

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll understand the basics of distributed systems. This article will cover the basic characteristics of them and the challenges they present along with the common solutions.
We’ll also briefly cover the approach taken by some of the popular distributed systems across multiple categories.
Before we understand the distributed architecture of different systems, let’s first clear some of the fundamentals.
Even though the motivation largely influences a distributed architecture, there are some basic principles and challenges that apply to all of them.
So, let’s begin by formally defining a distributed system. A distributed system consists of multiple components, possibly across geographical boundaries, that communicate and coordinate their actions through message passing. To an actor outside this system, it appears as if a single coherent system:
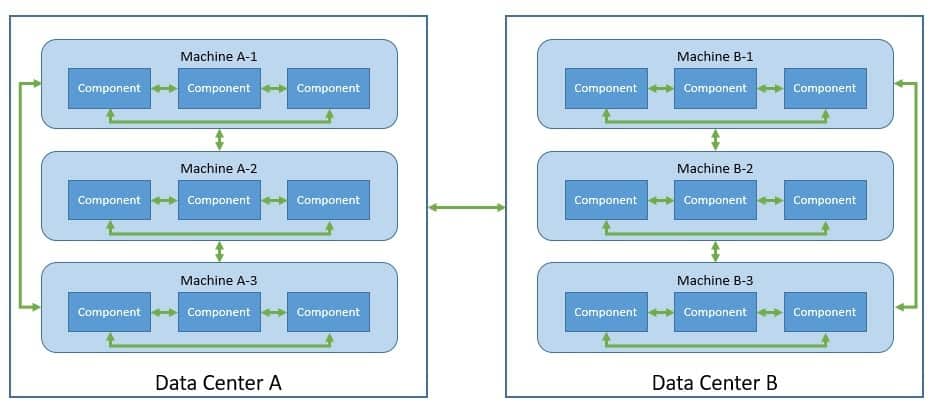
Now we may often hear about decentralized systems and confuse them with distributed systems. So, it’s imperative to make some distinctions. Decentralized systems are distributed systems where no specific component owns the decision making. While every component owns their part of the decision, none of them have complete information. Hence, the outcome of any decision depends upon some sort of consensus between all components.
Another term that is very closely related to distributed systems is parallel systems. While both the terms refer to scaling-up the computational capability, the way they achieve them is different. In parallel computing, we use multiple processors on a single machine to perform multiple tasks simultaneously, possibly with shared memory. However, in distributed computing, we use multiple autonomous machines with no shared memory and communicating with message passing.
While distributed systems are definitely more complex to design and build, it pays off the benefits they bring along.
Let’s quickly go through some of the key benefits:
If we think that we get all the benefits of a distributed system without any challenges, we can not be far from reality!
Let’s understand some of the key challenges a distributed system presents to us:
Often in enterprise applications, we require multiple operations to happen under a transaction. For instance, we may need to make several updates to data as a single unit of work. While this has become trivial when the data is colocated, it becomes quite complex when we distribute data over a cluster of nodes. Many systems do provide transactions like semantics in a distributed environment using complex protocols like Paxos and Raft.
Although the interest in distributed systems has seen a resurgence in recent times, the basic fundaments aren’t new. For quite some time, distributed systems have seen many architecture patterns emerge to solve generic to specific use cases related to data.
In this section, we’ll discuss some architecture patterns for distributed systems and different categories of use-cases they can serve.
The system architecture for a distributed system depends on the use-case and the expectation we’ve from it. However, there are some general patterns that we can find in most of the cases.
