Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: November 9, 2022

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this article, we’ll review the Grey Wolf Optimization (GWO) algorithm and how it works. As we can conclude from the name, this is a nature-inspired metaheuristic that is based on the behavior of a pack of wolves. Similar to other nature-inspired metaheuristics such as genetic algorithm and firefly algorithm, it explores the search space in hope of finding an optimal solution.
In summary, this is an iterative method that is used for optimization problems.
The inspiration for this algorithm is the behavior of the grey wolf, which hunts large prey in packs and relies on cooperation among individual wolves. There are two interesting aspects of this behavior:
The grey wolf is a highly social animal with the result that it has a complex social hierarchy. This hierarchical system, where wolves are ranked according to strength and power, is called “dominance hierarchies”. Therefore, there are the alphas, betas, deltas, and omegas.
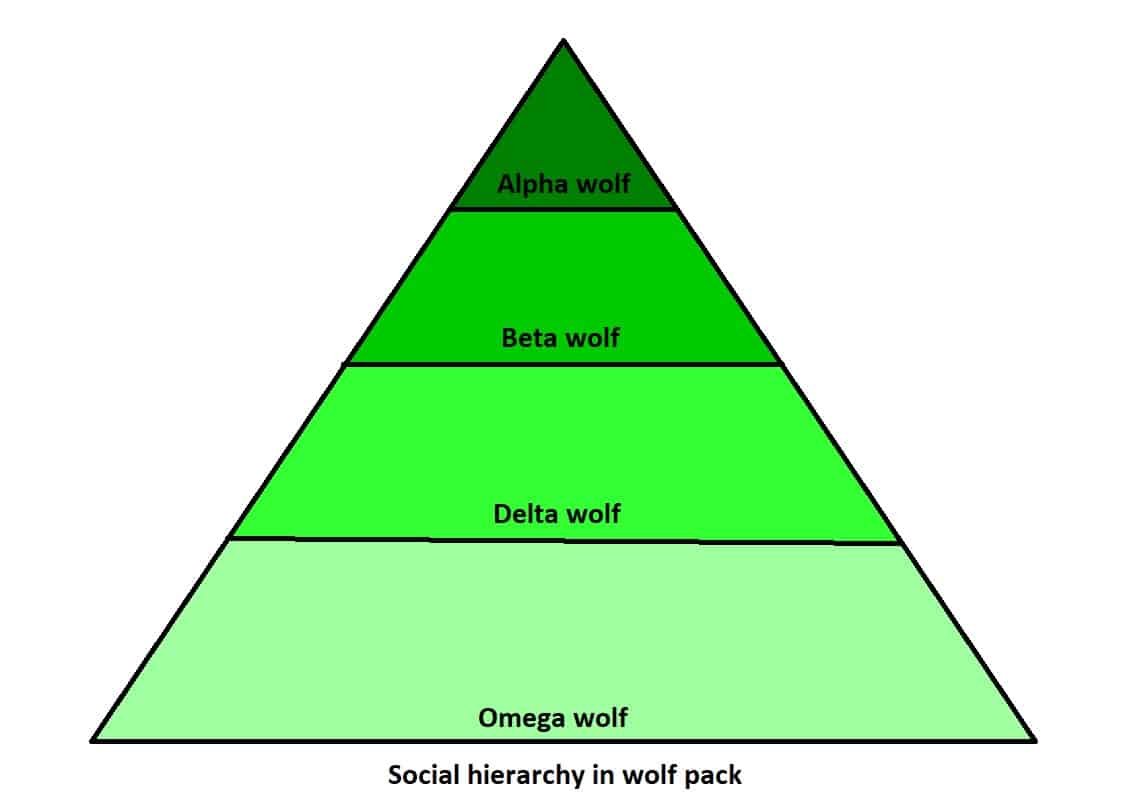
Besides social hierarchy, grey wolves have a very specific way of hunting with a unique strategy. They hunt in packs and work together in groups to separate the prey from the herd, then one or two wolves will chase after and attack the prey while the others chase off any stragglers.
Muro et al. describe the hunting strategy of the wolf pack and it includes:
Applying the previously described methodology to our optimization problem, at each step, we’ll denote respectively the three best solutions by alpha, beta, and delta, and other solutions by omega. Basically, it means the optimization process goes with the flow of the three best solutions. Also, the prey will be the optimal solution of the optimization.
