

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about the Restricted Boltzmann Machine (RBM), a generative stochastic unsupervised learning algorithm. Mainly, we’ll go deep into the Restricted Boltzmann Machine’s (RBM) architecture, and we will walk through its learning procedure. We’ll also analyze its benefits and limitations, and mention the most common applications of an RBM.
Boltzmann Machines were developed by Hinton and Sejnowski in 1985. BMs are generative models that can be trained to build a probabilistic distribution of data by using unsupervised learning techniques. BMs can be used to sample and generate new, related data. Restricted Boltzmann Machines take this one step further by combining the structure of a BM with an additional structure called a “Restricted Neural Graph” thus making complex computations easier.
For the purpose of unsupervised learning of probability distributions, Hinton and Sejnowski introduced Restricted Boltzmann Machines in 1986. An RBM is a type of probabilistic graphical model and is a specific kind of BM. Like BMs, RBMs are used to discover latent feature representations in a dataset by learning the probability distribution of the input. In general, RBMs are useful in the dimensionality reduction of data and contribute to extracting more meaningful features.
BMs and RBMs are both types of artificial neural networks used for learning Probabilistic Graphical Models. BMs are a type of undirected graphical model, while RBMs are a variant of the Boltzmann Machine that restricts the connections between neurons so that they form a bipartite graph. The main difference between BMs and RBMs lies mainly in the number of layers they each contain. RBMs use fewer interactions between the nodes and only include connections between visible and hidden nodes. This structure allows them to train much faster than traditional Boltzmann Machines. Additionally, BMs are more powerful and can learn complex distributions, while RBMs are easier to train and converge faster.
The architecture of a Restricted Boltzmann Machine (RBM) consists of two layers of interconnected nodes: an input layer and a hidden layer with symmetrically connected weights. As we can see in the diagram below, each node in the input layer is connected to each node in the hidden layer, with each connection having a weight associated with it. Also, there are no connections between nodes of the hidden or the visible layer respectively:
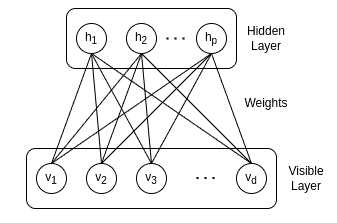
The set of neurons in the hidden layer represents the probability distribution across the input data. During training, the system updates the weights between the layers aiming to reproduce the desired output values. The purpose of each neuron in the visible layer is to observe a pattern of data, while the neurons in the hidden layer are used to explain the pattern observed by the visible neurons.
RBMs learn by using an algorithm called Contrastive Divergence (CD).
The Contrastive Divergence algorithm is a form of the gradient descent optimization method. In general, this algorithm iteratively updates the weights and biases of the neural network to approximate the probability distribution of the input of the RBM. It operates by estimating the gradient of the data’s log-likelihood function by adjusting the model parameters. Moreover, CD iterates through input and compares it to the generated output of the model until it converges to a local minimum.
The learning phase of an RBM basically refers to the adjustment of weights and biases in order to reproduce the desired output. During this phase, the RBM receives input data and drives it through the hidden layers. Each time an RBM layer receives a set of inputs, it steps through a series of iterations to redefine the weights and biases. Initially, the parameters of an RBM are initialized to small, random values. The weights and biases are then updated iteratively until a suitable convergence criterion is reached. The learning rate parameter is adjusted during the learning phase so that the model does not over-fit or under-fit the data.
The process is repeated over multiple iterations, allowing the model to improve its accuracy gradually.
The learning phase can be seen more easily in the diagram below:
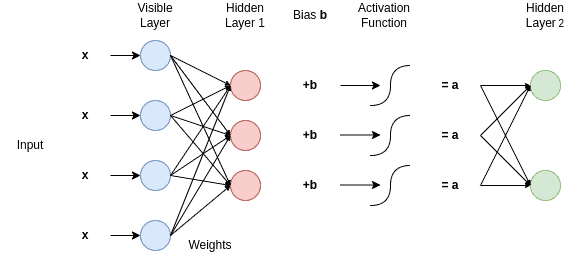
As we can see the input  is multiplied by the weights
is multiplied by the weights  of the two consecutive layers. Therefore each hidden layer receives those products, sums them, and adds a bias
of the two consecutive layers. Therefore each hidden layer receives those products, sums them, and adds a bias  to each node of the hidden layer. Then, the result is driven into an activation function and then passed into the next hidden layer.
to each node of the hidden layer. Then, the result is driven into an activation function and then passed into the next hidden layer.
Therefore the learning phase considers updating and adjusting the weights between each consecutive layer in order to find the probability distribution that best models the input data. Note that RBMs are typically used in deep learning applications as a pre-training step. After the RBM is trained, the weights of the model can be used as initial inputs for a more advanced deep learning architecture, such as a deep belief network.
RBMs are powerful unsupervised learning algorithms that are able to learn complex probability distributions. They are capable of uncovering hidden structures and relationships in high-dimensional datasets. Moreover, they seem to be quite effective for applications such as dimensionality reduction, feature extraction, and independent component analysis. Also, RBMs act as unsupervised learning algorithms, meaning they don’t require that the input data be labeled or classified.
On the other hand, the use of RBMs has some limitations. First of all, they can be computationally expensive since they require a lot of iterations over the training data and the number of parameters increases exponentially with the size of the input dataset. Furthermore, they often struggle during training if the data is dirty or has missing values. Additionally, it is hard to set up appropriate parameters for an RBM, and therefore it may not capture all of the structure and relationships of the data, resulting in poorer performance in the end.
Stacking multiple RBMs is an approach used to create deeper and more complicated neural networks. This method involves training each RBM separately and then stacking them together in a hierarchical way. The hidden units are connected such that the output of one layer is the input of the next. This allows for the information from one layer to be incorporated into the next layer and RBM respectively. Also, Deep Belief Networks are formed by the stacking of multiple RBMs. A Deep Belief Network is a powerful generative model that utilizes multiple layers of Restricted Boltzmann Machines.
Stacking RBMs has been used for applications such as image classification, natural language processing, and time series analysis.
DBNs have been employed in a wide range of applications, including dimension reduction, classification, regression, and feature learning. RBMs are effective in artificial intelligence applications, particularly deep learning. They may be used to identify patterns in high-dimensional data and aid machines in learning effectively. Because RBMs learn the probability distribution of incoming data and produce new samples from it, they may be utilized for generative modeling.
Moreover, RBMs can be used to provide personalized suggestions in applications such as Netflix, Amazon, and other recommendation systems. They learn a user’s previous behavior and culture by comparing it with other user preferences and create more personalized suggestions instead of relying solely on typical popular items.
Finally, RBMs may identify fraud and abnormalities, especially financial fraud. An RBM may be trained on a huge dataset of financial transactions before being used to detect suspicious or abnormal activities.
Lastly, RBMs are strong Artificial Intelligence (AI) models that may be utilized to analyze and comprehend complicated, high-dimensional data. They are capable of learning complex correlations between variables and producing accurate predictions and uncovering latent features and extracting useful insights. Despite their potential power, RBMs require hardware and time-consuming training to be effective, making them impractical for certain tasks.
In this article, we walked through Restricted Boltzman Machines. In particular, we mainly covered the RBM architecture. Also, we saw the main difference between a BM and RBM and discussed the learning procedure of an RMB. We talked about the essential benefits and limitations and introduced applications in which an RBM can be used.