In fact, these are the core distribution models which the architecture adopts:
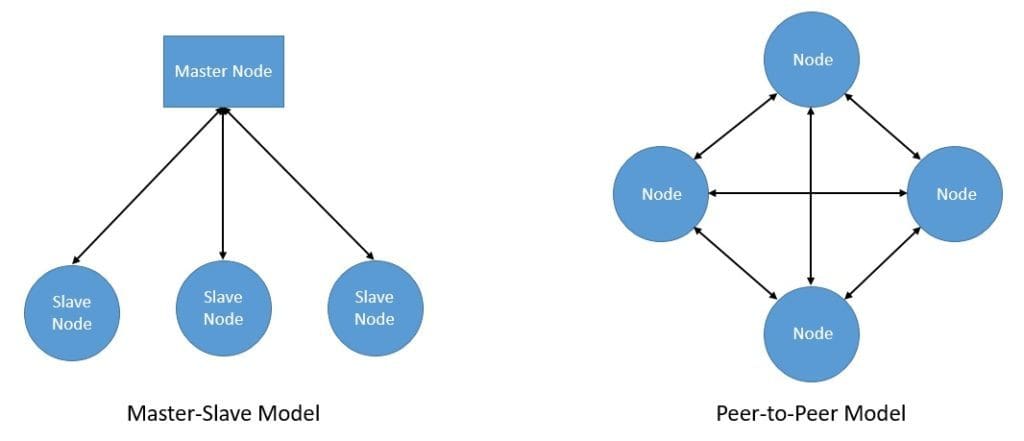
While both these architectures have their own pros and cons, it’s unnecessary to choose only one. Many of the distributed systems actually create an architecture that combines elements of both models.
A peer-to-peer model can provide data distribution, while a master-slave model can provide data replication in the same architecture.
There can be several rationales to design a distributed system. For instance, we need to perform computations like matrix multiplications at a massive scale in machine learning models. These are impossible to accommodate on a single machine.
Similarly, systems handling huge files and processing and storing them on a single machine may just be impossible or at least highly inefficient.
So, depending upon the use-case, we can broadly categorize distributed systems in the following categories. However, this definitely is not an exhaustive list of possible use-cases for distributed systems:
Traditionally, relational databases were the default choice of datastore for quite some time. However, with the recent growth in terms of volume, variety, and velocity of data, relational databases started to fall short of the expectation. This is where NoSQL databases with their distributed architecture started to prove more useful.
Similarly, the traditional messaging systems could not remain insulated to the challenges of the modern scale of data. Hence, the need for distributed messaging systems that can provide performance, scalability, and possibly durability started to rise. There are several options in this area today that provide multiple semantics like publish-subscribe and point-to-point.
We’ll discuss some popular distributed databases and messaging systems in this tutorial. The focus will primarily be on the general architecture and how they address some of the key challenges of distributed systems like partitioning and coordination.
Cassandra is an open-source, distributed key-value system that adopts a partitioned wide column storage model. It features full multi-master data replication providing high availability with low latency. It’s linearly scalable with no single point of failure.
Cassandra favors high availability and scalability and hence is an eventually consistent database. This essentially means that all updates to data eventually reach all replicas. But, divergent versions of the same data can exist temporarily. However, Cassandra also provides tunable consistency in the form of a list of consistency levels to choose from, for both the read and the write operations.
Cassandra provides horizontal scaling by evenly partitioning all data across the nodes in a cluster. A simple way to distribute data across a cluster is to use a distributed hash table. But, they normally suffer from rehashing in case the number of nodes in the cluster changes. This is where consistent hashing proves to be better and hence used by Cassandra.
