

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
How Does Particle Swarm Optimization Work?
Last updated: May 8, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll understand how Particle Swarm Optimization (PSO) works. Mainly, we’ll explore the origin and the inspiration behind the idea of PSO. Then, we’ll detail the algorithm procedure. We’ll start by defining its concept and continue by mathematically modeling its parameters.
Then, we’ll continue by listing the sequence of the executing steps and representing the corresponding flowchart. Finally, we’ll present domains of applications where PSO can be used to solve real-world problems. A finishing conclusion will summarize our tutorial.
2. Origin and Inspiration
The diversity in nature and its systems has driven diversity in the emerging algorithms and techniques created by imitating how nature works. We can divide them into two groups. The first one uses inputs inspired by biological entities (cells or neurons) behavior such as neural networks, genetic algorithms, and evolutionary algorithms. The second one uses inputs inspired by biological systems’ behavior, such as ants, lions, bees, etc. We call them Swarm Intelligence algorithms. In this tutorial, we’ll study the PSO algorithm and how it works.
Particle Swarm Optimization is a meta-heuristic that belongs to the category of swarm intelligence algorithms. It was first proposed by James Kennedy and Russell Eberhart in 1995 and is applied to various search and optimization problems. Let’s start by defining the three keywords in the definition. What is an optimization problem? What is a meta-heuristic? And what is swarm intelligence?
We can simply define optimization by a commonly used concept that locates the optimum solution among a set of feasible solutions. It has a fundamental role in determining some variables with certain resource limits.
Meta-heuristics are high-level procedures that aren’t dependent on the problem instance or example. We can say they are heuristics with more generalized rules than standard heuristics and can solve multiple mathematical problems.
As for swarm intelligence, we can define it as artificial intelligence that is based on the collective behavior of decentralized and self-organized systems. These systems typically comprise a population of individuals (agents) interacting locally and with their environments. The agents’ cooperation creates a collective intelligence that demonstrates great results when applied in the computer networks field. We can find many popular swarm intelligence algorithms such as ant colonies, bird flocking, fish schooling, grey wolves, ant lions, whales, etc.
3. Particle Swarm Optimization
Let’s look closely at the concept of work and the mathematical model of the PSO algorithm. Then, let’s show its representative flowchart.
3.1. Concept- How It Works
PSO is a population-based technique. It uses multiple particles that form the swarm. Each particle refers to a candidate solution. The set of candidate solutions co-exists and cooperates simultaneously. Each particle in the swarm flies in the search area, looking for the best solution to land. So, the search area is the set of possible solutions, and the group (swarm) of flying particles represents the changing solutions.
Throughout the generations (iterations), each particle keeps track of its personal best solution (optimum), as well as the best solution (optimum) in the swarm. Then, it modifies two parameters, the flying speed (velocity) and the position. Specifically, each particle dynamically adjusts its flying speed in response to its own flying experience and that of its neighbors. Similarly, it tries to change its position using the information of its current position, velocity, the distance between the current position and personal optimum, and the current position and swarm optimum.
The swarm of particles (birds) continues moving toward a promising area until getting the global optimum, which will solve the optimization problem. Following, we’ll define the mathematical models, illustrated by the used parameters and the equations, to build the PSO algorithm.
3.2. Parameters
The main parameters used to model the PSO are:
 : a swarm of
: a swarm of  particles
particles : an individual in the swarm with a position
: an individual in the swarm with a position  and velocity
and velocity  ,
, ![i \in [|1,n|]](/wp-content/ql-cache/quicklatex.com-d245a62a9d2294fd05a67c0b6650628d_l3.svg "Rendered by QuickLaTeX.com")
- : the position of a particle
- : the velocity of a particle
 : the best solution of a particle
: the best solution of a particle : the best solution of the swarm (Global)
: the best solution of the swarm (Global) : fitness function
: fitness function : acceleration constants (cognitive and social parameters)
: acceleration constants (cognitive and social parameters) : random numbers between 0 and 1
: random numbers between 0 and 1 : the iteration number
: the iteration number
3.3. Mathematical Models
Two main equations are involved in the PSO algorithm. The first (equation 1) is the velocity equation, where each particle in the swarm updates its velocity using the computed values of the individual and global best solutions and its current position. The coefficients of  and
and  are acceleration factors related to the individual and social aspects.
are acceleration factors related to the individual and social aspects.
