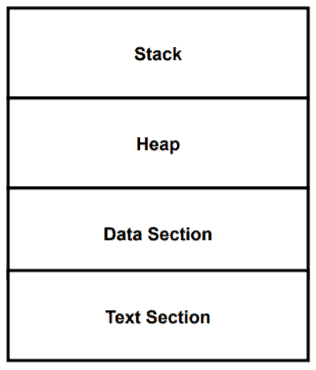
The stack stores temporary data, such as local variables and function parameters. During the runtime of a process, it needs memory. Heap is dynamically allocated memory to a process. The data section stores initialized global and static variables. The text section contains the compiled program codes.
A process contains various attributes. These attributes are stored in a process control block (PCB), also known as a task control block. Some of the important attributes are process ID, process state, CPU scheduling information, I/O information, accounting information, memory management information, etc.
Every process can be identified uniquely with a process ID. It helps to distinguish one process from another. During the whole runtime, each process has some states associated with it at a particular instant of time. Process state displays the state of a process at a particular runtime.
Each operating system may use a different scheduling algorithm. The OS executes the processes according to the scheduling algorithm. CPU scheduling information contains information about the scheduling currently being used by the operating system. Each process needs some I/O devices for its execution. The details of the I/O devices are stored in the I/O information attribute.
While a process is executed, it is crucial to know accounting-related information like the amount of CPU used for process execution, execution ID. A process also contains information about the memory management of the OS.
When a user executes a process, it goes through several phases before termination. These phases may vary from OS to OS. Common process lifecycles can have two, five, or seven states.
The simplest process lifecycle model consists of only two states: running and not running. So in this model, either a process is running on the CPU or not running:
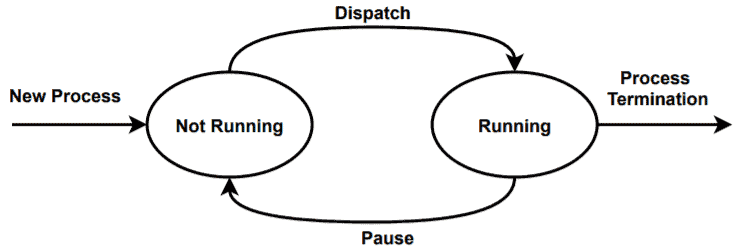
When a new process is created, the process goes into the not running state. Initially, the process is stored in a program called the dispatcher. When the dispatcher realizes that the CPU is free, it allows the process to move to the CPU. When the dispatcher allows the process to use CPU, the process goes to the running state.
When the CPU is free, the CPU scheduler is responsible for selecting a process and send it to the CPU. The CPU scheduler picks the processes according to the scheduling scheme used by the operating system.
The five-state process lifecycle is the extended version of the two-state model. The two-state model works efficiently when all the programs that are in the not running stage, ready for execution. But in some operating systems, some processes may not be ready to go to the running state due to the non-availability of some I/O operations. Such problems can be solved by splitting the not running states into two states:
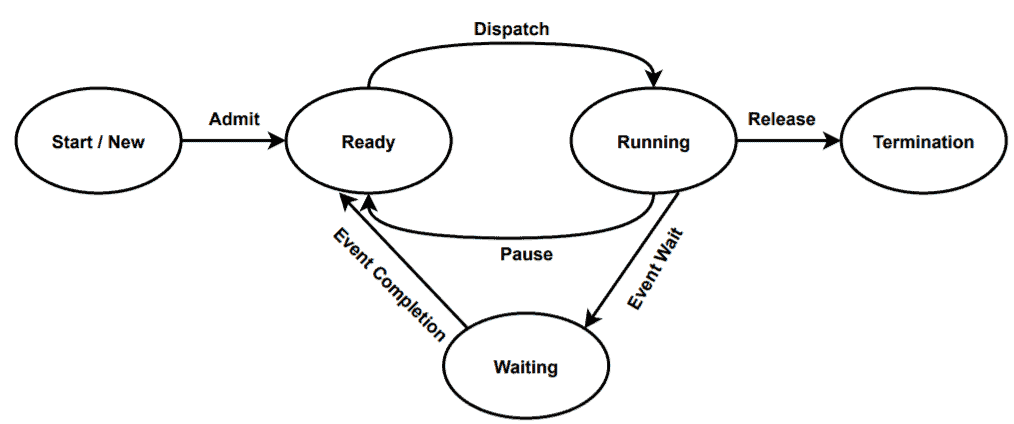
The start or new state represents that the process is just being created. The program is in the dispatcher and waiting to be moved into the main memory. As soon as the process moves into the main memory, it changes the state from start to ready.
