

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Difference Between Parallel and Distributed Computing
Last updated: May 19, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In the ever-growing realm of computing, the quest for faster and more efficient processing has led to developing sophisticated techniques. Two prominent approaches that have emerged are parallel computing and distributed computing. While both aim to harness the collective power of multiple processing units, they differ significantly in their architecture and application.
In this tutorial, we’ll provide a comprehensive introduction to parallel and distributed computing, exploring how they differ from each other in various aspects.
2. What Is Parallel Processing?
Parallel processing is a computing technique where multiple operations or tasks are carried out simultaneously rather than sequentially. It involves breaking down a problem into smaller parts and executing those parts simultaneously across multiple processing units or cores. This approach aims to improve computational speed and efficiency by harnessing the power of multiple processing resources.
In what follows, we’ll explore various types of parallel processing architectures.
2.1. Task Parallelism
In this approach, different tasks are executed simultaneously. Each task may be independent or dependent on others but can be executed concurrently.
2.2. Data Parallelism
Here, the same operation is performed on multiple pieces of data concurrently. This is often used in applications such as image processing, where the same operation needs to be applied to each pixel independently. The below figure illustrates a typical process that involves both task and data parallelism:
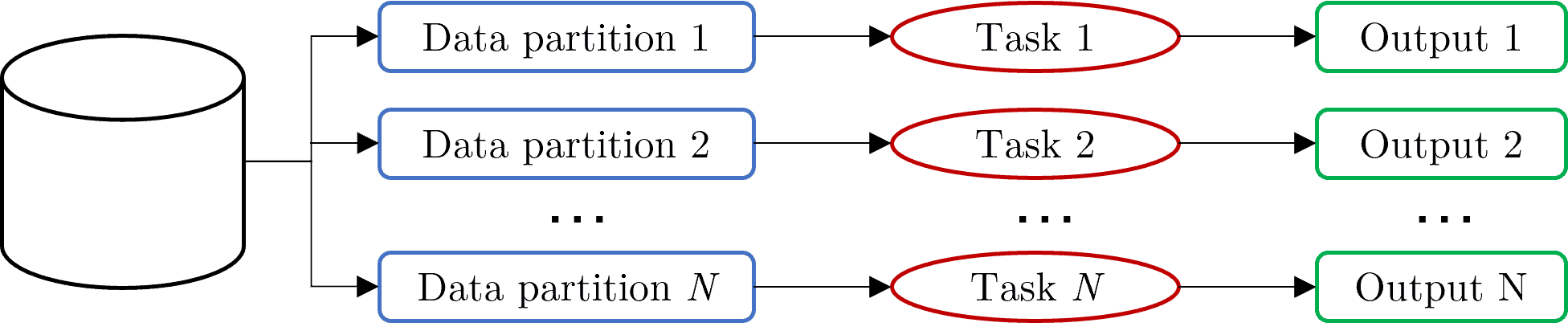
2.3. Instruction-level Parallelism
Instruction-level parallelism involves executing multiple instructions from a single instruction stream simultaneously. Modern processors often employ techniques like pipelining and superscalar execution to achieve this.
2.4. Bit-level Parallelism
Bit-level parallelism is the simultaneous processing of multiple bits or binary digits within a computer’s word.
Parallel processing can be implemented in various ways, including multi-core processors, multi-processor systems, clusters of computers, and specialized hardware accelerators like GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units). It is commonly used in high-performance computing (HPC), scientific simulations, data analytics, machine learning, and many other applications requiring significant computational power.
3. What Is Distributed Computing?
Distributed computing is a model in which computation is spread across multiple interconnected computers to achieve a common goal. Unlike traditional centralized computing, where one powerful machine handles all tasks, distributed computing decentralizes the processing load, distributing it among multiple nodes or machines that communicate and collaborate over a network.