Consistent hashing is a distributed hashing scheme that is independent of the number of nodes in a cluster. It has the notion of an abstract ring that represents the total range of hash values, also known as tokens:
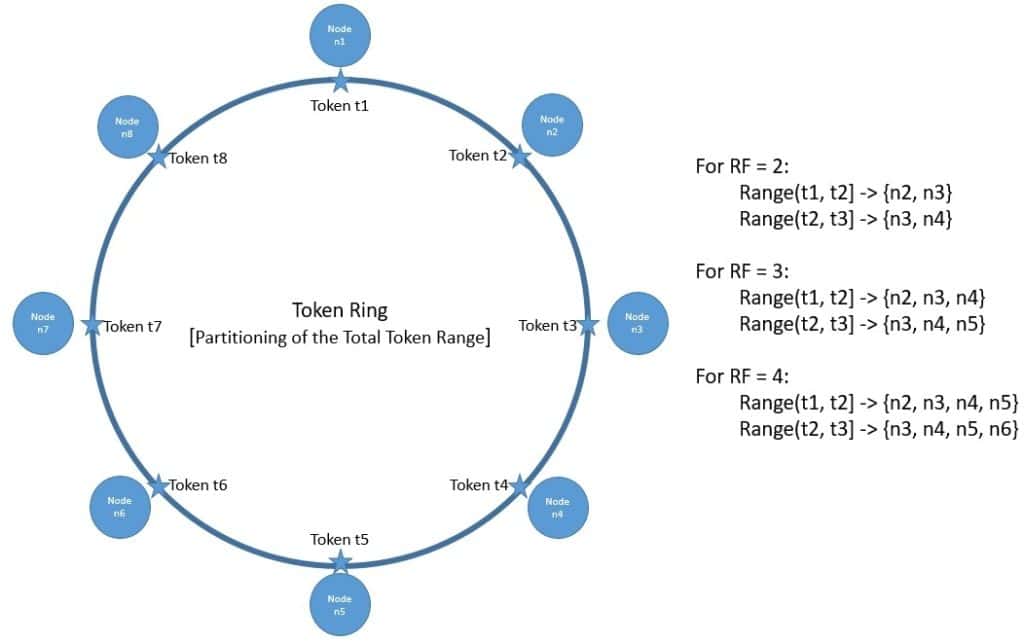
Cassandra maps every node in a cluster to one or more tokens on this token ring so that the total token range is evenly spread across the cluster. Hence, every node owns a range of tokens in this ring, depending upon where we place them in the ring.
To determine the ownership of a key, Cassandra first generates a token by hashing the key. It uses a partitioner as a hash function, and Murmur3Partitioner is the default partitioner. Once it locates the token of the key on the ring, it walks the ring in the clockwise direction to identify the nearest node which owns the token and hence the key.
Now, Cassandra also replicates each partition across multiple physical nodes to provide fault tolerance. It supports pluggable replication strategies like Siple Strategy and Network Topology Strategy to determine which nodes act as replicas for a given token range. For Simple Strategy, it simply keeps walking the ring until it finds the number of distinct nodes as defined by the replication factor (RF).
As the Cassandra cluster is multi-master, every node in the cluster can accept read and write operations independently. The node which receives the request acts as the proxy for the application. We call the proxy node the coordinator and is responsible for identifying the node which owns the key using the partitioner.
So, every node needs to know which nodes are alive or dead in the cluster to route the operations optimally. Cassandra propagates the basic cluster bootstrapping information across the cluster using the Gossip protocol:
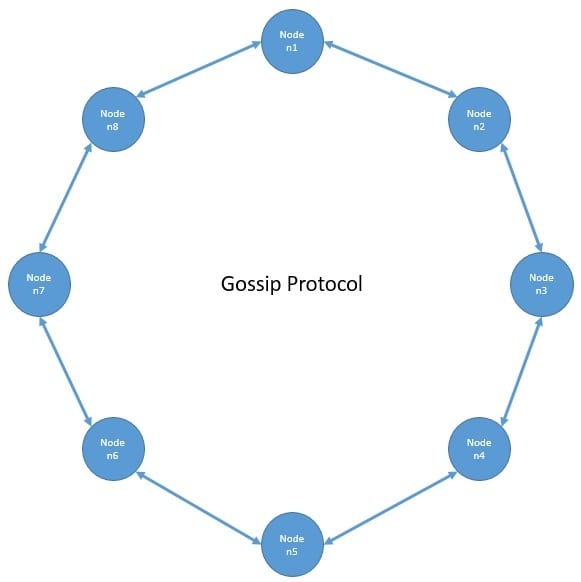
Gossip is a peer-to-peer communication protocol where every node periodically exchanges state information with a few other nodes. They exchange information about themselves and about other nodes they know about. Further, it versions the information with a vector clock so that gossip can ignore old versions of the cluster state.
Another problem with multi-master architecture is that multiple replicas can concurrently accept the same key mutation request. Hence, there must be a mechanism to reconcile the concurrent updates across the replica set.
Cassandra uses the Last-Write-Wins model to solve this problem. To simplify it, here, every mutation is timestamped, and the latest version always wins.
MongoDB is an open-source, general-purpose, document-based, distributed database that stores data as a collection of documents. A document is a simple data structure composed of field and value pairs. Further, it also provides embedded documents and arrays for complex data modeling.
