

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’ll understand how to leverage Apache Spark MLlib to develop machine learning products. We’ll develop a simple machine learning product with Spark MLlib to demonstrate the core concepts.
2. A Brief Primer to Machine Learning
Machine Learning is part of a broader umbrella known as Artificial Intelligence. Machine learning refers to the study of statistical models to solve specific problems with patterns and inferences. These models are “trained” for the specific problem by the means of training data drawn from the problem space.
We’ll see what exactly this definition entails as we take on our example.
2.1. Machine Learning Categories
We can broadly categorize machine learning into supervised and unsupervised categories based on the approach. There are other categories as well, but we’ll keep ourselves to these two:
- Supervised learning works with a set of data that contains both the inputs and the desired output — for instance, a data set containing various characteristics of a property and the expected rental income. Supervised learning is further divided into two broad sub-categories called classification and regression:
- Classification algorithms are related to categorical output, like whether a property is occupied or not
- Regression algorithms are related to a continuous output range, like the value of a property
- Unsupervised learning, on the other hand, works with a set of data which only have input values. It works by trying to identify the inherent structure in the input data. For instance, finding different types of consumers through a data set of their consumption behavior.
2.2. Machine Learning Workflow
Machine learning is truly an inter-disciplinary area of study. It requires knowledge of the business domain, statistics, probability, linear algebra, and programming. As this can clearly get overwhelming, it’s best to approach this in an orderly fashion, what we typically call a machine learning workflow:
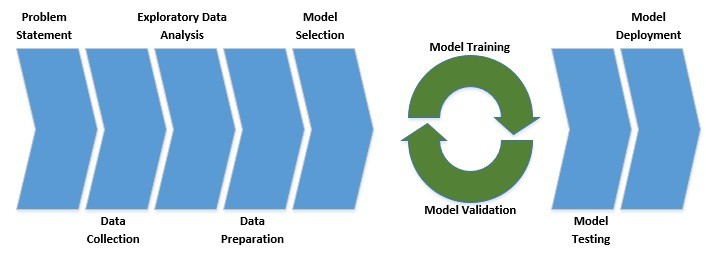
As we can see, every machine learning project should start with a clearly defined problem statement. This should be followed by a series of steps related to data that can potentially answer the problem.
Then we typically select a model looking at the nature of the problem. This is followed by a series of model training and validation, which is known as model fine-tuning. Finally, we test the model on previously unseen data and deploy it to production if satisfactory.
3. What Is Spark MLlib?
Spark MLlib is a module on top of Spark Core that provides machine learning primitives as APIs. Machine learning typically deals with a large amount of data for model training.
The base computing framework from Spark is a huge benefit. On top of this, MLlib provides most of the popular machine learning and statistical algorithms. This greatly simplifies the task of working on a large-scale machine learning project.
4. Machine Learning with MLlib
We now have enough context on machine learning and how MLlib can help in this endeavor. Let’s get started with our basic example of implementing a machine learning project with Spark MLlib.
If we recall from our discussion on machine learning workflow, we should start with a problem statement and then move on to data. Fortunately for us, we’ll pick the “hello world” of machine learning, Iris Dataset. This is a multivariate labeled dataset, consisting of length and width of sepals and petals of different species of Iris.
This gives our problem objective: can we predict the species of an Iris from the length and width of its sepal and petal?
4.1. Setting the Dependencies
First, we have to define the following dependency in Maven to pull the relevant libraries:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.4.3</version>
<scope>provided</scope>
</dependency>And we need to initialize the SparkContext to work with Spark APIs:
SparkConf conf = new SparkConf()
.setAppName("Main")
.setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(conf);4.2. Loading the Data
First things first, we should download the data, which is available as a text file in CSV format. Then we have to load this data in Spark:
String dataFile = "data\\iris.data";
JavaRDD<String> data = sc.textFile(dataFile);Spark MLlib offers several data types, both local and distributed, to represent the input data and corresponding labels. The simplest of the data types are Vector:
JavaRDD<Vector> inputData = data
.map(line -> {
String[] parts = line.split(",");
double[] v = new double[parts.length - 1];
for (int i = 0; i < parts.length - 1; i++) {
v[i] = Double.parseDouble(parts[i]);
}
return Vectors.dense(v);
});Note that we’ve included only the input features here, mostly to perform statistical analysis.
