Graphs in Java
Last updated: May 19, 2025

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this tutorial, we’ll look at the basic concepts of a graph as a data structure.
We’ll also explore its implementation in Java and the various operations possible on a graph, as well as discuss the Java libraries offering graph implementations.
Further reading:
Checking if a Java Graph Has a Cycle
Dijkstra Shortest Path Algorithm in Java
Introduction to JGraphT
2. Graph Data Structure
A graph is a data structure for storing connected data, such as a network of people on a social media platform.
A graph consists of vertices and edges. A vertex (or node) represents the entity (e.g., people), and an edge represents the relationship between entities (e.g., a person’s friendships).
Let’s define a simple Graph to understand this better:
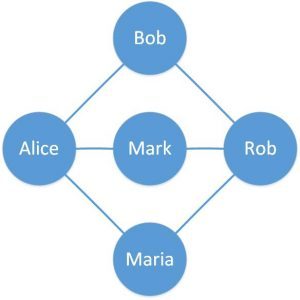
Here, we’ve defined a simple graph with five vertices and six edges. The circles are vertices representing people and the lines connecting two vertices are edges representing friends on an online portal.
Depending on the properties of the edges, this simple graph has a few variations. Let’s briefly go through them in the next sections.
However, we’ll only focus on the simple graph for the Java examples in this tutorial.
2.1. Directed Graph
The graph we’ve defined so far has edges without any direction. If these edges feature a direction in them, the resulting graph is known as a directed graph.
An example of this can be representing who sent the friend request in a friendship on the online portal:
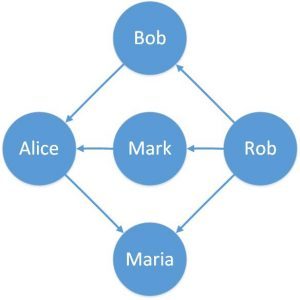
Here, we can see that the edges have a fixed direction. The edges can be bidirectional as well.
2.2. Weighted Graph
Again, our simple graph has edges that are unbiased or unweighted.
If, instead, these edges carry relative weight, this graph is known as a weighted graph.
An example of a practical application of this can be representing how relatively old a friendship is on the online portal:
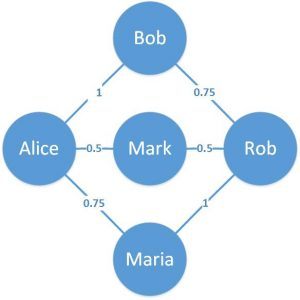
Here, we can see that the edges have weights associated with them, which provides them with relative meaning.
3. Graph Representations
A graph can be represented in different forms, such as an adjacency matrix and an adjacency list. Each one has its pros and cons in a different setup.
We’ll introduce these graph representations in this section.
3.1. Adjacency Matrix
An adjacency matrix is a square matrix with dimensions equivalent to the number of vertices in the graph.
The matrix elements typically have values of 0 or 1. A value of 1 indicates adjacency between the vertices in the row and column, and a value of 0 otherwise.
Let’s see what the adjacency matrix looks like for our simple graph from the previous section:
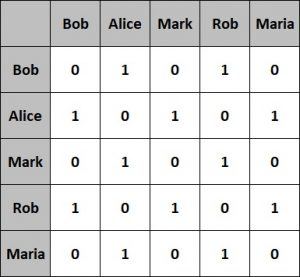
This representation is fairly easy to implement and efficient to query. However, it’s less efficient in terms of space occupied.
3.2. Adjacency List
An adjacency list is nothing but an array of lists. The array size is equivalent to the number of vertices in the graph.
The list at a specific array index represents the adjacent vertices of the vertex represented by that array index.
Let’s see what the adjacency list looks like for our simple graph from the previous section:
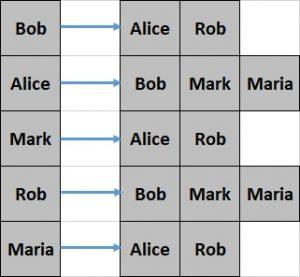
This representation is comparatively difficult to create and less efficient to query. However, it offers better space efficiency.
We’ll use the adjacency list to represent the graph in this tutorial.
4. Graphs in Java
Java doesn’t have a default implementation of the graph data structure.