Distributed computing takes the concept of parallel processing a step further. It leverages multiple independent computers, often geographically dispersed and interconnected through a network, to work collaboratively on a single large task. Unlike parallel computing, which focuses on a single machine with tightly coupled processors, distributed computing deals with loosely coupled, autonomous machines.
Distributed computing can take various forms. In what follows, we’ll discover the possible forms of distributed computing.
3.1. Client-Server Architecture
Clients request services or resources from centralized servers. This model is common in web applications, where clients (such as web browsers) interact with remote servers (such as web servers) over the Internet.
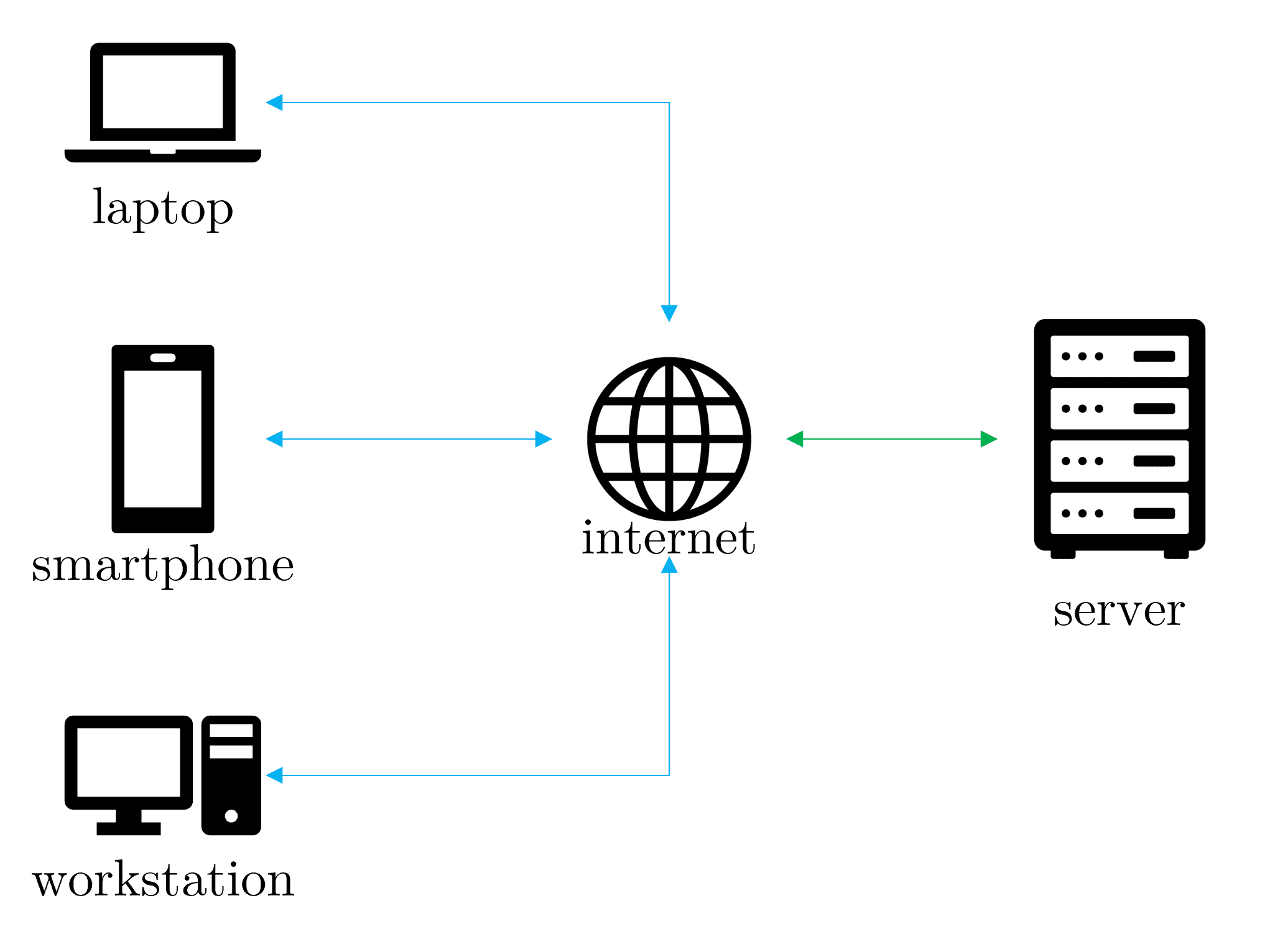