When a process is in the main memory and waiting for the CPU, it’s in the ready state. When the CPU becomes free, the process moves into the CPU for further execution.
If a process is in the running state, then it’s currently being executed in the CPU.
After completing the execution in the CPU, a process may not goes to the termination stage. Instead, it may wait for the completion of some I/O operations, or synchronization signal, etc. In such cases, the process moves to the waiting stage. When the CPU becomes free again, the process goes to the ready state. From the ready state, the process reaches the running state.
Finally, when a process has finished its execution or may be aborted by the user for some reason, it goes to the termination stage.
An extended version of the five-state model is the seven-state model. There are two new states added in this model: suspend ready and suspend wait. Let’s see the state diagram:
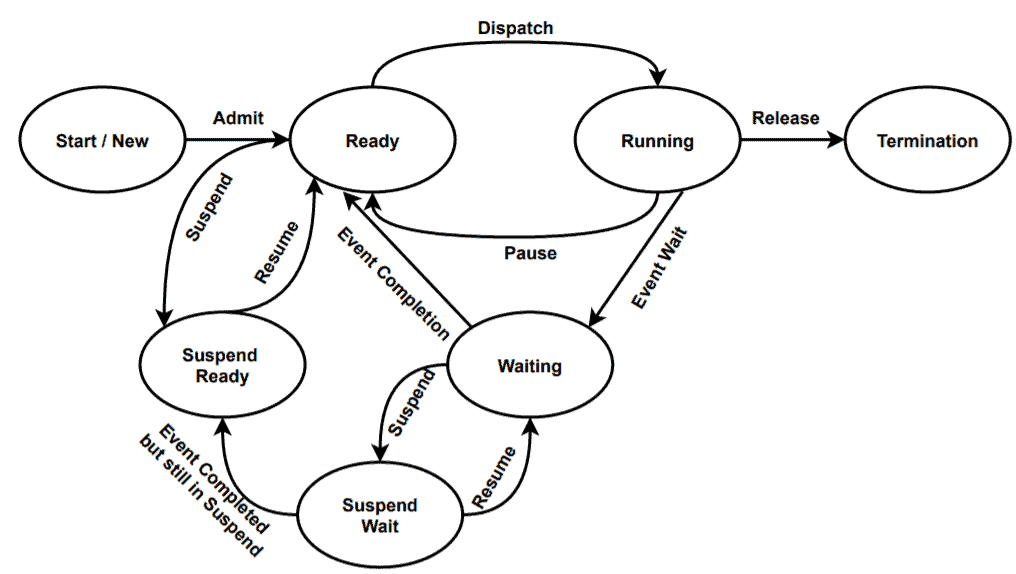
Sometimes processes that are in the ready state may get swapped from the main memory, and the CPU scheduler moves the processes into external storage with a status of suspending ready. The processes can transit back to the ready state whenever the processes are moved into the main memory.
Processes that are in the waiting state may be moved into secondary storage due to the lack of main memory. The processes then landed in the suspend wait stage. From this stage, a process can either go back to the waiting stage, or it can go to the suspend ready stage.
In this tutorial, we learned the lifecycle of a process in an operating system. We presented three process lifecycle models with a detailed description.