However, we can implement the graph using Java Collections.
Let’s begin by defining a vertex:
class Vertex {
String label;
Vertex(String label) {
this.label = label;
}
// equals and hashCode
}The above definition of vertex just features a label, but this can represent any possible entity such as Person or City.
Also, note that we have to override the equals() and hashCode() methods as these are necessary to work with Java Collections.
As we discussed earlier, a graph is nothing but a collection of vertices and edges that can be represented as either an adjacency matrix or an adjacency list.
Let’s see how we can define this using an adjacency list here:
class Graph {
private Map<Vertex, List<Vertex>> adjVertices;
// standard constructor, getters, setters
}As we can see, the class Graph is using Map from Java Collections to define the adjacency list.
Several operations are possible on a graph data structure, such as creating, updating, or searching through the graph.
We’ll go through some of the more common operations and see how we can implement them in Java.
5. Graph Mutation Operations
To start with, we’ll define some methods to mutate the graph data structure.
Let’s define methods to add and remove vertices:
void addVertex(String label) {
adjVertices.putIfAbsent(new Vertex(label), new ArrayList<>());
}
void removeVertex(String label) {
Vertex v = new Vertex(label);
adjVertices.values().stream().forEach(e -> e.remove(v));
adjVertices.remove(new Vertex(label));
}These methods simply add and remove elements from the vertices Set.
Now, let’s also define a method to add an edge:
void addEdge(String label1, String label2) {
Vertex v1 = new Vertex(label1);
Vertex v2 = new Vertex(label2);
adjVertices.get(v1).add(v2);
adjVertices.get(v2).add(v1);
}This method creates a new Edge and updates the adjacent vertices Map.
Similarly, we’ll define the removeEdge() method:
void removeEdge(String label1, String label2) {
Vertex v1 = new Vertex(label1);
Vertex v2 = new Vertex(label2);
List<Vertex> eV1 = adjVertices.get(v1);
List<Vertex> eV2 = adjVertices.get(v2);
if (eV1 != null)
eV1.remove(v2);
if (eV2 != null)
eV2.remove(v1);
}Next, let’s see how we can create the simple graph we drew earlier using the methods we’ve defined so far:
Graph createGraph() {
Graph graph = new Graph();
graph.addVertex("Bob");
graph.addVertex("Alice");
graph.addVertex("Mark");
graph.addVertex("Rob");
graph.addVertex("Maria");
graph.addEdge("Bob", "Alice");
graph.addEdge("Bob", "Rob");
graph.addEdge("Alice", "Mark");
graph.addEdge("Rob", "Mark");
graph.addEdge("Alice", "Maria");
graph.addEdge("Rob", "Maria");
return graph;
}Finally, we’ll define a method to get the adjacent vertices of a particular vertex:
List<Vertex> getAdjVertices(String label) {
return adjVertices.get(new Vertex(label));
}6. Traversing a Graph
Now that we have the graph data structure and functions to create and update it, we can define some additional functions for traversing the graph.
We need to traverse a graph to perform any meaningful action, such as search within the graph.
Two possible ways to traverse a graph are depth-first traversal and breadth-first traversal.
6.1. Depth-First Traversal
A depth-first traversal starts at an arbitrary root vertex and explores vertices as deep as possible along each branch before exploring vertices at the same level.
Let’s define a method to perform the depth-first traversal:
Set<String> depthFirstTraversal(Graph graph, String root) {
Set<String> visited = new LinkedHashSet<String>();
Stack<String> stack = new Stack<String>();
stack.push(root);
while (!stack.isEmpty()) {
String vertex = stack.pop();
if (!visited.contains(vertex)) {
visited.add(vertex);
for (Vertex v : graph.getAdjVertices(vertex)) {
stack.push(v.label);
}
}
}
return visited;
}Here, we’re using a Stack to store the vertices that need to be traversed.
Let’s run a JUnit test for depth-first traversal using the graph we created in the previous subsection:
@Test
public void givenAGraph_whenTraversingDepthFirst_thenExpectedResult() {
Graph graph = createGraph();
assertEquals("[Bob, Rob, Maria, Alice, Mark]",
GraphTraversal.depthFirstTraversal(graph, "Bob").toString());
}Please note that we’re using vertex “Bob” as our root for traversal here, but this can be any other vertex.