We can deploy MongoDB shards as replica sets. The primary member of a replica set handles all the requests. The shard generally remains unavailable for handling requests during an automatic failover. This makes MongoDB strongly consistent by default. However, for high availability, a client can choose to read from a secondary replica where the data is only eventually consistent.
MongoDB uses the shard key to distribute the documents in a collection across multiple shards. We can create the shard key from one or more fields in the document. Obviously, the shard key’s choice implies the performance, efficiency, and scalability of the sharded cluster.
MongoDB uses the shard key to partition data into chunks. It tries to achieve an even distribution of chunks across all shards in the cluster:
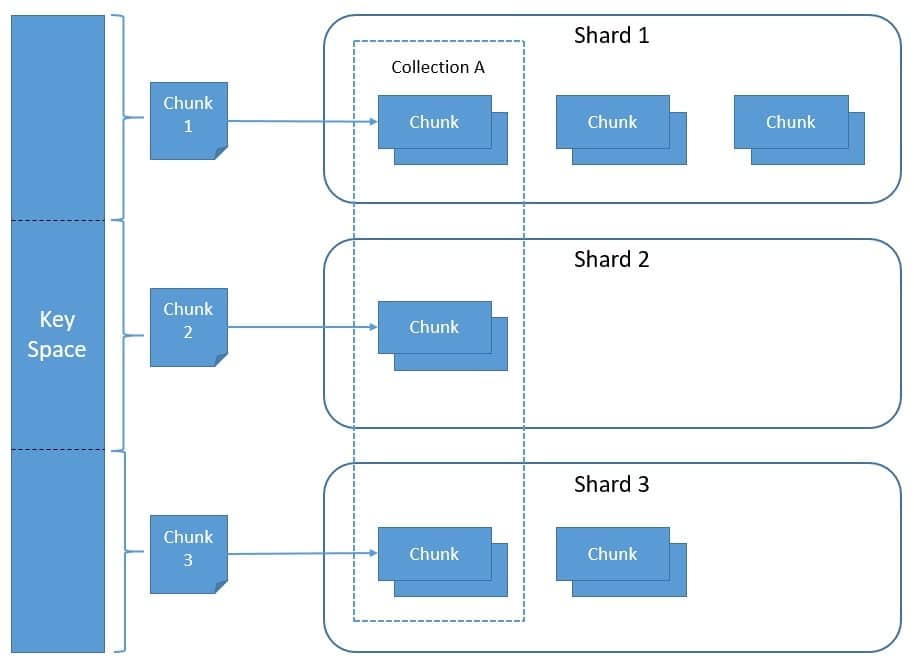
MongoDB supports two sharding strategies, hashed sharding and ranges sharding. With hashed sharding, it computes the hash of the shard key values and assigns a range of hash values to every chunk. With ranged sharding, MongoDB divides data into ranges based on the shard key values and assigns a range to every chunk.
It’s also important to balance the distribution of chunks across the shards. The default chunk size in MongoDB is 64 megabytes. When a chunk grows beyond the specified size limit or crosses the number of documents beyond a configured limit, MongoDB splits the chunk based on the shard key values. Further, MongoDB runs a balancer process that automatically migrates chunks between shards to achieve even distribution.
To improve data locality, MongoDB provides the concept of zones. This is especially useful when the shards span across multiple data centers. In a sharded cluster, we can create zones based on the shard key. Further, we can associate each zone with one or more shards in the cluster. Hence, MongoDB will migrate chunks covered by a zone only to those shards that are associated with this zone.