They are known as trust parameters, with modeling how much confidence a particle has in itself and modeling how much confidence a particle has in its neighbors. Together with the random numbers  and
and  , they define the stochastic effect of cognitive and social behaviors:
, they define the stochastic effect of cognitive and social behaviors:
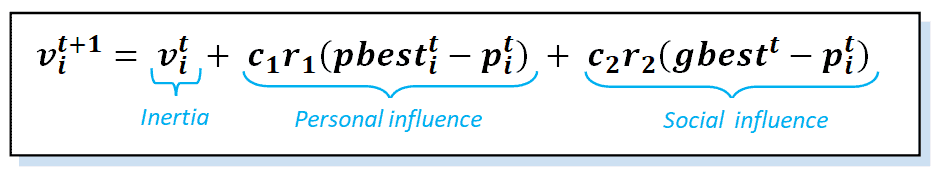
The second (equation 2) is the position equation, where each particle updates its position using the newly calculated velocity:
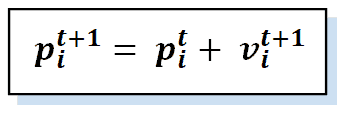
The parameters of position and velocity are co-dependent, i.e., the velocity depends on the position and vice-versa. We can illustrate the moving particle in the following figure:
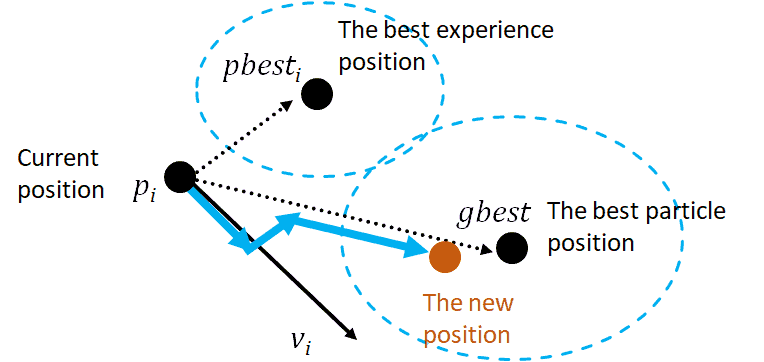
3.4. Steps and Flowchart
After explaining the PSO principle and its mathematical model, let’s examine the PSO execution steps:
- Initialize algorithm constants.
- Initialize the solution from the solution space (initial values for position and velocity).
- Evaluate the fitness of each particle.
- Update individual and global bests (
 and ).
and ). - Update the velocity and position of each particle.
- Go to step 3 and repeat until the termination condition.
A flowchart detailing and organizing the execution steps can help us understand the PSO method:
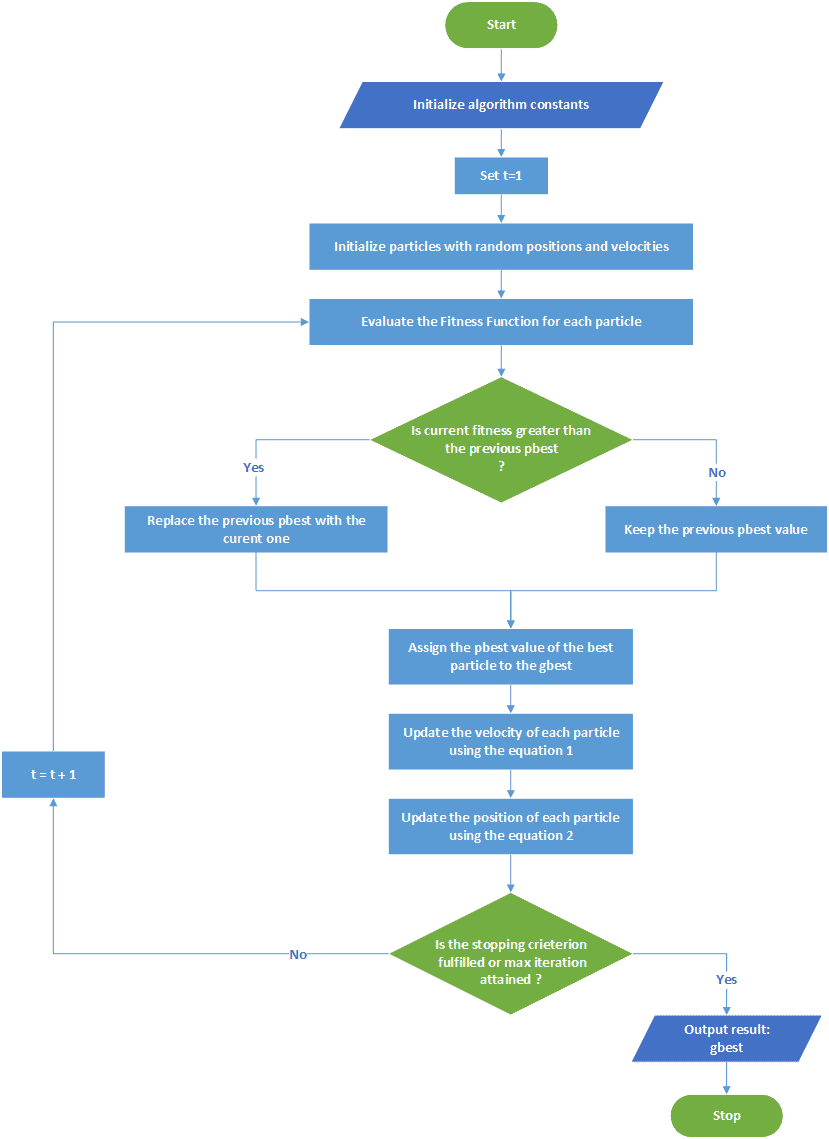
4. PSO Applications
PSO is known to be advantageous in many aspects. First, it is simple to implement. Second, it is derivative-free and uses very few parameters. Third, it has an efficient global search process. That is why we can say that it has been a popular technique exploited to solve several optimization problems. Let’s dig into some examples:
- The training of neural networks which is used to identify Parkinson’s disease, extract rules from fuzzy networks, or recognize images
- The optimization of electric power distribution networks
- Structural optimization, where the construction industry targets the optimal shape, size, and topology during the design process
- System identification in biomechanics
5. Training a Neural Network Using PSO
In this section, we’ll explore a practical example of Particle Swarm Optimization (PSO) applied to the Iris flower classification problem, one of the most famous datasets in pattern recognition.
We won’t use high-level machine learning libraries like SciKit-Learn but will implement our neural network using NumPy. This approach allows us to see the mechanics of neural network training through PSO without the abstraction layers provided by comprehensive machine learning frameworks.
5.1. Implementing the Neural Network
Our model consists of a simple two-layer neural network: one hidden layer and one output layer. The input layer will take features from the Iris dataset, including measurements such as sepal length, sepal width, and petal length.
