

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’re going to study the difference between two frequently misused terms in the writings on machine learning: Big Data and Data Mining.
We’ll first study them individually, and then see why the media often confuse them with one another. At the end of this tutorial, we’ll be familiar with the primary similarities and differences of the two concepts and know when to use one over the other.
This article supports the idea that “Big Data” has recently resuscitated as a common term because of a perceived “lagging-behind” of the amount of computational power vis-à-vis the size of the average dataset.
The term Big Data has become a household word in the last few years but lacks a proper analytical definition. There is, in fact, no mathematical or information-theoretic reason why we should distinguish Big Data from data of any other kind:

It’s not, for example, clear how many rows should a table have in order to belong to the class of “Big Data”, or whether one should use instead non-threshold methods for its categorization.
And yet we see frequent use of the word in the public discourse, which means that it must have some identifiable connotations and advantages, however inaccurate they might be from a technical perspective.
Let’s, therefore, dig into the history of the word, and see how it entered the day-to-day vocabulary.
The first reference in the scientific literature to the term Big Data comes from a paper published in the 1970s.
The paper tackled the problem of factorization of a dataset and proposed a method for doing so that automated the process. At the time, in fact, human analysts performed matrix factorization by eyeballing the best fitting between multiple hypotheses proposed by a computer, regarding possible singular value decompositions for a matrix.
Another mention of the term, originating from the same period, can be found in connection to the handling of geographical datasets. The development of the national oil industry in the United States led to the centralization of large datasets related to drilling and to the operation of the oil wells. This, in turn, started to cause difficulties in their management and processing and thus increased the demand for storage and computation.
The term appeared again in the 1980s when it was used to describe the difficulty in handling large dictionaries for translation and for the construction of what we’d today call knowledge graphs. Again, the term conveyed the idea of a struggle in the management or maintenance of a dataset that was growing in size faster than the number of people who worked on it.
All instances of the initial usage of the term conveyed the idea that, as a dataset grows in size, the dataset administrators would face increasingly harder problems in managing and maintaining it.
The term Big Data is also common today and is, in fact, more popular than ever. Starting from the early 2010s the term has become a common word in the vocabulary of the general population:
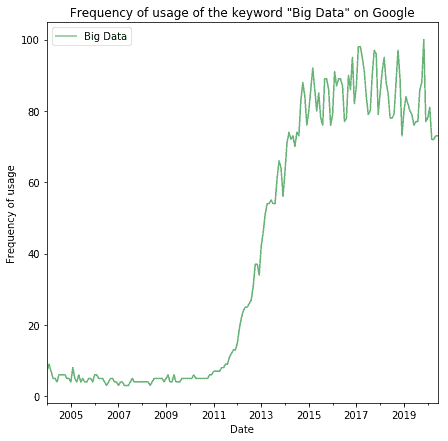
The term hasn’t yet acquired a specific technical meaning which was absent when it started being used. We can, therefore, reason about the causes for the emergence of the term in the first place, and see whether those causes have reappeared in the last few years. If this were the case, they might explain the resurgence of this word in modern times.
As mentioned earlier, when the term first entered the scientific literature, its users would often express through it the idea that the size of datasets grew faster than the capacity by humans and computers to process them. We could, therefore, hypothesize that the same phenomenon is taking place now; and that thus the size of datasets is growing faster than the available computational power.
If this were the case, it would explain why under similar conditions we started using again the same word:
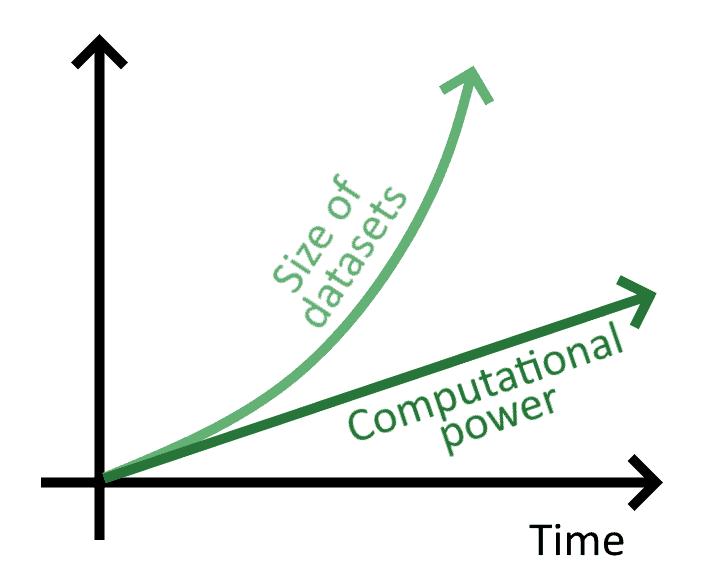
This hypothesis is therefore comprised of three parts:
Let’s see now whether this is the case.
