

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: February 13, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explain the role of kernels in machine learning intuitively.
The so-called kernel trick enables us to apply linear models to non-linear data, which is the reason it has gained popularity in science and industry. In addition to classification, which is the task we usually associate them with, kernels can help us solve other problems in the field, such as regression, clustering, and dimensionality reduction..
Linear models are appealing for several reasons. First, the optimization problems we solve while training them have straightforward analytical solutions. Second, many would argue that linear models are inherently interpretable, so the users can understand how they work and the meaning of their components. They’re also easy to communicate and visualize. And, last but not least, they admit for a relatively simple mathematical analysis. For instance, such are Support Vector Machines, Linear Regression, and Principal Components Analysis.
However, linear models like those break down in the presence of non-linear relationships in the data. Let’s illustrate that with an example.
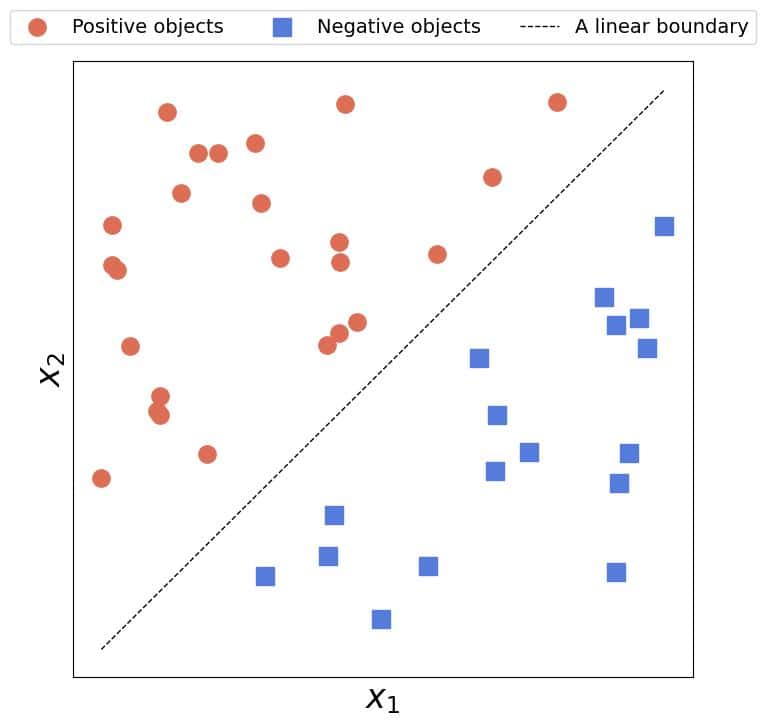
It’s easy to fit a straight line to reasonably linear data to find a linear boundary between linearly separable classes:
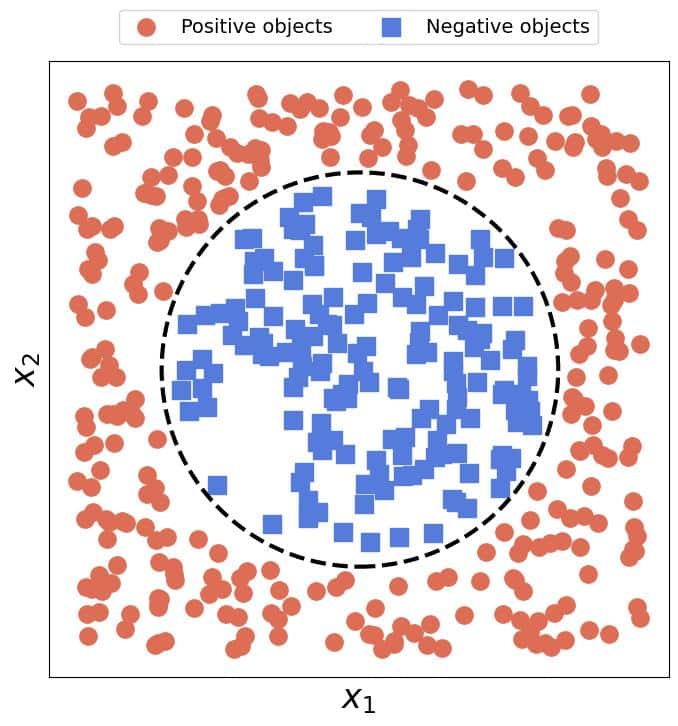
Unfortunately, no straight line can capture a circular boundary:
As a rule, the more complex and pronounced the non-linear relationships in the data are, the poorer the linear model’s performance. Still, we’d like to have models that keep the favorable properties of the linear ones but can handle arbitrarily complex data.