Most of the logic follows the equations:
(1) 
(2) 
where  denotes current iteration,
denotes current iteration,  and
and  are coefficient vectors,
are coefficient vectors,  is the position vector of the prey and
is the position vector of the prey and  is the position of wolf . Vectors and
is the position of wolf . Vectors and  are equal to:
are equal to:
(3) 
(4) 
where components of  are linearly decreased from 2 to 0 through iterations and
are linearly decreased from 2 to 0 through iterations and  ,
,  are random vectors with values from
are random vectors with values from ![[0,1]](/wp-content/ql-cache/quicklatex.com-4ddc1168784a8b723604919df78ae658_l3.svg "Rendered by QuickLaTeX.com") , calculated for each wolf at each iteration. Vector controls the trade-off between exploration and exploitation while always adds some degree of randomness. This is necessary because our agents can get stuck in the local optima and most of the metaheuristics have a way of avoiding it.
, calculated for each wolf at each iteration. Vector controls the trade-off between exploration and exploitation while always adds some degree of randomness. This is necessary because our agents can get stuck in the local optima and most of the metaheuristics have a way of avoiding it.
Since we don’t know the real position of the optimal solution, depends on the 3 best solutions and the formulas for updating each of the agents (wolfs) are:
(5) 
(6) 
(7) 
where is the current position of the agent and  is the updated one. The formula above indicates that the position of the wolf will be updated accordingly the to best three wolves from the previous iteration. Notice that it won’t be exactly equal to the average of the three best wolves but because of the vector , it adds a small random shift. This makes sense because, from one side, we want that our agents are guided by the best individuals and from another side, we don’t want to get stuck in the local optima.