We can have the intuitive feeling that the average size of datasets increases over time. And even though we’re correct, this doesn’t say much about the rate at which these datasets are enlarging. Here we face a significant problem: what dataset or datasets should we choose in order to measure their rate of increase in size over time?
This problem doesn’t have a simple solution because we can’t sample all datasets present everywhere. The approach that is taken in the literature on Big Data is instead to sample the variation in the size of non-random selections of datasets.
These datasets tend to belong to the largest companies and are therefore scarcely representative of the whole population of digital datasets. From this follows an important warning: Our understanding of the growth of datasets derives largely from the study of this phenomenon over a non-random sample of observations. This means that the considerations we derive from it are likely affected by selection bias and may be wrong.
If we, however, still look at the databases held by the major companies, we definitely see that these have a general tendency to increase very fast.
It appears therefore that, short of considerations on selection bias, the average size of datasets and user bases is increasing faster than linearly. A factor that affects this faster-than-linear growth is the increased access to the Internet by the general population, which we can use as a proxy measure for the average size of datasets held by companies.
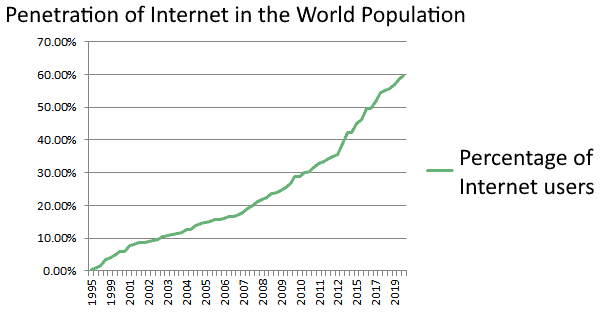
Internet penetration in the world has been increasing steadily, with an acceleration right during the years in which the word “Big Data” resurfaced:
If all data in datasets were inserted by humans, this would in itself explain the increased size of the average dataset in recent years. We know however those humans are not the only source of data, but that IoT devices also are. The question then becomes as to which one contributes more to the increase in the size of datasets.
This is somewhat of a tricky aspect of the problem. If human users were the ones that input most of the data into datasets, then we could assume that datasets increase as fast as the rate of Internet penetration. However, this is not the case.
IoT devices, one of the primary sources of digital data, are increasing in number significantly faster than the human population:
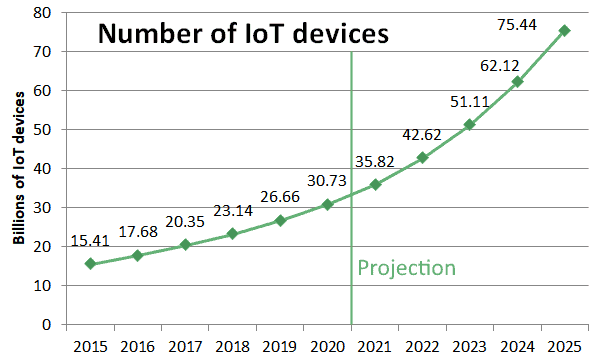
If we compare the two previous graphs for the period between 2015 and 2020, we can observe that Internet penetration has increased from 45% to around 60%, while at the same time the number of IoT devices has doubled.
This suggests that both Internet penetration, on one hand, and IoT devices, on the other, similarly contribute to the amount of data produced.
The rapid growth over time in computational power is a well-established fact, which takes the name of Moore’s law. The law, in its basic formulation, predicts that the available computational power doubles every two years:
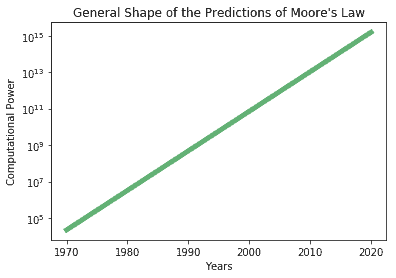
This law has been greatly criticized, and it’s believed that it may no longer be accurate today. For the period that covers the early 2010s, when the word “Big Data” resuscitated, the law was becoming increasingly outdated. Increased spending in R&D didn’t in fact necessarily lead to better processors, due to the fact that traditional processors had reached their physical limitations.