MongoDB uses sharding as a method of distributing data across multiple machines. Hence, a sharded cluster of MongoDB is horizontally scalable. A shard contains a subset of the data, and each shard can be deployed as a replica set. The cluster also comprises of mongos, the query router, and config servers to store metadata and configuration settings:
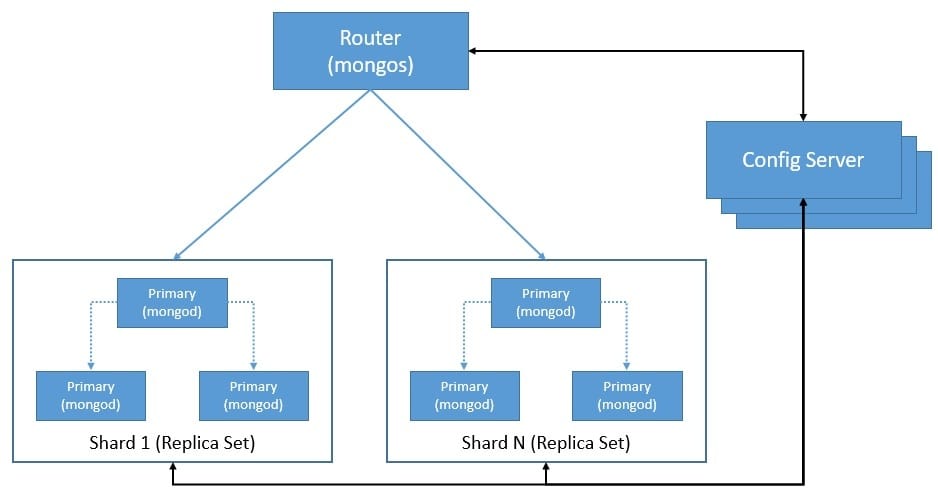
Replica sets provide automatic failover and data redundancy in MongoDB. As we can see above, a replica set is a group of mongod instances that maintain the same data set. The primary handles all write operations by recording them in its operation log known as oplog. The secondaries then replicate the primary’s oplog asynchronously.
When the primary does not communicate with the secondaries for a configured period, an eligible secondary can nominate itself as the new primary by calling for an election. Apart from primary and secondary, we can have additional instances of mongod known as an arbiter that participates in the election but does not hold data. The cluster attempts to complete the election of the new primary.
This does leave room for data loss in MongoDB, but we can minimize it by choosing the appropriate write concern. Write concern is the level of acknowledgment that we request from MongoDB. A write concern of “majority” means that we request acknowledgment for the write operation to have propagated to the calculated majority of the data-bearing voting members.
Redis is an open-source data structure store that we can use as a database, cache, or even a message broker. It supports different kinds of data structures like strings, lists, maps, to name a few. It’s primarily an in-memory key-value store with optional durability.
Redis provides high availability using a master-slave architecture where slaves are exact copies of the master. The master node accepts write requests from the clients. It further replicates the write to slave nodes asynchronously. However, clients can request synchronous replication using the WAIT command. Hence, Redis favors availability and performance over strong consistency.
Redis partitions data into multiple instances to benefit from horizontal scaling. It offers several alternate mechanisms to partition the data, including range partitioning and hash partitioning. Now, the range partitioning is simple but is not very efficient to use. The hash partitioning, on the contrary, proves to be much more efficient.
The basic premise of hash partitioning is straightforward. We can take the key and use any standard hash function like CRC32 to generate the hash of the key, which is nothing but a number. Then we perform the modulo operation on the hash to get the instance on which this key can be mapped. Obviously, this has certain limitations where consistent hashing performs better.
Now, partitioning can be done at different parts of the software stack in Redis. Starting from the client-side, some of the Redis clients implement client-side partitioning. Then we’ve proxy-based partitioning where a proxy like Twemproxy handles the partitioning:
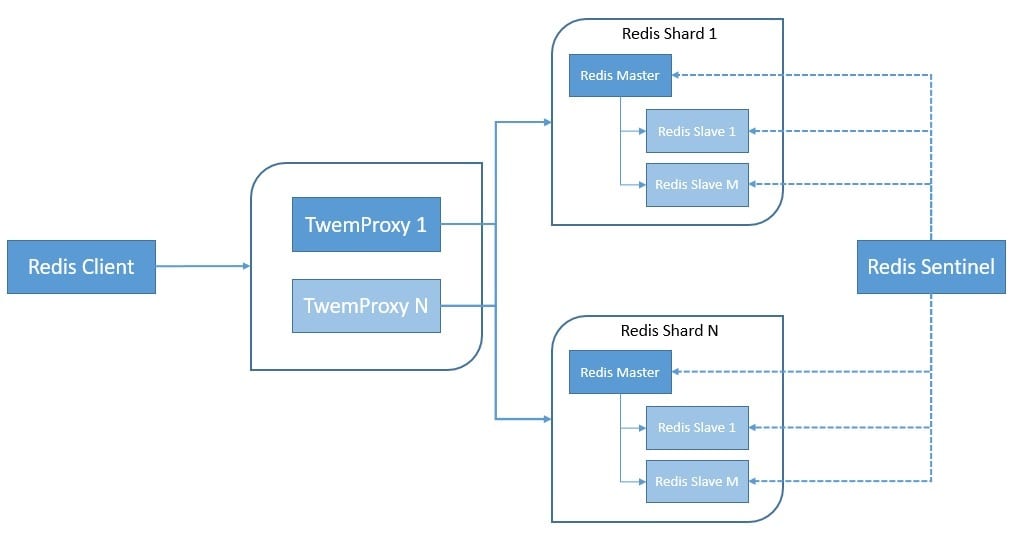
Here, Redis Sentinel provides high availability by providing automatic failover within an instance or shard. Finally, we can also use query routing, where any random instance in the cluster can handle requests by routing them to the right node.