is the updated one. The formula above indicates that the position of the wolf will be updated accordingly the to best three wolves from the previous iteration. Notice that it won’t be exactly equal to the average of the three best wolves but because of the vector , it adds a small random shift. This makes sense because, from one side, we want that our agents are guided by the best individuals and from another side, we don’t want to get stuck in the local optima.
Finally, the pseudocode of GWO is:
algorithm GreyWolfOptimizer(max_iterations):
// INPUT
// n = the number of wolves in the pack
// max_iterations = the maximum number of iterations for the optimization process
// OUTPUT
// X_alpha = the best found agent
X <- Initialize the grey wolf population with n agents
Initialize a, A, and C
Calculate the fitness of each search agent
X_alpha <- the best search agent
X_beta <- the second best search agent
X_delta <- the third best search agent
t <- 0
while t < max_iterations:
for each search agent in X:
Randomly initialize r1 and r2
Update the position of the current search agent by the equation (7)
Update a, A, and C
Calculate the fitness of all search agents
Update X_alpha, X_beta, and X_delta
t <- t + 1
return X_alphaNotice that the time complexity of the algorithm is dependent on the number of iterations, agents, and size of the vectors but generally we can approximate the time complexity as  , where
, where  is the number of iterations and
is the number of iterations and  is the number of agents.
is the number of agents.
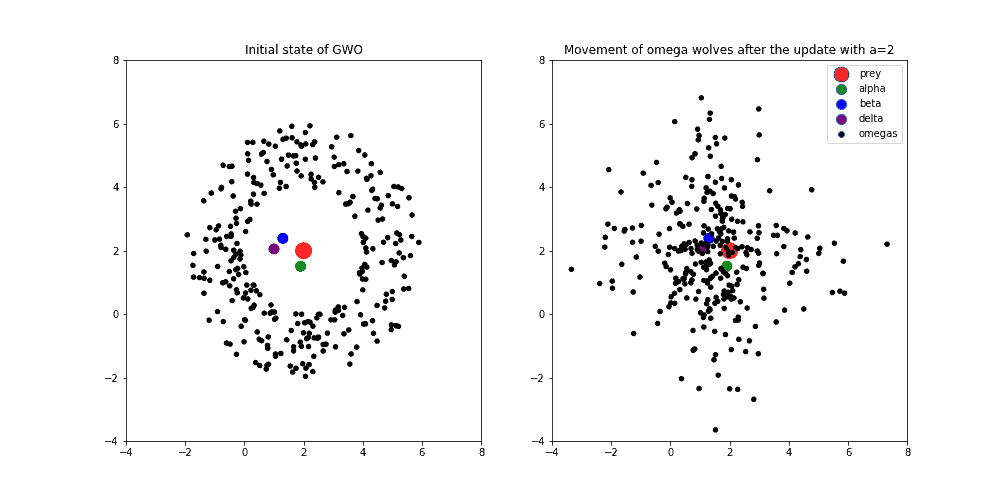
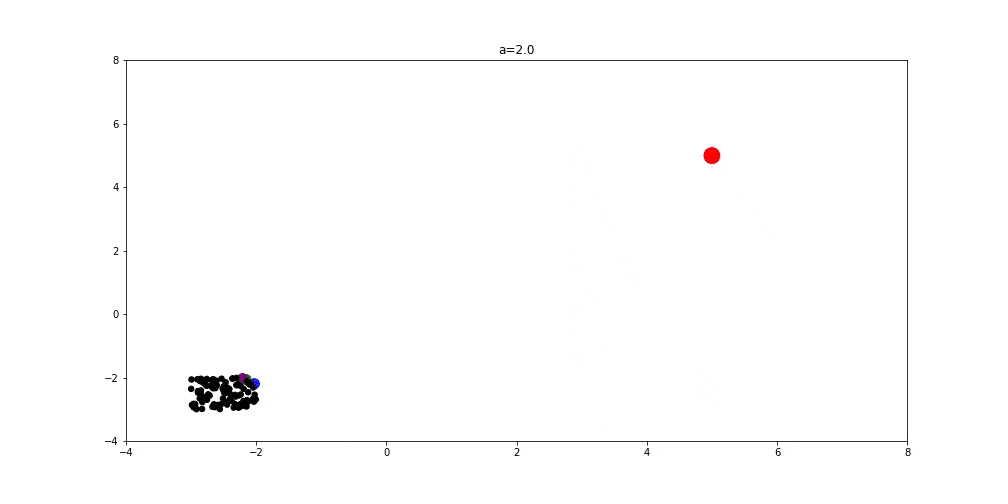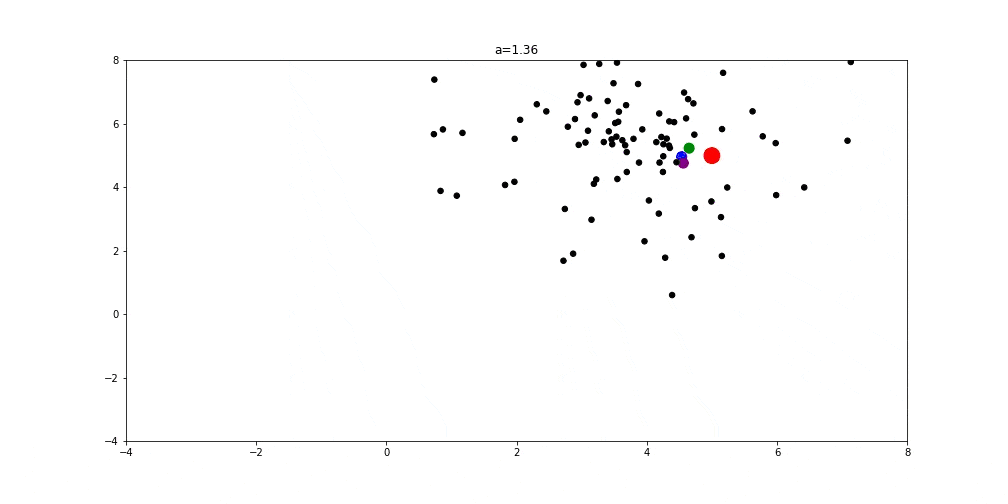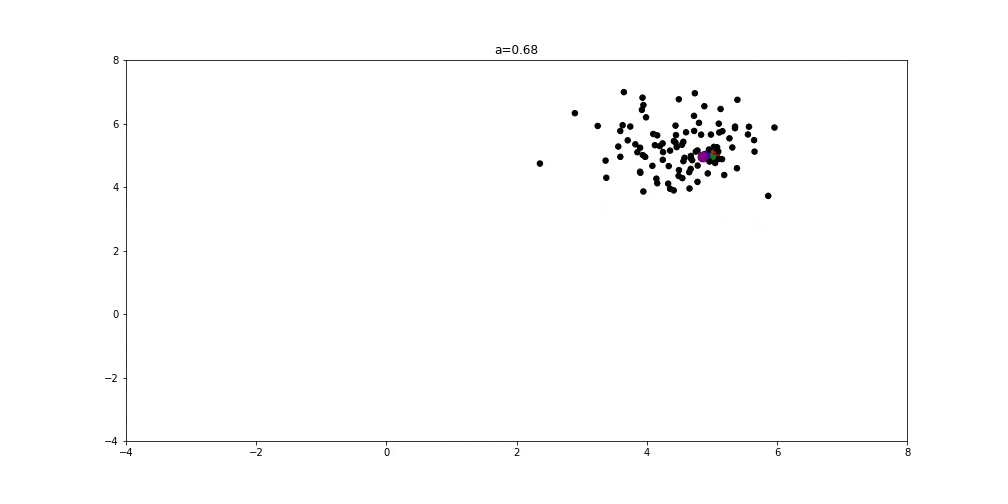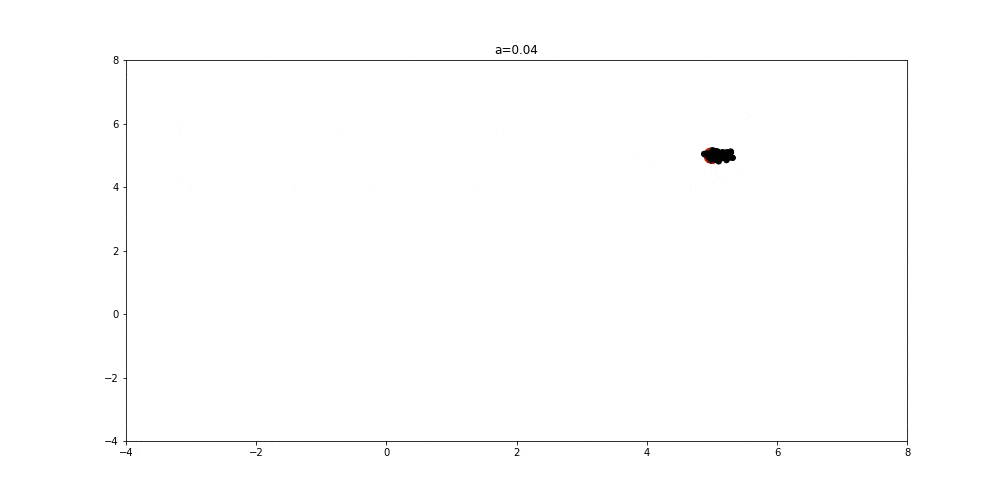
In order to better understand this algorithm, we’ll present one concrete example of the wolf pack behavior. In the image below (left), we can see the initial state of the agents, where prey or optimal solution has a red color. The closest wolves to the prey (alpha, beta, and delta) have a green, blue, and purple color respectively. Black dots represent other wolves (omegas).