In a linear scale, not logarithmic scale, the observed distribution of computational power over time varied along the lines of this graph:
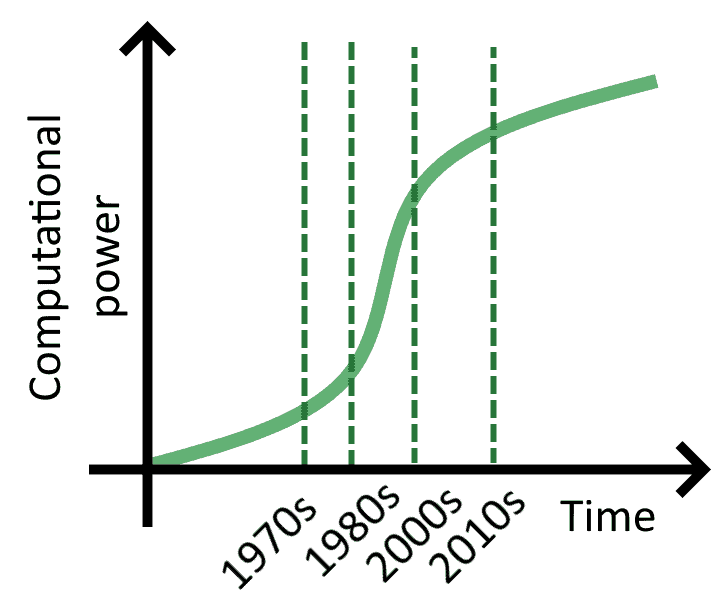
This means that the availability of computational power in the 2010s was not increasing as fast as during the time of Moore Law’s original formulation. A person living in that period, or a person alive today, would perceive their computational power to increase at a rate that lags behind the rate of increase in the data available.
The consideration we can make from the discussion above is that in recent years the datasets have grown at a faster-than-linear and very likely exponential pace. At the same time, the available computational power is also growing but at a lower rate. This means that the available computational power in a given period can’t process all the data produced in that period.
There are two reasons for this:
Regarding the first point, this varies from task to task but it’s generally true. Simple operations for matrix multiplication, for example, require $O(n^3)$ computational time to be performed. This means that if the average dataset doubles in size in a given interval, the computational power required to continue performing matrix operations on that dataset must be increasing eight times during that same interval in order to keep up.
Regarding the second point, we’ve mentioned above how the number of IoT devices is increasing rapidly. These devices constitute a significant portion of the increase in computation. Their sensing components require power, which isn’t thus available in the pool of total computational power for processing datasets.
This means that the increase of datasets only partially depends on the increase in the availability of computational power. If on the basis of the arguments for these sections, we accept the three hypotheses listed above, we can then deduce that the usage of the term Big Data in recent times depends on an increase in the amount of data. The increase in computation, instead, lags behind, generating a computational gap that expresses itself in the term “Big Data”.
We thus argued that the term Big Data resurrected because the needed computational power grows slower than the data. In this context, we can study the difference between “Big Data” and “Data Mining”. The latter concerns the techniques for extracting knowledge from a collection of raw observations, not to sizes of datasets.
The term “data mining” itself comes from the idea that by digging into data one can extract something precious. This something has often the form of knowledge or valuable insights:

The idea behind this term is that, as we dig into a database, we can extract knowledge from it that leads to practical benefits for us or our company. In this sense, data mining and knowledge extraction or knowledge discovery are synonymous with one another.
The term “data mining” should also not be confused with “data scraping” which refers to the very different process of gathering publicly accessible data from the web.
The first usage of the term Knowledge Discovery was done in an AI workshop in 1989. The idea proposed was that researchers could have developed methods for the extraction of knowledge from datasets that didn’t require the usage of domain knowledge. The scientists expected that, by designing efficient search algorithms, they could’ve found unexpected solutions to problems that the constraints of domain-specific knowledge wouldn’t allow.
A specific example of this issue was given, and we can use it to understand what they meant. If we’re searching for efficient routes of transportation for trucks, we could use our knowledge of the fact that trucks don’t run on water to limit the search space on a road network. This type of domain-specific knowledge and associated constraint would, however, prevent the identification of routes crossing frozen rivers in winter:
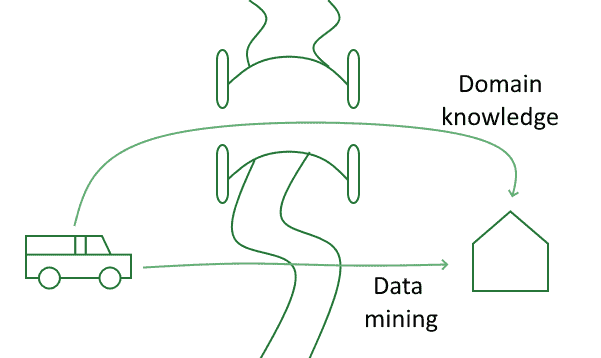
In a context like this Data Mining, but not human knowledge, could be able to find the unexpected solution.