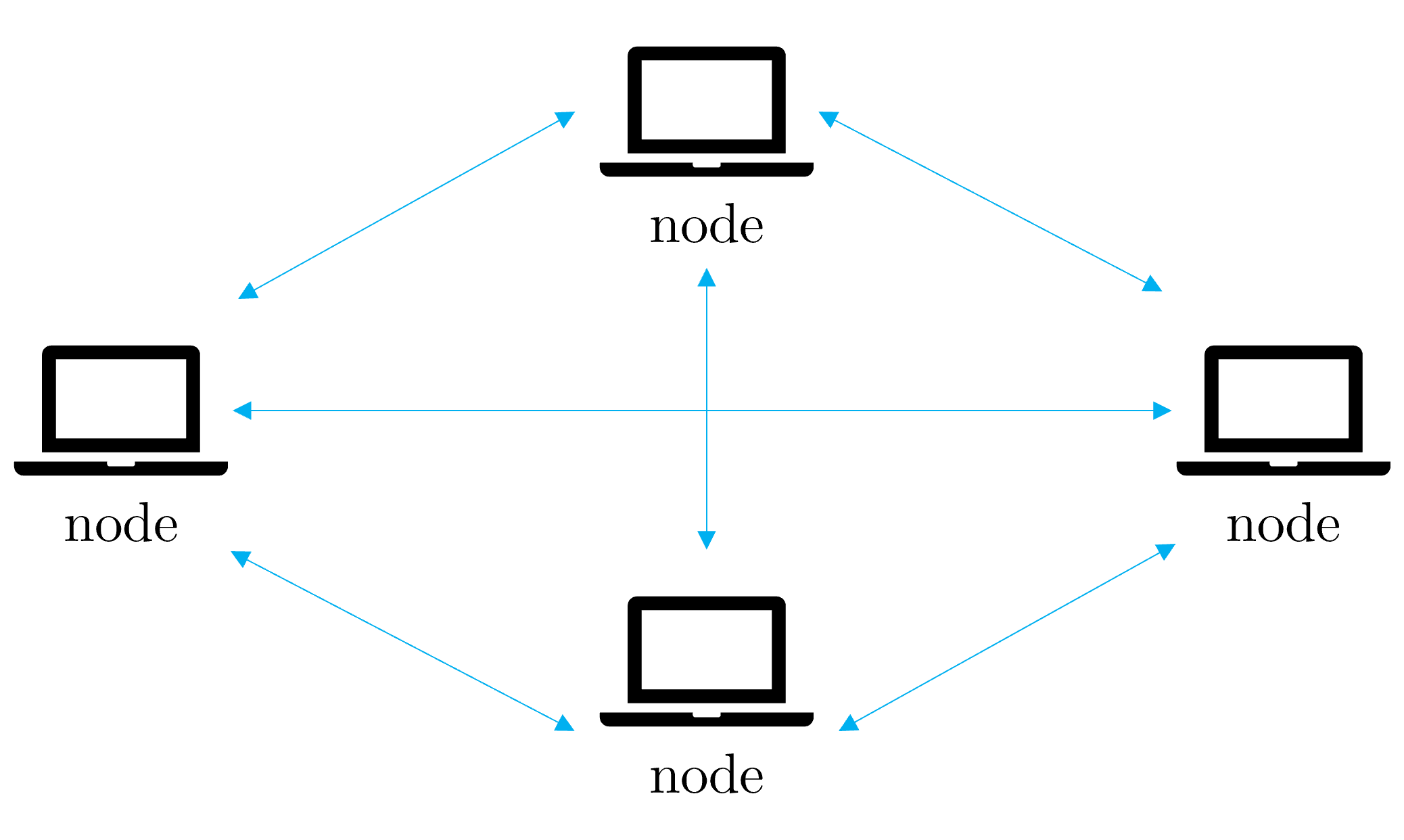
3.2. Peer-to-Peer (P2P) Networks
In P2P networks, nodes act both as clients and servers, sharing resources and data directly with each other without the need for centralized coordination:
3.3. Grid Computing
Grid computing connects geographically distributed resources to perform large-scale computations. It typically involves pooling together resources from multiple organizations or institutions to solve complex problems:
