

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll delve into the distinctions between lazy and eager machine learning (ML).
2. Lazy vs. Eager
The classification of machine learning algorithms into lazy and eager learning categories stems from their fundamental differences in handling and processing data. The key distinction between lazy and eager learning in machine learning lies in if and when they generalize from training data. The latter does that during training, whereas the former avoids deriving general rules or builds local models for each object it’s asked to classify.
These distinctions impact the efficiency of learning, adaptability to new data, and flexibility of the resulting models.
Eager learning emerged first, but it faced challenges with large datasets and real-time predictions, leading to the development of lazy learning to address these issues.
3. Lazy Learning
Leazy learning is also known as instance-based learning and memory-based learning. It postpones most of the processing and computation until a query or prediction request.
Here, the algorithm stores the training data set in its original form without deriving general rules from it. When we have a new object to process, the algorithm searches the training data for the most similar objects and uses them to produce the output, like the k-nearest neighbors (kNN) algorithm:
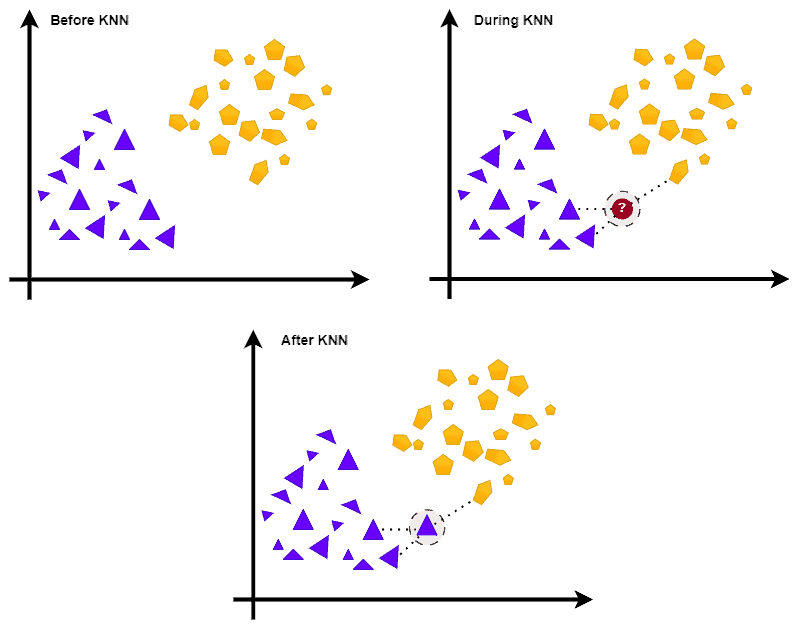
In the example above, kNN classifies an unknown point by checking its neighborhood when it arrives as the input.
3.1. Similarity Metrics
Lazy learners use a similarity metric to retrieve the training examples that are most similar to the input.
Usually, they use a distance or kernel function. For example, the Euclidean distance is commonly used:
![\[d(x, y) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2}\]](/wp-content/ql-cache/quicklatex.com-393269294b26a62a40cba5ab6de8a365_l3.svg "Rendered by QuickLaTeX.com")
So is the Gaussian Radial Basis Function (RBF) kernel:
![\[K(x, y) = \exp\left(-\frac{\|x - y\|^2}{2\sigma^2}\right)\]](/wp-content/ql-cache/quicklatex.com-e0bcfe60efa4d0c0d10435a3f7695539_l3.svg "Rendered by QuickLaTeX.com")
3.2. Examples
Here are some well-known lazy learning algorithms:
- The k-nearest neighbors algorithm (kNN) searches training data for
 closest instances to a query point. It uses a distance metric and returns the majority class or the neighbors’ average value in regression.
closest instances to a query point. It uses a distance metric and returns the majority class or the neighbors’ average value in regression. - Case-Based Reasoning (CBR) retrieves and reuses stored cases to solve new problems.
