

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll talk about the applications of generative models. First, we’ll make a very brief introduction to the domain of generative models and then we’ll present 5 applications along with some visual examples.
2. Generative Models
The main goal of a generative model is to learn the underlying distribution  of the input data. Then, these models can predict the likelihood of a given sample and generate realistic samples based on the learned underlying distribution. The most well-known generative models are GANs that learn the data distribution using two networks that compete in a zero-sum game. We can find more detailed information on the theory behind GANs in our previous tutorial.
of the input data. Then, these models can predict the likelihood of a given sample and generate realistic samples based on the learned underlying distribution. The most well-known generative models are GANs that learn the data distribution using two networks that compete in a zero-sum game. We can find more detailed information on the theory behind GANs in our previous tutorial.
3. Data Augmentation
A very important application of generative models is data augmentation. In cases when it is difficult or expensive to annotate a large amount of training data, we can use GANs to generate synthetic data and increase the size of the dataset.
For example, StyleGAN is a generative model proposed by Nvidia that is able to generate very realistic images of human faces that don’t exist. In the images below, we can see some synthetic faces generated by StyleGAN in different resolutions. I am pretty sure that you can’t see any difference between these synthetic facial images and some real facial images. The fact that these people don’t actually exist is impressive:

StyleGAN can also control the style of the generated faces. Some parts of the network control high-level styles like hairstyle and head pose, while others control facial expression and more fine details. So, the model enables us to modify the style of a person using the style of another person. In the images below, the style of source A and the identity of source B are combined to generate a synthetic facial image and the results are very realistic:

4. Super Resolution
Another domain where generative models have found many applications is super-resolution where our goal is to enhance the resolution of an input image. Specifically, we take as input a low-resolution image (like  ) and we want to increase its resolution (to
) and we want to increase its resolution (to  and even more) and keep its quality as high as possible. Super resolution is a very challenging task with a wide range of applications such as aerial or medical image analysis, video enhancement, surveillance, etc.
and even more) and keep its quality as high as possible. Super resolution is a very challenging task with a wide range of applications such as aerial or medical image analysis, video enhancement, surveillance, etc.
SRGAN is a generative model that can successfully recover photo-realistic high-resolution images from low-resolution images. The model comprises a deep network in combination with an adversary network like in most GAN architectures.
In the images below, we can see some exciting results of SRGAN. On the left, there is the original low-resolution image. In the middle, there is the generated high-resolution image by SRGAN and on the right, there is the original high-resolution image:


We observe that the generated images are very similar to the original high-resolution ones. The model managed to increase the resolution of the input image without reducing the final quality.
5. Inpainting
In image inpainting, our task is to reconstruct the missing regions in an image. In particular, we want to fill the missing pixels of the input image in a way that the new image is still realistic and the context is consistent. The applications of this task are numerous like image rendering, editing, or unwanted object removal.
Deepfill is open-source framework for the image inpainting task that uses a generative model-based approach. Its novelty lies in the Contextual Attention layer which allows the generator to make use of the information given by distant spatial locations for the reconstruction of local missing pixels.
Below, we can see the effect of Deepfill in 3 different types of images: natural scene, face, and texture:

The model is able to fill the missing pixels very naturally keeping the context of the image consistent.
6. Denoising
Nowadays, thanks to modern digital cameras we are able to take high-quality photos. However, there are still cases where an image contains a lot of noise and its quality is low. Removing the noise from an image without losing image features is a very crucial task and researchers have been working on denoising methods for many years.
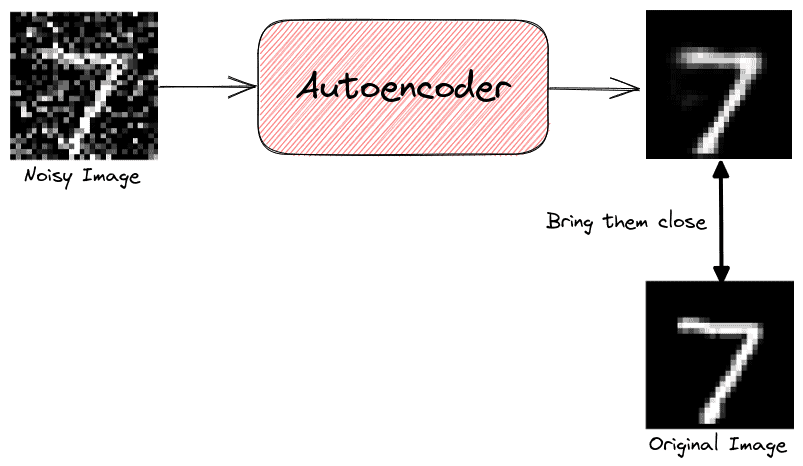
A very popular generative model for image denoising is Autoencoder that is trained to reconstruct its input image after removing the noise. During training, the network is given the original image and its noisy version. Then, the network tries to reconstruct its output to be as close as possible to the original image. As a result, the model learns to denoise images:
7. Translation
Last but not least, generative models are also used in image translation where our goal is to learn the mapping between two image domains. Then, the model is able to generate a synthetic version of the input image with a specific modification like translating a winter landscape to summer.
CycleGAN is a very famous GAN-based model for image translation. The model is trained in an unsupervised way using a dataset of images from the source and the target domain. The applications that derive from this method are above your imagination!
7.1. Collection Style Transfer
Here, the model takes as input a random landscape and transforms it into a painting of a famous painter like Monet, Van Gogh, Cezanne, and Ukiyo-e:

7.2. Object Transfiguration
Another exciting application of StyleGAN is object transfiguration where the model translates one object class to another like translating a horse to a zebra, a winter landscape to a summer one, and apples to oranges:

7.3. Image Colorization
We can use CycleGAN for automatic image colorization which is very useful in areas like restoration of aged or degraded images. Below, CycleGAN converts a grayscale image of a flower to its colorful RGB form:

8. Conclusion
In this tutorial, we presented some exciting applications of generative models.