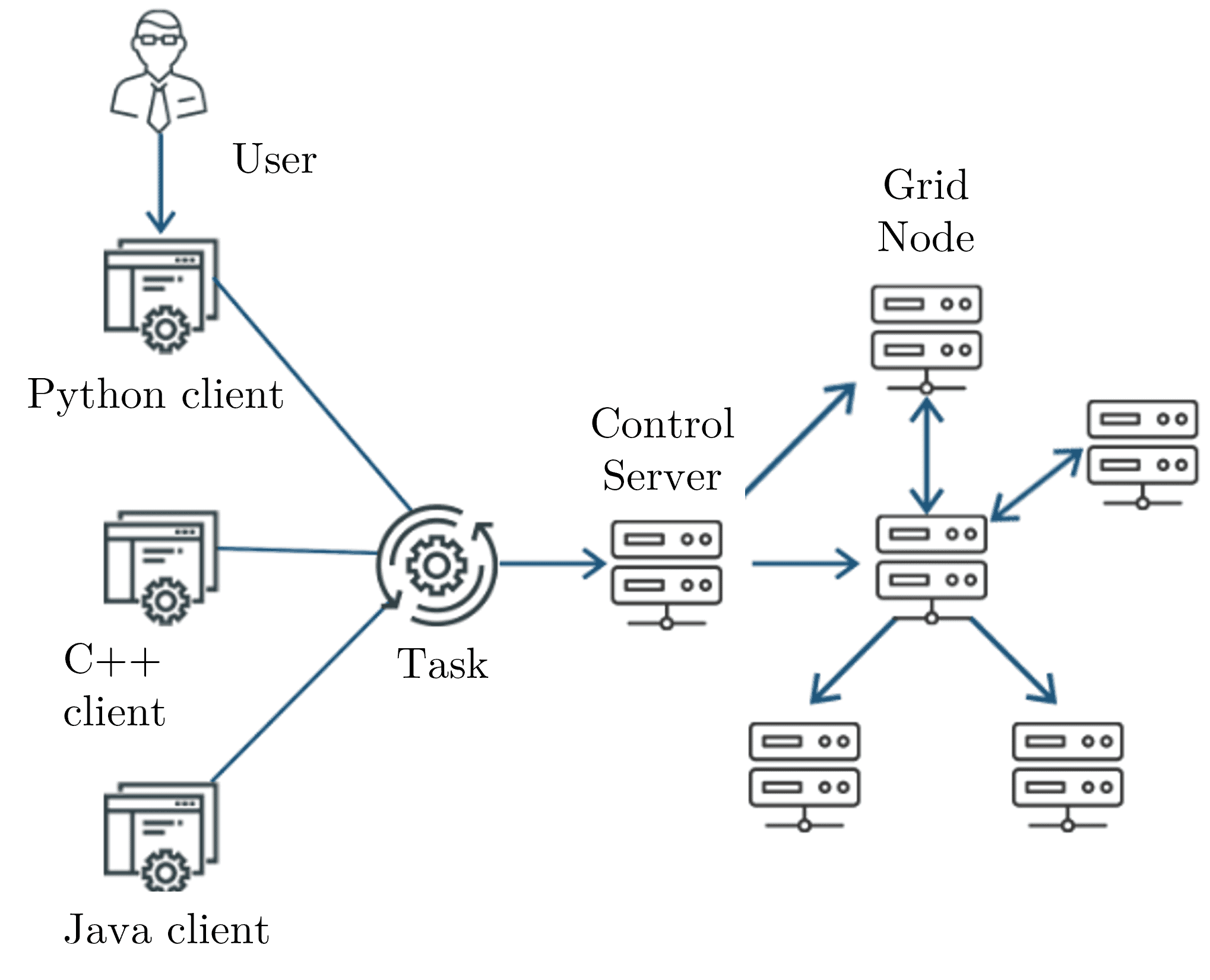
3.4. Cluster Computing
Cluster computing involves connecting multiple computers (nodes) within a single location to work together as a unified system:
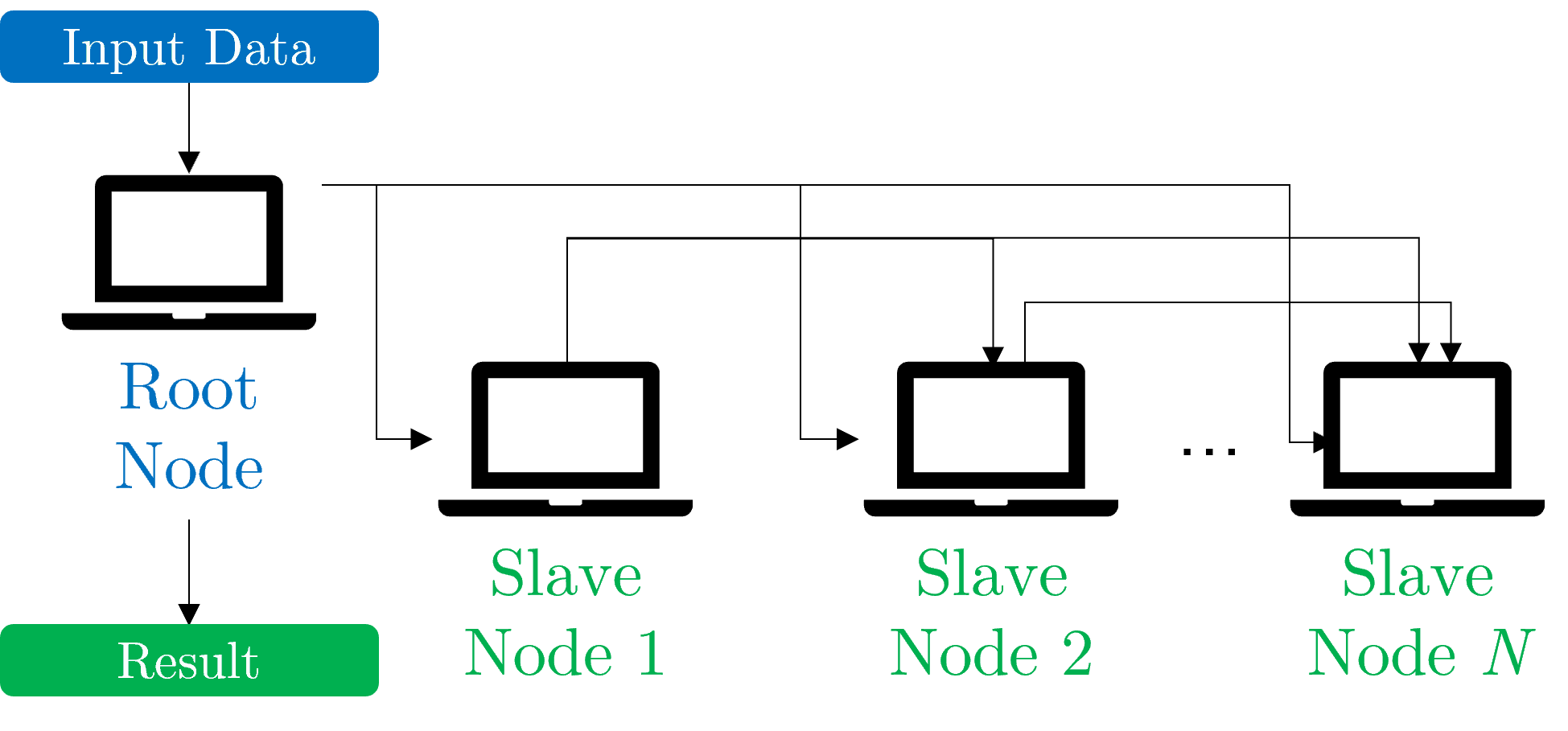
Clusters are often used in scientific research, data analysis, and high-performance computing (HPC) applications.