Redis Cluster allows for automatic partitioning and high availability and hence is the preferred way to achieve the same. It uses a mix of query routing and client-side partitioning. Redis cluster uses a form of sharding where every key is part of a hash slot. There are 16384 hash slots in a Redis Cluster, and every node is responsible for a subset of this.
Redis Cluster is Redis’s distributed implementation with high-performance objectives, linear scalability, high availability, and an acceptable degree of write safety. It follows an active-passive architecture consisting of multiple masters and slaves:
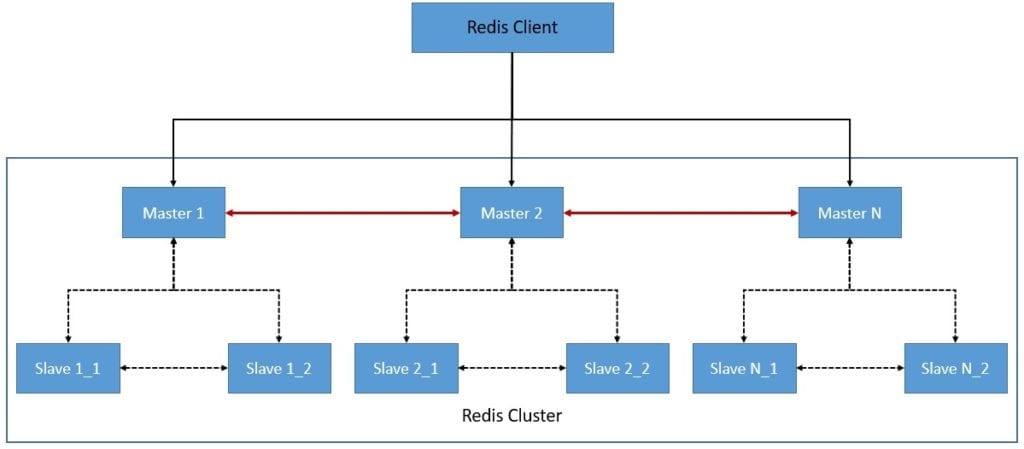
The nodes in a Redis Cluster are responsible for holding data, mapping keys to the right nodes, detecting other nodes in the cluster, and promote slave nodes to master if needed. To achieve all these tasks, every node in the Redis Cluster is connected by a TCP bus and a binary protocol known as the Redis Cluster Bus. Further, the nodes use gossip protocol to propagate information about the cluster.
As the Redis Cluster uses asynchronous replication, there is a need to provide reasonable write safety against failures. Redis Cluster uses the last failover wins implicit merge function. What this means is that the last elected master dataset eventually replaces all other replicas. This leaves a small window of time when it’s possible to lose writes during partition. However, Redis makes the best effort possible to retain writes that clients perform while connected to most masters.
Redis Cluster doesn’t proxy commands to the right nodes. Instead, they redirect clients to the right nodes serving a given portion of the keyspace. The client is free to send a request to all the cluster nodes, getting redirected if needed. However, eventually, clients receive up-to-date information about the cluster and can contact the right nodes directly.
Kafka is an open-source platform built to provide a unified, high-throughput, low-latency system for handling real-time data feeds. It allows us to publish and subscribe to streams of events, store streams of events durably and reliably, and process streams of events as they occur or retrospectively.
