

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll study two important measures of distance between points in vector spaces: the Euclidean distance and the cosine similarity.
We’ll then see how can we use them to extract insights on the features of a sample dataset. We’ll also see when should we prefer using one over the other, and what are the advantages that each of them carries.
Both cosine similarity and Euclidean distance are methods for measuring the proximity between vectors in a vector space. It’s important that we, therefore, define what do we mean by the distance between two vectors, because as we’ll soon see this isn’t exactly obvious.
Let’s start by studying the case described in this image:
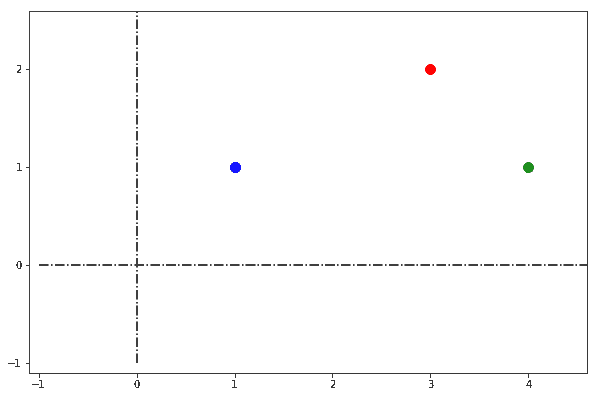
We have a 2D vector space in which three distinct points are located: blue, red, and green. We could ask ourselves the question as to which pair or pairs of points are closer to one another. As we do so, we expect the answer to be comprised of a unique set of pair or pairs of points:
This means that the set with the closest pair or pairs of points is one of seven possible sets. How do we determine then which of the seven possible answers is the right one? To do so, we need to first determine a method for measuring distances.
We can determine which answer is correct by taking a ruler, placing it between two points, and measuring the reading:
If we do this for all possible pairs, we can develop a list of measurements for pair-wise distances. By sorting the table in ascending order, we can then find the pairwise combination of points with the shortest distances:
| Pairs | Euclidean distance |
|---|---|
| (red, green) |  |
| (blue, red) |  |
| (blue, green) |  |
In this example, the set comprised of the pair (red, green) is the one with the shortest distance. We can thus declare that the shortest Euclidean distance between the points in our set is the one between the red and green points, as measured by a ruler.
We can also use a completely different, but equally valid, approach to measure distances between the same points.
Let’s imagine we are looking at the points not from the top of the plane or from bird-view; but rather from inside the plane, and specifically from its origin. If we do this, we can represent with an arrow the orientation we assume when looking at each point:
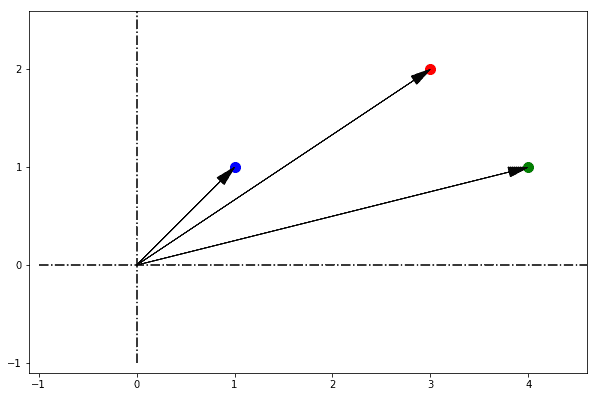
From our perspective on the origin, it doesn’t really matter how far from the origin the points are. In fact, we have no way to understand that without stepping out of the plane and into the third dimension.
As far as we can tell by looking at them from the origin, all points lie on the same horizon, and they only differ according to their direction against a reference axis:
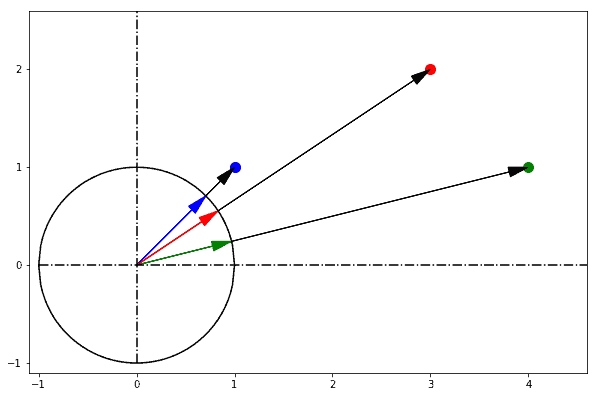
We really don’t know how long it’d take us to reach any of those points by walking straight towards them from the origin, so we know nothing about their depth in our field of view. What we do know, however, is how much we need to rotate in order to look straight at each of them if we start from a reference axis:
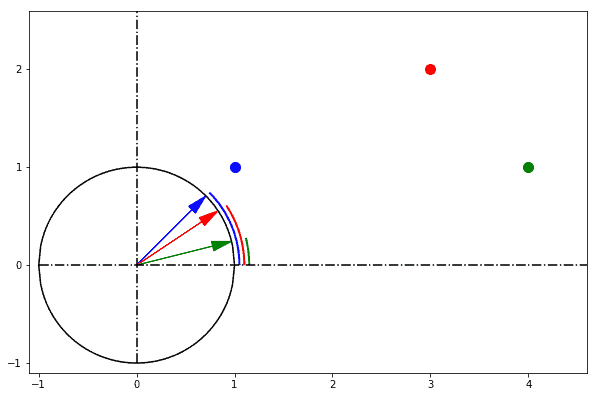
We can at this point make a list containing the rotations from the reference axis associated with each point. We can subsequently calculate the distance from each point as a difference between these rotations. If we do so we obtain the following pair-wise angular distances:
| Pairs | Angular distance |
|---|---|
 |
 |
 |
 |
 |
 |
We can notice how the pair of points that are the closest to one another is (blue, red) and not (red, green), as in the previous example. We can in this case say that the pair of points blue and red is the one with the smallest angular distance between them.
Note how the answer we obtain differs from the previous one, and how the change in perspective is the reason why we changed our approach.
What we’ve just seen is an explanation in practical terms as to what we mean when we talk about Euclidean distances and angular distances.
In the example above, Euclidean distances are represented by the measurement of distances by a ruler from a bird-view while angular distances are represented by the measurement of differences in rotations.
Let’s now generalize these considerations to vector spaces of any dimensionality, not just to 2D planes and vectors.
In ℝ , the Euclidean distance
, the Euclidean distance  between two vectors
between two vectors  and
and  is always defined. It corresponds to the L2-norm
is always defined. It corresponds to the L2-norm  of the difference
of the difference  between the two vectors. It can be computed as:
between the two vectors. It can be computed as:

A vector space where Euclidean distances can be measured, such as  ,
,  ,
,  , is called a Euclidean vector space.
, is called a Euclidean vector space.
Most vector spaces in machine learning belong to this category.
This means that when we conduct machine learning tasks, we can usually try to measure Euclidean distances in a dataset during preliminary data analysis. Some machine learning algorithms, such as K-Means, work specifically on the Euclidean distances between vectors, so we’re forced to use that metric if we need them.
If we go back to the example discussed above, we can start from the intuitive understanding of angular distances in order to develop a formal definition of cosine similarity.
Cosine similarity between two vectors corresponds to their dot product divided by the product of their magnitudes. If  and
and  are vectors as defined above, their cosine similarity
are vectors as defined above, their cosine similarity  is:
is:

The relationship between cosine similarity and the angular distance which we discussed above is fixed, and it’s possible to convert from one to the other with a formula:

Let’s take a look at the famous Iris dataset, and see how can we use Euclidean distances to gather insights on its structure. This is its distribution on a 2D plane, where each color represents one type of flower and the two dimensions indicate length and width of the petals:
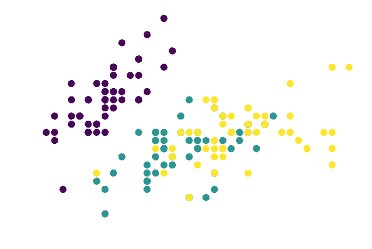
We can use the K-Means algorithm to cluster the dataset into three groups.
The K-Means algorithm tries to find the cluster centroids whose position minimizes the Euclidean distance with the most points. In red, we can see the position of the centroids identified by K-Means for the three clusters:
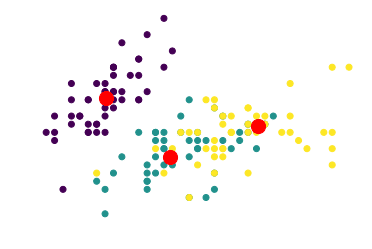
Clusterization of the Iris dataset on the basis of the Euclidean distance shows that the two clusters closest to one another are the purple and the teal clusters. We’re going to interpret this statement shortly; let’s keep this in mind for now while reading the next section.
As we have done before, we can now perform clusterization of the Iris dataset on the basis of the angular distance (or rather, cosine similarity) between observations.
Remember what we said about angular distances: We imagine that all observations are projected onto a horizon and that they are all equally distant from us. The picture below thus shows the clusterization of Iris, projected onto the unitary circle, according to spherical K-Means:

We can see how the result obtained differs from the one found earlier.
It appears this time that teal and yellow are the two clusters whose centroids are closest to one another. This is because we are now measuring cosine similarities rather than Euclidean distances, and the directions of the teal and yellow vectors generally lie closer to one another than those of purple vectors.
This answer is consistent across different random initializations of the clustering algorithm and shows a difference in the distribution of Euclidean distances vis-à-vis cosine similarities in the Iris dataset.
We can now compare and interpret the results obtained in the two cases in order to extract some insights into the underlying phenomena that they describe:
The interpretation that we have given is specific for the Iris dataset. Its underlying intuition can however be generalized to any datasets. Vectors whose Euclidean distance is small have a similar “richness” to them; while vectors whose cosine similarity is high look like scaled-up versions of one another.
The decision as to which metric to use depends on the particular task that we have to perform:
As is often the case in machine learning, the trick consists in knowing all techniques and learning the heuristics associated with their application. This is acquired via trial and error.
The way to speed up this process, though, is by holding in mind the visual images we presented here. If we do so, we’ll have an intuitive understanding of the underlying phenomenon and simplify our efforts.
In this article, we’ve studied the formal definitions of Euclidean distance and cosine similarity. The Euclidean distance corresponds to the L2-norm of a difference between vectors. The cosine similarity is proportional to the dot product of two vectors and inversely proportional to the product of their magnitudes.
We’ve also seen what insights can be extracted by using Euclidean distance and cosine similarity to analyze a dataset. Vectors with a small Euclidean distance from one another are located in the same region of a vector space. Vectors with a high cosine similarity are located in the same general direction from the origin.