The hidden layer will use a sigmoid activation function to introduce non-linearity, and the output layer will also apply a sigmoid function to produce probabilities for three possible Iris species.
Also, for simplicity, we’ll represent the network as a vector of weights and convert it to a multi-dimensional array for the forward propagation step of the training and when in the prediction function.
To avoid repetition, all the necessary imports are listed in the first code section and won’t be repeated further:
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.metrics import accuracy_score, confusion_matrix
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
"""Compute softmax values for each set of scores in x."""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum(axis=1, keepdims=True)
def train_network_forward_propagation(weights, hidden_layer_size, X_train_data, y_train_data):
hidden_layer_weights = weights[:4*hidden_layer_size].reshape(4, hidden_layer_size)
output_layer_weights = weights[4*hidden_layer_size:].reshape(hidden_layer_size, 3)
# Forward pass
hidden_layer_input = np.dot(X_train_data, hidden_layer_weights)
hidden_layer_output = sigmoid(hidden_layer_input)
output_layer_input = np.dot(hidden_layer_output, output_layer_weights)
output_layer_output = sigmoid(output_layer_input)
# Loss calculation (Mean Squared Error)
k = y_train_data - output_layer_output
loss = np.mean(np.square(k))
return loss
def evaluate_network(weights, hidden_layer_size, X_test, y_test):
hidden_layer_weights = weights[:4*hidden_layer_size].reshape(4, hidden_layer_size)
output_layer_weights = weights[4*hidden_layer_size:].reshape(hidden_layer_size, 3)
# Forward pass
hidden_layer_input = np.dot(X_test, hidden_layer_weights)
hidden_layer_output = sigmoid(hidden_layer_input)
output_layer_input = np.dot(hidden_layer_output, output_layer_weights)
output_layer_output = sigmoid(output_layer_input)
# Convert logits to probabilities
predictions = softmax(output_layer_output)
# Choose the class with the highest probability
predicted_classes = np.argmax(predictions, axis=1)
true_classes = np.argmax(y_test, axis=1)
true_classes = np.asarray(true_classes)
# Calculate accuracy
accuracy = accuracy_score(true_classes, predicted_classes)
# Generate a confusion matrix
conf_matrix = confusion_matrix(true_classes, predicted_classes)
return accuracy, conf_matrix5.2. PSO Training
We need to map the Neural Network to the PSO algorithm to train the network using PSO. In this case, each particle represents a potential neural network. Therefore, each particle will be a vector of weights, given that the Iris dataset has four features; hence, we need four weights for the inputs, and since we’re predicting one of three classes, we need three outputs.