For enhanced durability and availability, Kafka replicates data across multiple nodes with automatic failover. An event is considered committed only when all in-sync-replicas have consumed the event. Moreover, only committed consumers can receive messages. Hence, Kafka is designed to be highly consistent and available, with many configurations to play with.
Kafka organizes and durably store events in topics. Producers are the applications that publish events to a topic, and consumers are the applications that subscribe to events from the topic. We can divide every topic into one or more partitions and distribute them across different nodes for scalability. This also allows multiple consumers to read data from a topic in parallel:
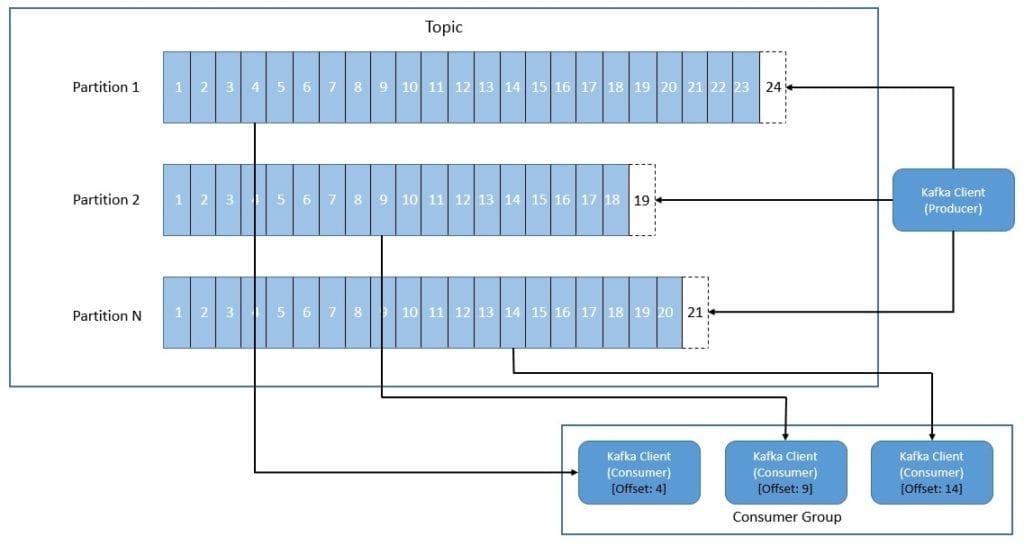
The partition here is simply put, a commit log working in an append mode from the producer point of view. Each event within a partition has an identifier known as its offset, which uniquely identifies the event’s position in the commit log. Further, Kafka retains events in the topics for a configurable period of time.
The producer can control which partition it publishes an event to. It can be random load-balancing between available partitions or using some semantic partitioning function. We can define a partition key that Kafka can use to hash the event to a fixed partition. This results in the locality of events in a partition that may be of importance to consumers.
The consumer can choose to read events from any offset point. Consumer groups in Kafka logically group multiple consumers to load balance consumption of a topic’s partitions. Kafka assigns a topic partition to only one consumer within a consumer group. When the number of consumers in a group changes, Kafka automatically tries to rebalance the partition allocation amongst consumers.
A Kafka cluster typically consists of multiple servers that can span across multiple data centers or cloud regions. They communicate with each other and with clients using a high-performance TCP network protocol. We call the servers that hold data as topic partitions as brokers. Each broker holds several partitions.
