

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Before the arising of the networks, we employed big data centers to process several batches of work in a centralized way. In this scenario, operators manually make the machines ready to execute each work batch.
As the networks and the Internet got popular, we expanded the manners to provide computational services for the users. Now, the client-server model is the most attractive option for implementing centralized computing. Furthermore, distributed computing became a reality.
In this tutorial, we’ll explore the features, advantages, and disadvantages of employing centralized and distributed computing. First, we’ll particularly approach centralized computing systems. Thus, we’ll study distributed computing and its main characteristics. So, we’ll have a systematic summary comparing both computing architectures.
Currently, the most used model of centralized computing is the client-server model. This model considers the existence of a server with large computational capabilities. This server, in turn, is the entity responsible for receiving requests and providing services for several users.
In other words, multiple clients share the same computational resources provided by a centralized server. Thus, the number of clients answered in a certain period can be estimated through the total of computational resources available.
However, other operational characteristics of centralized systems are also important. Examples are their resource allocation and schedule algorithms. These algorithms define how and when to respond to specific requests.
The image below shows a sketch example of a centralized system developed according to the client-server model:
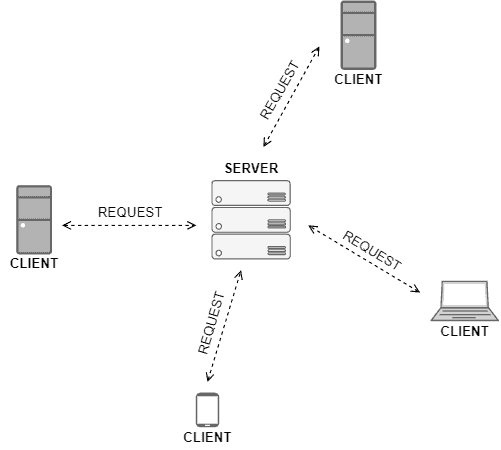
However, we should notice that centralized computing is not restricted to the client-server model. We can have, for example, database servers that only save information periodically collected and do not interact with other systems.
In the following subsection, we’ll study the advantages and disadvantages of centralized computing. The discussions about them do not restrict to a particular model of centralized computing but any system in any model of centralized computing architecture.
The most interesting thing about centralized systems is the clear separation between servers and clients. These entities are loosely coupled. In such a way, we can change the server without necessarily modifying the clients. Furthermore, we can have different clients accessing the same server.
For example, the companies hosting servers can scale computational resources (such as memory or processing power) and make other types of maintenance in the server without modifications in the clients.
Another interesting property is the client detaching from the server. As a unique server provides all the services, detaching a particular client from them is easy: kill the client’s connection and block new ones through a firewall, for instance.
However, centralized systems also have some pitfalls.
The first potential problem is the limitation of the scaling-up process. At some moment, only providing more resources for the server just doesn’t get its performance better. There are other limitations, such as OS or network features, we can not resolve with extra computational resources.
Another pitfall is that the server is a single point of failure. In this way, if the server gets unavailable, the entire service downs even if all the clients are operational. So, exploits, attacks, or any failure are potentially catastrophic.
Although the pitfalls, centralized systems are good options for many applications. Currently, there are several off-the-shelf servers, such as web servers, launchable with few commands, making the deployment of new services easy.
Furthermore, we have multiple open-source data analysis tools for centralized services. These tools enable the owners of the servers to track what is happening with the provided services.
With the described scenario, we have the following examples of services that typically benefit from centralized systems: centralized databases, single-player games, and debugging sandboxes.
Distributed computing refers to having multiple components providing a service. The components in a distributed system, in turn, must intercommunicate to exchange information and data. This communication typically occurs by sending messages through a network.
It is relevant to highlight that when distributed entities make decisions on their own, the system is decentralized. However, when the entities coordinate in some way to make decisions, the system is a distributed system.
There exist different models of distributed computing. For example, we can see the World Wide Web itself as a distributed system model. However, the peer-to-peer model is an excellent one to explore the specific characteristics of distributed systems.