A training example typically consists of multiple input features and a label, represented by the class LabeledPoint:
Map<String, Integer> map = new HashMap<>();
map.put("Iris-setosa", 0);
map.put("Iris-versicolor", 1);
map.put("Iris-virginica", 2);
JavaRDD<LabeledPoint> labeledData = data
.map(line -> {
String[] parts = line.split(",");
double[] v = new double[parts.length - 1];
for (int i = 0; i < parts.length - 1; i++) {
v[i] = Double.parseDouble(parts[i]);
}
return new LabeledPoint(map.get(parts[parts.length - 1]), Vectors.dense(v));
});Our output label in the dataset is textual, signifying the species of Iris. To feed this into a machine learning model, we have to convert this into numeric values.
4.3. Exploratory Data Analysis
Exploratory data analysis involves analyzing the available data. Now, machine learning algorithms are sensitive towards data quality, hence a higher quality data has better prospects for delivering the desired outcome.
Typical analysis objectives include removing anomalies and detecting patterns. This even feeds into the critical steps of feature engineering to arrive at useful features from the available data.
Our dataset, in this example, is small and well-formed. Hence we don’t have to indulge in a lot of data analysis. Spark MLlib, however, is equipped with APIs to offer quite an insight.
Let’s begin with some simple statistical analysis:
MultivariateStatisticalSummary summary = Statistics.colStats(inputData.rdd());
System.out.println("Summary Mean:");
System.out.println(summary.mean());
System.out.println("Summary Variance:");
System.out.println(summary.variance());
System.out.println("Summary Non-zero:");
System.out.println(summary.numNonzeros());Here, we’re observing the mean and variance of the features we have. This is helpful in determining if we need to perform normalization of features. It’s useful to have all features on a similar scale. We are also taking a note of non-zero values, which can adversely impact model performance.
Here is the output for our input data:
Summary Mean:
[5.843333333333332,3.0540000000000003,3.7586666666666666,1.1986666666666668]
Summary Variance:
[0.6856935123042509,0.18800402684563744,3.113179418344516,0.5824143176733783]
Summary Non-zero:
[150.0,150.0,150.0,150.0]Another important metric to analyze is the correlation between features in the input data:
Matrix correlMatrix = Statistics.corr(inputData.rdd(), "pearson");
System.out.println("Correlation Matrix:");
System.out.println(correlMatrix.toString());A high correlation between any two features suggests they are not adding any incremental value and one of them can be dropped. Here is how our features are correlated:
Correlation Matrix:
1.0 -0.10936924995064387 0.8717541573048727 0.8179536333691672
-0.10936924995064387 1.0 -0.4205160964011671 -0.3565440896138163
0.8717541573048727 -0.4205160964011671 1.0 0.9627570970509661
0.8179536333691672 -0.3565440896138163 0.9627570970509661 1.04.4. Splitting the Data
If we recall our discussion of machine learning workflow, it involves several iterations of model training and validation followed by final testing.
For this to happen, we have to split our training data into training, validation, and test sets. To keep things simple, we’ll skip the validation part. So, let’s split our data into training and test sets:
JavaRDD<LabeledPoint>[] splits = parsedData.randomSplit(new double[] { 0.8, 0.2 }, 11L);
JavaRDD<LabeledPoint> trainingData = splits[0];
JavaRDD<LabeledPoint> testData = splits[1];4.5. Model Training
So, we’ve reached a stage where we’ve analyzed and prepared our dataset. All that’s left is to feed this into a model and start the magic! Well, easier said than done. We need to pick a suitable algorithm for our problem – recall the different categories of machine learning we spoke of earlier.
It isn’t difficult to understand that our problem fits into classification within the supervised category. Now, there are quite a few algorithms available for use under this category.
The simplest of them is Logistic Regression (let the word regression not confuse us; it is, after all, a classification algorithm):
LogisticRegressionModel model = new LogisticRegressionWithLBFGS()
.setNumClasses(3)
.run(trainingData.rdd());Here, we are using a three-class Limited Memory BFGS based classifier. The details of this algorithm are beyond the scope of this tutorial, but this is one of the most widely used ones.
4.6. Model Evaluation
Remember that model training involves multiple iterations, but for simplicity, we’ve just used a single pass here. Now that we’ve trained our model, it’s time to test this on the test dataset:
JavaPairRDD<Object, Object> predictionAndLabels = testData
.mapToPair(p -> new Tuple2<>(model.predict(p.features()), p.label()));
MulticlassMetrics metrics = new MulticlassMetrics(predictionAndLabels.rdd());
double accuracy = metrics.accuracy();
System.out.println("Model Accuracy on Test Data: " + accuracy);Now, how do we measure the effectiveness of a model? There are several metrics that we can use, but one of the simplest is Accuracy. Simply put, accuracy is a ratio of the correct number of predictions and the total number of predictions. Here is what we can achieve in a single run of our model:
Model Accuracy on Test Data: 0.9310344827586207Note that this will vary slightly from run to run due to the stochastic nature of the algorithm.