Further, Kafka uses ZooKeeper to store metadata like the location of partitions and configurations of topics:
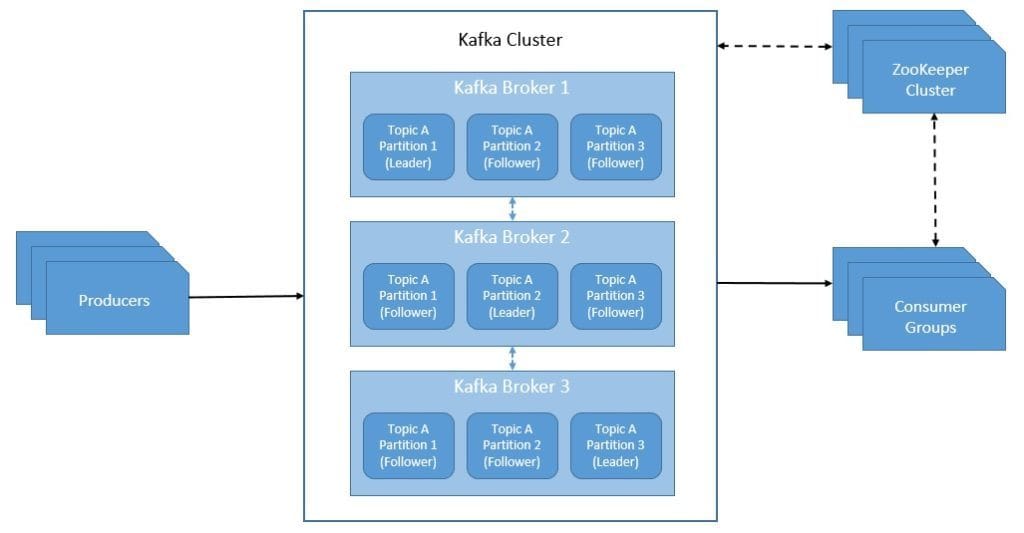
As we can see, Kafka also replicates the log of each topic’s partition across a configurable number of brokers. All writes and reads to a topic go through the leader of a partition. The leader coordinates to update the replicas with the new data. In case the leader fails, one of the replicas takes over the leader’s role through automatic failover.
Kafka defines a replica as an in-sync-replica (ISR) if it can maintain its session with the ZooKeeper and does not fall too far behind the leader. A write to Kafka is not considered committed until all in-sync-replicas have received the write. Further, only members of the set of in-sync-replicas are eligible for election as leader. Hence, Kafka can tolerate all but one in-sync replica failing without losing committed data.
Depending upon the way we configure and use Kafka clients, we can achieve different message delivery semantics. For instance, at most once, at least once, or exactly once. At the producer side, we can achieve different delivery semantic by configuring acks property of the producer and min.insync.replica property of the broker. Similarly, on the consumer side, we can use configurations like enable.auto.commit, to control the delivery semantics.
Eric Brewer postulated the CAP theorem to define constraints on a distributed system in terms of the attributes it can guarantee. Basically, it implies that a distributed system can’t provide more than two of the following three guarantees simultaneously:
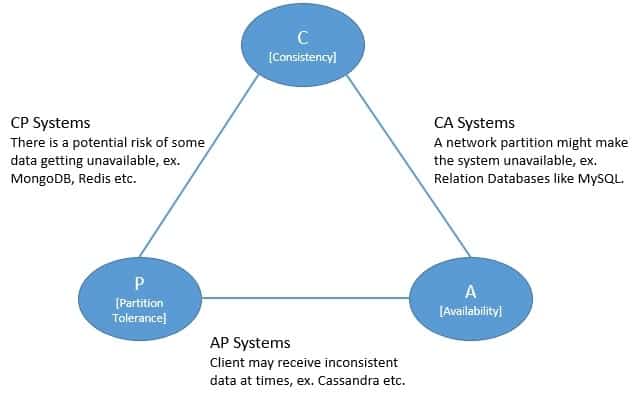
Above, we can see how the CAP theorem has been used as a guiding star to classify distributed systems! But this classification is often oversimplified, possibly misguided, and also unnecessary to some extent.
Now, it’s almost impossible in a distributed system to eliminate the possibility of a network partition entirely. So, basically, the CAP theorem’s implication boils down to making a trade-off between consistency or availability. So a system that claims to be distributed and CA must have a solid faith in the network where they operate.
But, as we have seen in the context of several distributed systems we discussed earlier, it’s really not an easy choice. Hence, most of these systems provide a lot of control in configurations so that we can choose the behavior as par requirements. Hence, it’s hardly fair or even correct to classify these systems simply as CP or AP.
In this tutorial, we went through the basics of a distributed system and understood the key benefits and challenges. Further, we made a broad assessment of some of the popular distributed systems across datastores and messaging systems.
We emphasized how they achieve data distribution and coordination in a distributed architecture.