The peer-to-peer model consists of a collection of independent computers connected via a network. Each peer has enough capacity to process data and communicate with other peers, collaborating with a provided service.
In general, someone who wants to access the service communicates with one or more peers to get it. In particular cases, entities requesting the service also become peers providing the service. So, the service organically grows: as bigger the number of entities requesting the service, the greater the service becomes.
The image below exemplifies the presented characteristics of distributed computing in the peer-to-peer model:
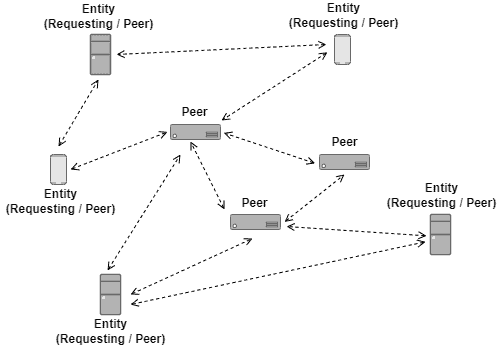
Although distributed computing is a promising architecture in multiple aspects, it includes several challenges. Examples of such challenges are the coordination and the agreement of the distributed entities. Due to these challenges, distributed systems become a specific area in computer science.
In the following subsection, we’ll study the advantages, disadvantages, and use cases of distributed systems, regardless of the adopted model to implement them.
One great benefit of adopting a distributed system is eliminating the single point of failure of centralized computing. In distributed systems, a peer can fail and the service still available.
It means that other peers can assume the tasks of the peer that failed or, at least, properly inform the requesting entities that a particular peer failed. In this way, we can understand a well-designed distributed system as a robust system.
Another benefit of adopting distributed system consists of the scaling up and out processes. So, we can add extra computational resources to the entities in the system (scaling-up). However, we can also add new entities to provide a service in the system (scaling out).
The possibility of adding new entities in the system enables the service providers to tackle specific necessities of particular geographical regions in different ways. For example, localities with a high density of service users can have several close providing entities.
However, distributed systems have multiple pitfalls too.
A relevant difficulty is the management of distributed systems. As we have autonomous entities working together, it is hard to track and monitor each one.
Moreover, we must spread general updates to every entity providing the service, which requires a complex strategy. For instance, we need an update strategy to send and install patches in multiple destinations at a scheduled time.
The different capacities and clocks of the entities in the system are another challenge. Actually, it is not precisely a problem but a characteristic. However, the providers must balance the entities’ capacities, avoiding bottlenecks and underuse scenarios.
Regardless of the challenges, distributed systems have many different uses. For example:
In the previous sections, we studied the characteristics of centralized and distributed computing, focusing on their main advantages and disadvantages.
We could identify many differences between centralized and distributed computing. For example, centralized systems are limited to scale up, while distributed systems can scale up and out.
Furthermore, management tends to be more challenging in distributed systems than centralized ones.
The following table presents a comparison between relevant features of centralized and distributed systems:
| Centralized Computing | Distributed Computing | |
|---|---|---|
| Service Entities | One | Multiple |
| Points of Failure | Dependent (a server failure stops the system) | Independent (an entity failure do not stop the system) |
| Scaling Processes | Up | Up and Out |
| Update Processes | Typically easier than distributed systems | Typically more complex than centralized systems |
| Monitoring Processes | One monitoring point (simple) | Multiple monitoring points (complex) |
| Typical Use Cases | Centralized databases, simulation sandboxes, singleplayer games | Blockchain, BitTorrent networks, multiplayer online games |
In this tutorial, we studied the main differences and similarities between centralized and distributed systems. At first, we learned about centralized systems, their advantages, and their disadvantages. Thus, in a similar way, we explored the characteristics of distributed systems. Finally, we saw a summarized comparison between them.
We can conclude that both studied system architectures have a great potential to be used in the real world. Moreover, we can not just point out which one is better or worse.
In general, the choice between a centralized or distributed architecture relies on the requirements of the aimed system. Thus, we can benefit from their advantages and mitigate the impact of their disadvantages.