Further, if we update the position of omega wolves according to the formulas explained in the previous section, we can observe the behavior of agents in the image below (right). Notice that the variable  that controls the trade-off between exploration and exploitation is set to the value 2. This means that we prefer exploration overexploitation:
that controls the trade-off between exploration and exploitation is set to the value 2. This means that we prefer exploration overexploitation:
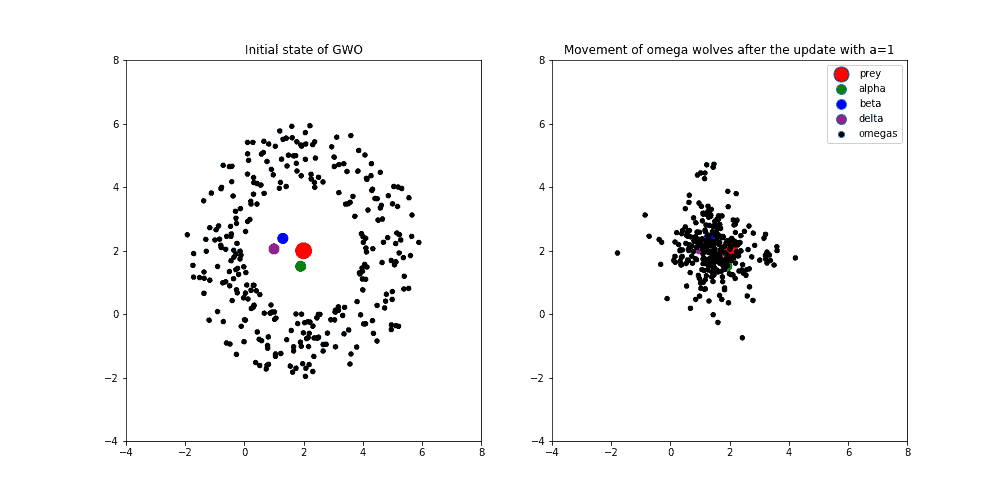
Secondly, the next image shows the behavior of the wolf pack when the variable is set to value 1. Usually, this means that we’re in the middle of the optimization process and the exploitation process increasingly appears:
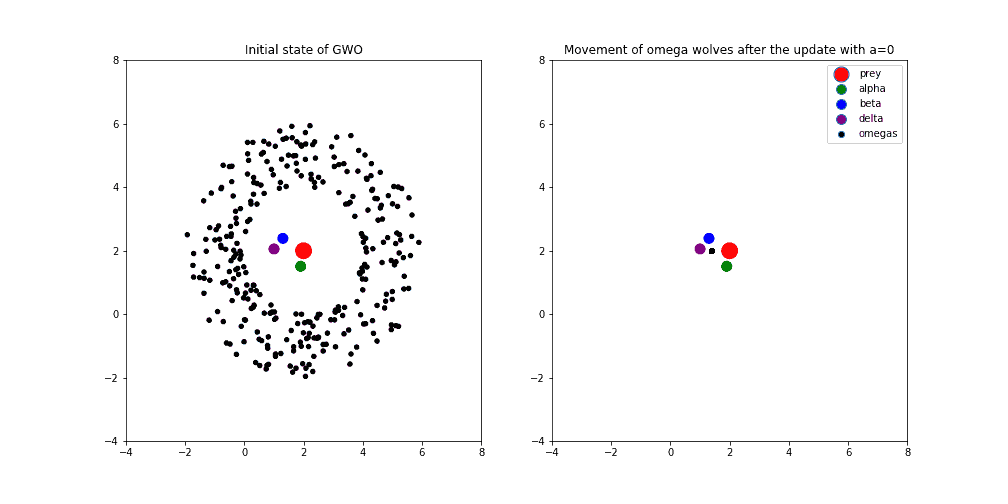
Finally, in the image below, the variable is equal to 0. It means that the optimization process is at the end and we’re hopefully converging towards the optimal solution following the best three wolves. We can see how omega wolves are gathering between the best three wolves, around the point that geometrically represents centroid between alpha, beta, and delta agents:
Notice that we didn’t update the position of alpha, beta, and delta agents just because of the comparison with the omegas. Otherwise, we update the position of all agents, and after that, we select new alpha, beta, and delta. After all, the convergence of GWO agents might look like the animation below:
In general, we can use this algorithm to solve a lot of different optimization problems. Below, we’ll mention only some of them that could be useful in machine learning.
One interesting application might be hyperparameter tuning of any machine learning algorithm. The main idea behind hyperparameter tuning is to find an optimum set of values for parameters in order to maximize the performance of a given algorithm.