The area where we have some flexibility is the size of the hidden layer, so for a three-neuron hidden layer, we’ll need 21 weights (4 inputs x 3 neurons + 3 neurons x 3 outputs).
The objective function we’ll optimize is the loss calculated in the feed-forward training function, and the final trained network is the output of the PSO, in other words, the particle with the best result will be our trained neural network:
def pso_iris(num_particles, num_iterations, hidden_layer_size, X_train_data, y_train_data):
# PSO parameters
num_dimensions = 4 * hidden_layer_size + hidden_layer_size * 3
positions = np.random.rand(num_particles, num_dimensions) - 0.5 # Initialize positions
velocities = np.zeros_like(positions) # Initialize velocities
pbest_positions = np.copy(positions)
pbest_scores = np.array([train_network_forward_propagation(p, hidden_layer_size, X_train_data, y_train_data) for p in positions])
gbest_position = pbest_positions[np.argmin(pbest_scores)]
gbest_score = np.min(pbest_scores)
# PSO loop
w = 0.5 # inertia
c1 = 2 # cognitive parameter
c2 = 2 # social parameter
for i in range(num_iterations):
for j in range(num_particles):
r1, r2 = np.random.rand(2)
velocities[j] = w * velocities[j] + c1 * r1 * (pbest_positions[j] - positions[j]) + c2 * r2 * (gbest_position - positions[j])
positions[j] += velocities[j]
current_score = train_network_forward_propagation(positions[j], hidden_layer_size, X_train_data, y_train_data)
if current_score < pbest_scores[j]:
pbest_scores[j] = current_score
pbest_positions[j] = positions[j]
# Update global best
current_gbest_score = np.min([train_network_forward_propagation(p, hidden_layer_size, X_train_data, y_train_data) for p in positions])
if current_gbest_score < gbest_score:
gbest_score = current_gbest_score
gbest_position = positions[np.argmin([train_network_forward_propagation(p, hidden_layer_size, X_train_data, y_train_data) for p in positions])]
print(f"Iteration {i+1} - Best Loss: {gbest_score}")
print("Optimal Weights Found by PSO:", gbest_position)
return gbest_positionFor the PSO component, each particle in the swarm will represent a potential solution, consisting of a complete set of weights for the neural network. Our objective function, which evaluates the fitness of each particle, will be based on the mean squared error between the predicted and actual outputs. This error calculation will guide the PSO in searching for the optimal set of weights that minimizes the error, effectively training our neural network.
To train our neural network, we’ll initialize a swarm of particles, where each particle represents a unique set of initial weights for the network. The PSO iteratively adjusts these weights based on the particles’ individual and collective experiences.
Adjustments are made according to the PSO’s operations, including calculating velocities and updating positions (weights) influenced by the best solutions.
5.3. Running Our Example
First, we’ll load the Iris data set and change the classes to one hot encoding and scaling, then split the data set into training and testing sets.
Then, we call the PSO function with parameters for the number of particles, training cycles, and neurons in the hidden layer and save the result as our trained neural network model.
Once training is complete, we evaluate our model’s performance using a separate test dataset. This evaluation is crucial to understand the model’s generalizability and ensure it performs well on unseen data. Our evaluation metrics include accuracy and a confusion matrix, which provide a comprehensive view of the model’s strengths and weaknesses across the different classes of the Iris dataset:
# Load and prepare the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
encoder = OneHotEncoder()
y_onehot = encoder.fit_transform(y.reshape(-1, 1))
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=42)
# Standardize the data
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Assuming `best_position` contains the optimal weights found by PSO
hidden_layer_size = 6
iris_classifier = pso_iris(30, 50, hidden_layer_size, X_test_scaled, y_test)
accuracy, conf_matrix = evaluate_network(iris_classifier, hidden_layer_size, X_test_scaled, y_test)
print("Accuracy:", accuracy)
print("Confusion Matrix:\n", conf_matrix)With a six-neuron hidden layer, 30 particles, and 50 PSO cycles, our model achieves 90% accuracy and misclassified only 3 instances of the second category.
6. Conclusion
In this tutorial, we studied PSO, a well-known swarm intelligence method to solve optimization problems in different domains. We explained the origin and the natural inspiration of the algorithm. Then, we defined the mathematical equations and parameters adopted to model the algorithm.
After giving an illustrative flowchart of the PSO execution, we finish the tutorial by presenting some examples of the algorithm applications.