However, accuracy is not a very effective metric in some problem domains. Other more sophisticated metrics are Precision and Recall (F1 Score), ROC Curve, and Confusion Matrix.
4.7. Saving and Loading the Model
Finally, we often need to save the trained model to the filesystem and load it for prediction on production data. This is trivial in Spark:
model.save(sc, "model\\logistic-regression");
LogisticRegressionModel sameModel = LogisticRegressionModel
.load(sc, "model\\logistic-regression");
Vector newData = Vectors.dense(new double[]{1,1,1,1});
double prediction = sameModel.predict(newData);
System.out.println("Model Prediction on New Data = " + prediction);So, we’re saving the model to the filesystem and loading it back. After loading, the model can be straight away used to predict output on new data. Here is a sample prediction on random new data:
Model Prediction on New Data = 2.05. Beyond the Primitive Example
While the example we went through covers the workflow of a machine learning project broadly, it leaves a lot of subtle and important points. While it isn’t possible to discuss them in detail here, we can certainly go through some of the important ones.
Spark MLlib through its APIs has extensive support in all these areas.
5.1. Model Selection
Model selection is often one of the complex and critical tasks. Training a model is an involved process and is much better to do on a model that we’re more confident will produce the desired results.
While the nature of the problem can help us identify the category of machine learning algorithm to pick from, it isn’t a job fully done. Within a category like classification, as we saw earlier, there are often many possible different algorithms and their variations to choose from.
Often the best course of action is quick prototyping on a much smaller set of data. A library like Spark MLlib makes the job of quick prototyping much easier.
5.2. Model Hyper-Parameter Tuning
A typical model consists of features, parameters, and hyper-parameters. Features are what we feed into the model as input data. Model parameters are variables which model learns during the training process. Depending on the model, there are certain additional parameters that we have to set based on experience and adjust iteratively. These are called model hyper-parameters.
For instance, the learning rate is a typical hyper-parameter in gradient-descent based algorithms. Learning rate controls how fast parameters are adjusted during training cycles. This has to be aptly set for the model to learn effectively at a reasonable pace.
While we can begin with an initial value of such hyper-parameters based on experience, we have to perform model validation and manually tune them iteratively.
5.3. Model Performance
A statistical model, while being trained, is prone to overfitting and underfitting, both causing poor model performance. Underfitting refers to the case where the model does not pick the general details from the data sufficiently. On the other hand, overfitting happens when the model starts to pick up noise from the data as well.
There are several methods for avoiding the problems of underfitting and overfitting, which are often employed in combination. For instance, to counter overfitting, the most employed techniques include cross-validation and regularization. Similarly, to improve underfitting, we can increase the complexity of the model and increase the training time.
Spark MLlib has fantastic support for most of these techniques like regularization and cross-validation. In fact, most of the algorithms have default support for them.
6. Spark MLlib in Comparision
While Spark MLlib is quite a powerful library for machine learning projects, it is certainly not the only one for the job. There are quite a number of libraries available in different programming languages with varying support. We’ll go through some of the popular ones here.
6.1. Tensorflow/Keras
Tensorflow is an open-source library for dataflow and differentiable programming, widely employed for machine learning applications. Together with its high-level abstraction, Keras, it is a tool of choice for machine learning. They are primarily written in Python and C++ and primarily used in Python. Unlike Spark MLlib, it does not have a polyglot presence.
6.2. Theano
Theano is another Python-based open-source library for manipulating and evaluating mathematical expressions – for instance, matrix-based expressions, which are commonly used in machine learning algorithms. Unlike Spark MLlib, Theano again is primarily used in Python. Keras, however, can be used together with a Theano back end.
6.3. CNTK
Microsoft Cognitive Toolkit (CNTK) is a deep learning framework written in C++ that describes computational steps via a directed graph. It can be used in both Python and C++ programs and is primarily used in developing neural networks. There’s a Keras back end based on CNTK available for use that provides the familiar intuitive abstraction.
7. Conclusion
To sum up, in this tutorial we went through the basics of machine learning, including different categories and workflow. We went through the basics of Spark MLlib as a machine learning library available to us.
Furthermore, we developed a simple machine learning application based on the available dataset. We implemented some of the most common steps in the machine learning workflow in our example.
We also went through some of the advanced steps in a typical machine learning project and how Spark MLlib can help in those. Finally, we saw some of the alternative machine learning libraries available for us to use.


