For instance, using GWO we could optimize hyperparameters of Gradient Boosting. In that case, we can construct the position vector in a way where each of the vector components for a value has a particular hyperparameter. For example, X = (learning rate, number of trees, maximum depth). The parameters don’t have to have a numeric value at all because we can always define our own metrics for calculating the distance between agents.
Another application of GWO that is also related to machine learning is feature selection. The algorithm works by constructing a set of possible features and iteratively modifying these features based on some performance measure until the desired solution is found.
This approach is a lot cheaper in terms of time complexity since the complexity for choosing the best subset of features increases exponentially with every additional variable. This is because the total number of subsets of a set with elements is  . It means that if we have 30 different features as an input into the machine learning algorithm, as a result, the number of possible subsets of 30 features is
. It means that if we have 30 different features as an input into the machine learning algorithm, as a result, the number of possible subsets of 30 features is  !
!
Thus, it would be more feasible to represent 30 features as a binary vector with a size of 30 (each bit is one particular feature, 1 indicates that the feature is included and 0 that it is not). That binary vector represents the position of the agent and could be easily used by GWO or any other metaheuristics.
Besides the above examples, the GWO has been successfully used in solving various problems such as:
In this article, we’ve described the intuition and logic behind the GWO algorithm to provide a better understanding of how we can apply it to solve some optimization problems. We introduced this algorithm because it is quite effective, yet simple enough to be easily understood. The article explores what a GWO is, an example of how it works and provides several key considerations on the examples of applications.