Kernels allow us precisely that. The idea is to map the data from the original space to a new one where they will be linear. For example, applying the transformation  to the circular dataset, we get linearly separable data:
to the circular dataset, we get linearly separable data:
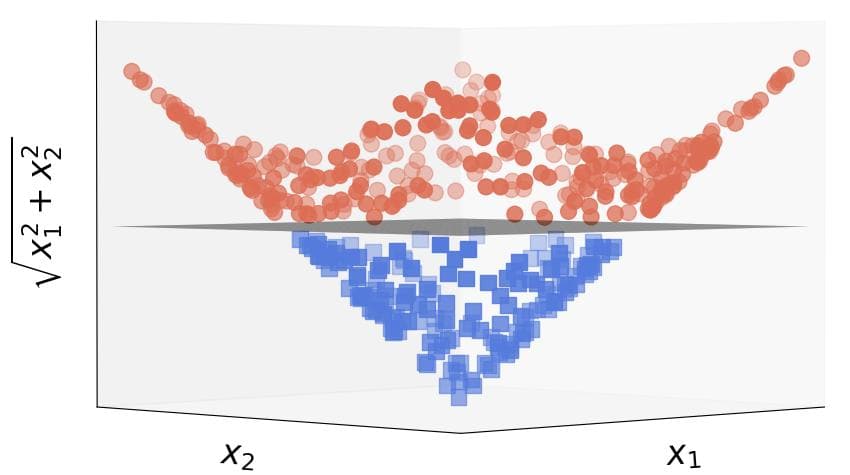
As we see, the circular boundary in the original space becomes a plane in the transformed one.
How do the kernels work? Well, we said that the idea was to find a mapping  which would transform every object
which would transform every object  to its image
to its image  in a new space
in a new space  where those images would be linear. For example, in classification problems, we seek the spaces in which the decision boundary between the classes is a linear function of the new features.
where those images would be linear. For example, in classification problems, we seek the spaces in which the decision boundary between the classes is a linear function of the new features.
However, transforming the data could be a very costly operation. Typically, a training set containing  objects with
objects with  features is an
features is an  matrix
matrix  :
:
![\[\mathbf{X} = \begin{bmatrix} x_{1,1} & x_{1,2} & \ldots & x_{1, d} \\ x_{2,1} & x_{2,2} & \ldots & x_{2, d} \\ \ldots \\ x_{n, 1} & x_{n, 2} & \ldots & x_{n, d} \\ \end{bmatrix} = \begin{bmatrix} \mathbf{x}_1^T \\ \mathbf{x}_2^T \\ \ldots \\ \mathbf{x}_{n}^T \end{bmatrix} \qquad \mathbf{x}_i = \begin{bmatrix} x_{i,1} \\ x_{i,2} \\ \ldots \\ x_{i, d} \end{bmatrix}\]](/wp-content/ql-cache/quicklatex.com-b0736ea23a20754435d20704abbc7f65_l3.svg "Rendered by QuickLaTeX.com")
Depending on the complexity of , the transformed data  could take a lot of time to compute and memory to store. Further, if the space in which the data become linear is infinitely dimensional, transforming a single object would never end, and the approach would fail.
could take a lot of time to compute and memory to store. Further, if the space in which the data become linear is infinitely dimensional, transforming a single object would never end, and the approach would fail.
Luckily for us, the kernel trick solves this issue.
The essential observation is that the solutions to the linear models’ optimization problems involve the term:
![\[\mathbf{X}\mathbf{X}^T\]](/wp-content/ql-cache/quicklatex.com-272992e501816a02a45898bc2c5fb43c_l3.svg "Rendered by QuickLaTeX.com")
Its result is an  matrix
matrix ![\mathbf{G} = [g_{i, j}]](/wp-content/ql-cache/quicklatex.com-5dd5f7986b14211e78751e00291b9c70_l3.svg "Rendered by QuickLaTeX.com") whose element
whose element  is the dot product of
is the dot product of  and
and  . The dot product on its part is the inner product
. The dot product on its part is the inner product  of those objects when we regard them as vectors in the Euclidean space
of those objects when we regard them as vectors in the Euclidean space  .
.
In the target space , the matrix  would contain the inner products of the images in :
would contain the inner products of the images in :
![\[g_{i, j} = \langle \phi(\mathbf{x}_i), \phi(\mathbf{x}_j) \rangle_H\]](/wp-content/ql-cache/quicklatex.com-1f66905a1396cba36b5cc8ecdc0d5f52_l3.svg "Rendered by QuickLaTeX.com")
That’s the only information we need to fit the linear model to the transformed data in ! By its definition, a kernel  is a function that acts on objects from the original feature space and outputs the inner product of their images in the target space
is a function that acts on objects from the original feature space and outputs the inner product of their images in the target space  :
:
![\[k(\mathbf{x}, \mathbf{z}) = \langle \phi(\mathbf{x}), \phi(\mathbf{z}) \rangle_H\]](/wp-content/ql-cache/quicklatex.com-df22ed04125ac89bc1524ae1b2038681_l3.svg "Rendered by QuickLaTeX.com")
So, the kernel trick allows us to fit a linear model in a target space without transforming the data. Therefore, to solve a non-linear problem with a linear algorithm, we need the appropriate  and .
and .