- Locally Weighted Learning (LWL) computes a local model for each query point, using a weighting function based on instance distances to the query.
- Learning Vector Quantization (LVQ) adjusts prototype vectors during training to represent dataset classes and classifies based on the closest prototype.
- Radial Basis Function (RBF) networks are neural networks using radial basis functions. Their similarity to lazy learners lies in their adaptability and reliance on local approximation.
4. Eager Learning
Eager learning, also known as model-based learning, is an approach where the ML algorithm constructs a generalized model during training. These methods try to uncover the relations and patterns hidden in training data. Hence, the resulting model is a compact and abstract representation of the training dataset used.
Eager learners adjust the model parameters during training to minimize the cost function. Once the model is trained, it can make predictions about new inputs.
Eager models can be very accurate if the relationship between the features and the target variable(s) is well-defined and the model is properly trained. Unfortunately, those models may not always generalize well to new inputs. This usually happens when the model is overfitting the training data.
For example, decision trees construct a flowchart-like structure to make predictions by recursively splitting the dataset based on feature values. Support vector machines (SVM) find the best hyperplane to separate classes by maximizing the margin between the closest training points. Other examples of eager learners are Naive Bayes and artificial neural networks (ANN).
5. Comparison
Lazy learning adapts to new data quickly as it’s during the query phase when it determines which objects to use for prediction. So, all that we need to do to use new data is to store them. In contrast, eager learning generalizes during the training phase. Incorporating the information from new data afterward requires retraining.
Lazy learning often results in simpler models since it inspects only a neighborhood of the query point, whereas eager learning may generate more complex models as it aims to find global patterns in the data.
When it comes to training time, lazy learning requires less time as the algorithms focus on storing data so that they can be easily retrieved later. In contrast, eager learning has a training phase in which it uses the entire training dataset to construct a comprehensive model for prediction. Lazy learning is slower at making predictions since it searches through data to find the query object’s neighborhood, while eager learning has a faster query time as completed models are ready to use and usually produce predictions quickly.
Memory usage is higher in lazy learning as it stores all data instances, whereas eager learning has lower memory usage since only the model is stored. Lazy learning typically generates more interpretable models based on local patterns, while interpretability in eager learning varies depending on the algorithm used. Some eager models, like deep neural networks, are more complex and difficult or impossible to interpret.
Lazy learning is well-suited for online learning as it can easily update the stored data, while eager learning requires retraining the model, which can be time-consuming.
In terms of robustness, lazy learning is less robust due to its sensitivity to noise and reliance on local patterns, whereas eager learning is generally more robust as it finds global patterns and is less sensitive to noise.
Here’s a short summary:
| Feature | Lazy Learning | Eager Learning |
|---|---|---|
| Generalization | Adapts quickly | Less flexible |
| Model complexity | Less complex | More complex |
| Training time | Minimal | Longer |
| Prediction time | Slower | Faster |
| Memory usage | Higher | Lower |
| Interpretability | More interpretable | Varies |
| Online Learning | Well-suited | Less suitable |
| Robustness | Less robust | More robust |
Overall, eager learning can provide highly accurate predictions but depends on the selected model family and training algorithm. Lazy learning can handle diverse data types. Its performance can depend heavily on the similarity metric as well as the quality and quantity of the training data.
6. How to Choose?
Eager learning is more suitable for applications requiring real-time predictions, such as financial trading or monitoring systems. It offers faster query times.
In contrast, lazy learning is more appropriate for processing large-scale data streams, such as in sensor networks or social media analysis. It is well-suited for online learning and can easily update the stored data, whereas eager learning requires retraining.
In applications where interpretability is critical, such as medical diagnosis or fraud detection, lazy learning often generates more interpretable models based on local patterns. Eager learning’s interpretability varies depending on the algorithm used, and some models may be more complex and difficult to interpret.
7. Conclusion
In this article, we explained lazy and eager learning algorithms. Lazy learning builds local models when classifying each new object or doesn’t generalize at all, while eager learning generalizes during the training phase.