

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Machine learning (ML) is a subfield of artificial intelligence that allows computers to learn without being explicitly programmed. Input variables used to develop our model in machine learning are called features.
In this tutorial, we’ll talk about feature selection, also known as attribute selection. It refers to a number of methods for selecting only the useful and important features.
Feature selection is used today in many applications like remote sensing, image retrieval, etc.
In a dataset, objects are described by features. So, most of the time, data are in a tabular form: rows are objects, and columns are features.
However, if there are too many features, our model can incorporate weak or misleading patterns. That happens because, usually, some features aren’t correlated with the target variable and represent noise. If our model outputs predictions based on such features, its accuracy is likely to be subpar. Also, a dataset with many columns slows down the training process.
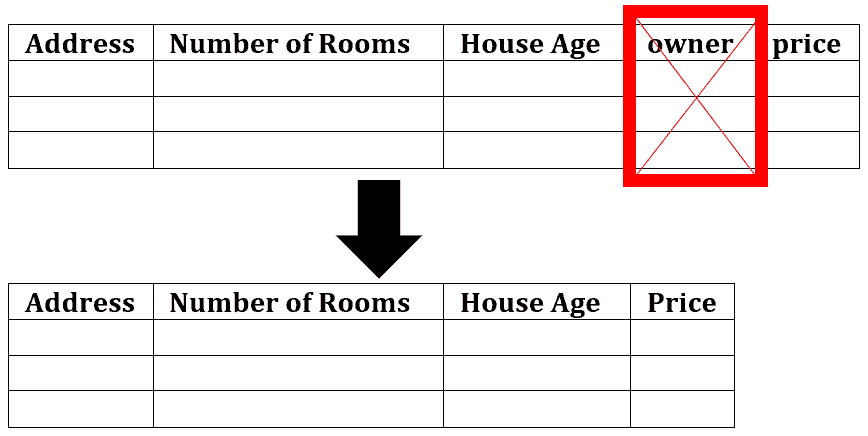
For those reasons, it’s a common practice to use only a subset of available features to avoid learning the noise:

For example, the number of rooms and address are relevant for predicting the sale price of a house, but the current owner’s name isn’t. It can confuse the learning algorithm to let the name affect the sale price prediction, which is likely to lead to wrong results and make the obtained model imprecise. Hence, we can remove the column:
In machine learning, feature selection selects the most relevant subset of features from the original feature set by dropping redundant, noisy, and irrelevant features.
There are several methods of doing so:
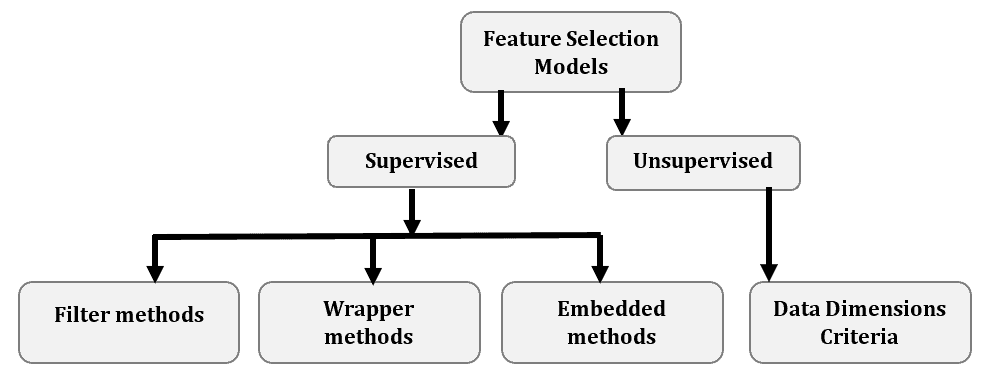
Unsupervised feature selection methods are applied to unlabeled data. An unsupervised selection method rates each feature dimension according to a number of factors, including entropy, variance, and the capacity to maintain local similarity.
On the other hand, we use supervised feature selection methods on labeled data. They determine the features that are expected to maximize the supervised model’s performance.
Supervised feature selection methods can be split into three primary categories based on the feature selection strategy.
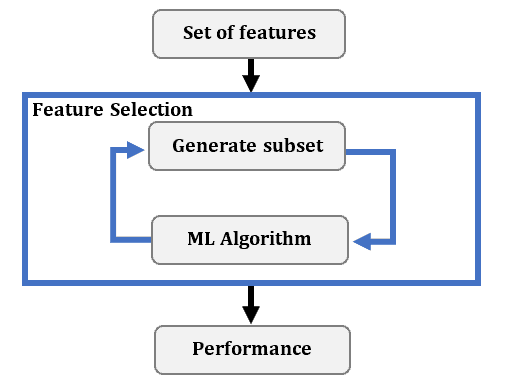
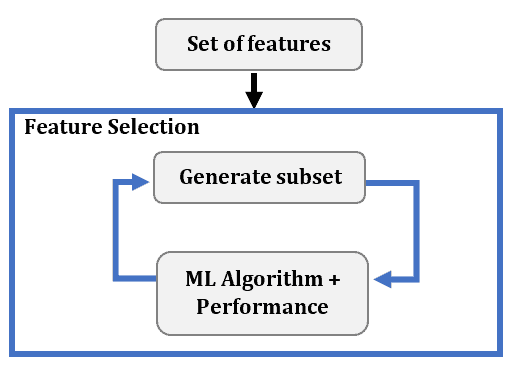
We use a wrapper method after choosing the ML algorithm to use. For each feature subset, we estimate the algorithm’s performance by training and evaluating it using only the features in a subset. Then, we add or remove features based on the estimate. This is an iterative process:
We use a greedy strategy to form feature subsets. In forward wrapper methods, we start from an empty feature set and add the feature maximizing the performance in each step until no substantial improvement is observed. So, if there are  features, we build ML models in the first iteration. Then, we select the feature corresponding to the model with the best performance. In the second iteration, we repeat the process with the remaining
features, we build ML models in the first iteration. Then, we select the feature corresponding to the model with the best performance. In the second iteration, we repeat the process with the remaining  features. We continue like this as long as there’s a significant performance improvement between models with which we end successive iterations.
features. We continue like this as long as there’s a significant performance improvement between models with which we end successive iterations.
Backward methods work the opposite way. They start from the full feature set and remove them one by one. Finally, stepwise methods reconsider features. So, in each iteration, they can remove a feature previously added as well as add a feature discarded in a previous step.
Filter methods use statistical tools to select feature subsets based on their relationship with the target. These methods remove features with low correlation with the target variable before training the final ML model:
In doing so, they compute correlation and estimate the strength of the relationship using the Chi-Square Test, Information Gain, Fisher’s Score, Pearson correlation, ANOVA, variance thresholding, and other statistical tools.
Intrinsic (or embedded) selection happens simultaneously with and is performed implicitly by the ML algorithm of our choice. During training, some steps of the ML algorithm do feature selection:
For instance, this is the case with decision trees. At each node split, they choose the best feature to split the data by. Those choices represent feature selection.
Feature selection methods allow us to:
However, feature selection methods are hard to apply to high-dimensional data. The more features we have, the longer it takes for selection to complete.
Also, there’s the risk of overfitting when there aren’t enough observations.
In this article, we talked about feature selection in machine learning. We use it to remove irrelevant features during a machine learning project. Supervised selection methods are used on labeled and unsupervised ones on unlabeled data.