However, how do we find the kernel and the target space ? The best advice is to look at the data. For instance, if we spot quadratic patterns, we should go with the quadratic function:
![\[k(\mathbf{x}, \mathbf{z}) = \left( \mathbf{x}^T \mathbf{z} + c \right)^2 \qquad c \in R\]](/wp-content/ql-cache/quicklatex.com-aea324024f20913acea862d2e9fc8146_l3.svg "Rendered by QuickLaTeX.com")
However, it’s not always easy to see which kernel is the best fit. In that case, we can try some popular choices like the Gaussian (RBF) kernel:
![\[k(\mathbf{x}, \mathbf{z}) = e^{- \gamma || \mathbf{x} - \mathbf{z} ||^2} \qquad \gamma > 0\]](/wp-content/ql-cache/quicklatex.com-b7e91f4057ea5bdb154b45dfba4cacf0_l3.svg "Rendered by QuickLaTeX.com")
where  is the Euclidean norm.
is the Euclidean norm.
We can determine any kernel parameter’s value with cross-validation.
Another way to look at kernels is to interpret them as similarity measures. To see why, let’s remember that kernels replace the Euclidean inner product, i.e., the dot product of vectors in . If the vectors are orthogonal, the product is equal to zero, and we can see that the orthogonal vectors differ the most:
The less orthogonal, i.e., the more similar two vectors are, the greater their inner product. Since kernels compute the inner products in target feature spaces, they too have this property. So, a good kernel should reflect the similarity of the objects we compute it over.
This interpretation has a mathematical justification. All the kernels are positive semi-definite functions, which is in line with being a similarity measure. Zero is reserved for completely dissimilar objects, while positive values quantify various degrees of similarity.
We usually apply machine learning to tabular data, that is, the data in which each object is a vector with a precisely defined order of features. However, not all data are like that. For example, sets don’t come with an ordering. The same goes for structured data, graphs, and nodes in them.
So, constructing kernels to measure similarity between those objects, we can extend linear models to non-vector data. For example, the intersection over union quantifies the similarity between two sets:
![\[k_{ set }( A, B ) = \frac{ | A \cap B | }{ | A \cup B| }\]](/wp-content/ql-cache/quicklatex.com-fb3409c8b0f6763d9b54d33ca35e51a1_l3.svg "Rendered by QuickLaTeX.com")
Using  as a kernel, we can fit linear models to the data whose objects are sets.
as a kernel, we can fit linear models to the data whose objects are sets.
What’s the relationship between kernels and feature spaces? Each space has a unique kernel because the inner product is unique in every space endowed with it. The converse, however, doesn’t hold. Let’s take a look at the very simple 1D kernel:
![\[k( x_1, x_2 ) = x_1 x_2 \qquad x_1, x_2 \in R\]](/wp-content/ql-cache/quicklatex.com-c3705282a0816779dcc27b778bfc1e04_l3.svg "Rendered by QuickLaTeX.com")
It’s a special case of the Euclidean space in one dimension. The identity mapping  corresponds to the mapping we associate with this kernel, so we could say that the original and the target spaces are the same. But, some other mappings and spaces also fit this kernel. For example:
corresponds to the mapping we associate with this kernel, so we could say that the original and the target spaces are the same. But, some other mappings and spaces also fit this kernel. For example:
![\[\psi: x \mapsto \begin{bmatrix} x / \sqrt{2} \\ x / \sqrt{2} \end{bmatrix}\]](/wp-content/ql-cache/quicklatex.com-dd741544276e49ae2f32c236e3d19647_l3.svg "Rendered by QuickLaTeX.com")
which we can verify:
![\[\langle \psi( x_1 ), \psi( x_2 ) \rangle = \begin{bmatrix} x_1 / \sqrt{ 2 } & x_1 / \sqrt{ 2 } \end{bmatrix} \times \begin{bmatrix} x_2 / \sqrt{ 2 } \\ x_2 \sqrt{ 2 } \end{bmatrix} = \frac{ x_1 x_2 }{ 2 } + \frac{ x_1 x_2 }{ 2 } = x_1 x_2\]](/wp-content/ql-cache/quicklatex.com-a833ca556e9aeb5f3b70186bcaaa8f21_l3.svg "Rendered by QuickLaTeX.com")
Therefore, every kernel can correspond to multiple feature spaces.
In this article, we gave an intuitive explanation of the kernel trick. As we saw, kernels allow us to efficiently fit linear models to non-linear data without explicitly transforming them to feature spaces where they are linear. Thus, they save us both time and space.
We can interpret kernels as the measures of similarity between the objects. Constructing them to quantify the similarity, we can apply them to any data type such as graphs or sets, not just vectors where the order of features matters and is fixed in advance.