6.2. Breadth-First Traversal
Comparatively, a breadth-first traversal starts at an arbitrary root vertex and explores all neighboring vertices at the same level before going deeper into the graph.
Now, let’s define a method to perform the breadth-first traversal:
Set<String> breadthFirstTraversal(Graph graph, String root) {
Set<String> visited = new LinkedHashSet<String>();
Queue<String> queue = new LinkedList<String>();
queue.add(root);
visited.add(root);
while (!queue.isEmpty()) {
String vertex = queue.poll();
for (Vertex v : graph.getAdjVertices(vertex)) {
if (!visited.contains(v.label)) {
visited.add(v.label);
queue.add(v.label);
}
}
}
return visited;
}Note that a breadth-first traversal uses Queue to store the vertices that need to be traversed.
Let’s run a JUnit test for breadth-first traversal using the same graph:
@Test
public void givenAGraph_whenTraversingBreadthFirst_thenExpectedResult() {
Graph graph = createGraph();
assertEquals("[Bob, Alice, Rob, Mark, Maria]",
GraphTraversal.breadthFirstTraversal(graph, "Bob").toString());
}Again, the root vertex, “Bob” here, can just as well be any other vertex.
7. Initializing and Printing a Graph
We can initialize and print a graph using a Java application. Let’s create a Java application called AppToPrintGraph for this purpose. We need to add a method to this class to initialize a graph. Let’s add a class method createGraph so that we can call it without first creating an instance of the class:
static Graph createGraph() {
Graph graph = new Graph();
graph.addVertex("Bob");
graph.addVertex("Alice");
graph.addVertex("Mark");
graph.addVertex("Rob");
graph.addVertex("Maria");
graph.addEdge("Bob", "Maria");
graph.addEdge("Bob", "Mark");
graph.addEdge("Maria", "Alice");
graph.addEdge("Mark", "Alice");
graph.addEdge("Maria", "Rob");
graph.addEdge("Mark", "Rob");
return graph;
}As per the requirement of a Java application, it should include the main method; therefore, let’s add one. In the main method, let’s call the createGraph method to initialize a graph, traverse it breadth-first, and print the result of the traversal:
public static void main(String[] args) {
Graph graph = createGraph();
Set result = GraphTraversal.breadthFirstTraversal(graph, "Bob");
System.out.println(result.toString());
}We can run this application to print the example graph to the standard output:
[Bob, Maria, Mark, Alice, Rob]8. Java Libraries for Graphs
It’s not necessary to implement the graph from scratch in Java at all times. Several open-source and mature libraries offer graph implementations.
We’ll go through some of these libraries in the next few subsections.
8.1. JGraphT
JGraphT is one of the most popular libraries in Java for graph data structure. It allows the creation of a simple graph, directed graph, and weighted graph, among others.
Additionally, it offers many possible algorithms for the graph data structure. One of our previous tutorials covers JGraphT in much more detail.
8.2. Google Guava
Google Guava is a set of Java libraries that offer a range of functions including graph data structure and its algorithms.
It supports creating simple Graph, ValueGraph, and Network. These can be defined as Mutable or Immutable.
8.3. Apache Commons
Apache Commons is an Apache project that offers reusable Java components. These include Commons Graph, a toolkit for creating and managing graph data structures. The toolkit also provides common graph algorithms for operating on the data structure.
8.4. Sourceforge JUNG
Java Universal Network/Graph (JUNG) is a Java framework that provides an extensible language for modeling, analysis, and visualization of any data that can be represented as a graph.
JUNG supports many algorithms that include routines such as clustering, decomposition, and optimization.
These libraries provide a number of implementations based on the graph data structure. There are also more powerful frameworks based on graphs, such as Apache Giraph, currently used at Facebook to analyze the graphs formed by their users, and Apache TinkerPop, commonly used on top of graph databases.
9. Conclusion
In this article, we discussed the graph as a data structure along with its representations. We defined a very simple graph in Java using Java Collections and also defined common traversals for the graph. Furthermore, we learned to initialize and print a graph.
We also talked briefly about various libraries available in Java outside the Java platform that provide graph implementations.


