The primary advantage of distributed computing lies in its ability to scale. By adding more computers to the network, the processing power and storage capacity can be significantly increased. This makes it ideal for tackling massive computational problems that would be intractable for a single computer. Distributed computing enables scalable, fault-tolerant, and cost-effective solutions for handling large volumes of data and performing computationally intensive tasks. It’s widely used in various domains, including cloud computing, big data processing, distributed databases, and distributed artificial intelligence.
4. A Side-by-Side Comparison Between Parallel and Distributed Computing
While parallel and distributed computing shares similarities in executing tasks concurrently, they differ in architecture, communication, coordination, scalability, fault tolerance, and deployment. Here’s a table summarizing the key differences between parallel and distributed computing:
| Aspect | Parallel Computing | Distributed Computing |
|---|---|---|
| Architecture | Typically, it involves multiple processors or cores within a single machine. | Involves multiple machines or nodes connected over a network. |
| Communication | Process communication typically occurs via shared memory or inter-process communication mechanisms within the same machine. | Communication between nodes occurs over a network, often using message passing or remote procedure call (RPC) mechanisms. |
| Coordination | A single controlling process or thread typically manages coordination between parallel tasks. | Coordination between distributed nodes requires more sophisticated mechanisms due to the system’s distributed nature. |
| Scalability | Limited scalability due to the finite number of processors or cores within a single machine. | Offers higher scalability potential by adding more nodes to the distributed system. |
| Fault Tolerance | Generally lacks built-in fault tolerance mechanisms beyond redundancy in hardware or software. | Often incorporates fault tolerance mechanisms such as redundancy, replication, and error detection to handle node failures or network issues. |
| Deployment | Suitable for tasks that can benefit from parallel execution within a single machine, such as multi-core processors. | Suitable for tasks that require cooperation between multiple machines or nodes, such as large-scale data processing or distributed systems. |
| Examples | Scientific simulations, image processing on multi-core CPUs, GPU computing. | Cloud computing, distributed databases, peer-to-peer networks, grid computing. |
5. Choosing the Right Tool for the Job
The choice between parallel and distributed computing depends on the specific needs of the computational task. Here are some key factors to consider:
- Problem size and complexity: If the problem is large and can be naturally divided into independent subtasks, parallel computing might be a good choice. For extremely large or complex problems that require significant resources, distributed computing offers a more scalable solution
- Available hardware: Parallel computing leverages a single machine with multiple cores, while distributed computing can utilize a network of existing computers
- Communication overhead: The communication between processors or computers can introduce overhead in both approaches. However, the cost of message passing in distributed systems can be higher compared to the internal communication within a single machine in parallel computing
- Programming complexity: Programming parallel applications can be challenging due to the need for synchronization and managing shared memory access. Distributed systems also require additional programming effort for handling communication and fault tolerance
6. Conclusion
In the article, we comprehensively introduced parallel and distributed computing and discovered the differences between these two paradigms.
In conclusion, parallel and distributed computing represent powerful techniques for harnessing the collective power of multiple processing units. Understanding their strengths, weaknesses, and key differences is essential for selecting the right tool for the job and unlocking their true potential.