The next step in the development of the joint discipline of Data Mining and Knowledge Discovery consisted then of the foundation of a journal by the same name. Most of the common techniques today used in Data Mining, such as Bayesian Networks and the generalized version of DBSCAN, were initially published in this journal.
One further reason for the terminological confusion is the association of Data Mining with Data Storage. The two terms aren’t equivalent though. We should instead consider Data Storage as the discipline which studies the efficient storage of data in a distributed fashion.
Data Mining can occur on platforms dedicated to Data Storage, but it doesn’t have to. The frequency with which the two go together however led to the emergence of an association between the two.
A common framework for the storage of large datasets in a distributed form is Hadoop. This library isn’t however explicitly dedicated to Data Mining, which is instead better performed through Apache Spark. The MLib library for Spark is dedicated, among other things, to noise filtering in large datasets.
Big Data, therefore, mediates, by its links with both, the indirect connection between Data Mining and Data Storage. But using a specialized framework for Data Storage isn’t strictly a condition to perform Data Mining.
There are a few reasons why the public often confuses the two terms. One, as we’ve seen above, is that “Big Data” is a fuzzy term and largely undefined. As a consequence, it’s significantly prone to overuse.
Other important reasons, which we’ll discuss here more thoroughly, are:
Let’s see each of them in more detail below.
The first reason for the confusion is quite intuitive. It comes from the fact that simple datasets and simple problems require simple analysis to extract insights from them.
Say we want to understand if our marketing campaign for our product is useful. We could divide our sales per year into two periods and check in which one we sold more units:
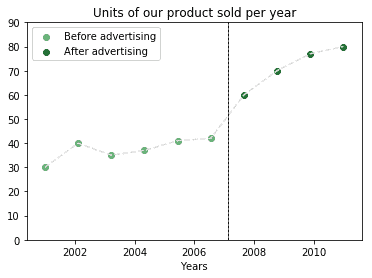
If the task were formulated in the manner above, and if the dataset looked so simple, it’d be trivial to find an answer to that problem. The reality is however that most non-trivial tasks in data analysis require more than an eyeballing of the solution. As a consequence, they may not be solvable without applying Data Mining:
This example shows us how Data Mining is in its own nature associated with large datasets. If we have a large dataset, then we’re likely to use data mining to work on it. This constitutes one reason for the association and confusion between the two terms.
There’s also another reason, which concerns the nature of the organizations which perform Data Mining. These organizations normally hold large datasets, for the motivation indicated above.
In addition to that, though, these organizations also employ teams that are specifically competent for Data Mining. These teams conduct most of the research on both Big Data and Data Mining and push the association between them.
One example is the Data Mining team at Google, which specializes in a branch of Data Mining focused on knowledge graphs, and subsequently called Graph Mining.
Another organization known for research in the sector is CERN. CERN’s Large Hadron Collider produces one of the largest datasets in existence. In connection to this dataset, CERN developed a specialized tool called ROOT, published in open source, that excels on data mining for hierarchical databases.
The relationship between the two terms is thus also that those organizations doing Data Mining also often hold Big Data.
The last reason why we often mix the two terms has to do with noise in datasets. As a dataset increases in size, it also tends to accumulate noise faster than it acquires information. As a consequence, special noise filtering techniques are required to work with large datasets that aren’t needed for smaller ones.
We’ve discussed earlier how we need specialized frameworks for large datasets, and how these often integrate techniques for noise reduction. These are, in turn, Data Mining techniques whose application becomes ever more necessary as a dataset grows. This also leads, in turn, to more reasons for the simultaneous usage of the terms Big Data and Data Mining.
In this article, we’ve studied the main conceptual and technical differences between Big Data and Data Mining.
We’ve first stated that Big Data doesn’t have a specific technical meaning. Instead, its usage originates from a gap. This gap concerns the slow increase in computational power and the fast increase in the size of datasets.
Then we defined Data Mining as the set of techniques required to algorithmically extract and discover knowledge in datasets. We’ve also seen how Data Storage concerns Data Mining only indirectly by means of the former’s relationship with Big Data.
Lastly, we listed the main reasons why the media often confuses the two terms. We’ve seen that this originates from the necessity to conduct Data Mining on all large datasets. This also implies the need to do noise filtering, a Data Mining technique, on all Big Datasets.
We’ve finally seen the organizational aspect of this dichotomy. Most organizations that hold Big Data have teams that study Data Mining. These teams, in turn, conduct most of the research on it and use interchangeably the two terms.