

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
What Are the Prerequisites for Studying Machine Learning?
Last updated: August 30, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll give a preliminary introduction to the subjects whose knowledge is required to study machine learning and artificial intelligence.
We’ll first learn the distinction between the three professional branches traditionally associated with machine learning. From those differences, we then derive different career paths, which should in turn lead to different specializations.
Secondly, we’ll study the prerequisite disciplines for machine learning. Students in fact require some background knowledge before delving deeply into machine learning specifically. We’ll see exactly what kind of preliminary knowledge we need and why.
Lastly, we’ll discuss some alternative approaches to the study of artificial intelligence. These alternative approaches, albeit less common, give however great professional and market value to those who know them.
At the end of this tutorial, we’ll understand what are the prerequisite subjects to machine learning. We’ll also know their relationship with machine learning in particular, and with artificial intelligence more generally.
2. Data Science, Machine Learning Engineering, and Artificial Intelligence
The contemporary academic and public discourse often uses the terms Data Science, Machine Learning, and Artificial Intelligence interchangeably. The three names, however, point at slightly different concepts, and we should, therefore, keep them separated:
- Data Science is the discipline that relates to the analysis of datasets and the extraction of human-readable insights from them
- Machine Learning is a branch of software engineering; it relates to the construction and tuning of statistical models and data pipelines for practical software applications
- Artificial Intelligence is the encompassing name for the discipline dedicated to the replication of human cognition in artificial systems
They’re therefore related but not equal to one another. More accurately, though, we can say that each of them includes another, with the exception of data science which is the most specific of the three:
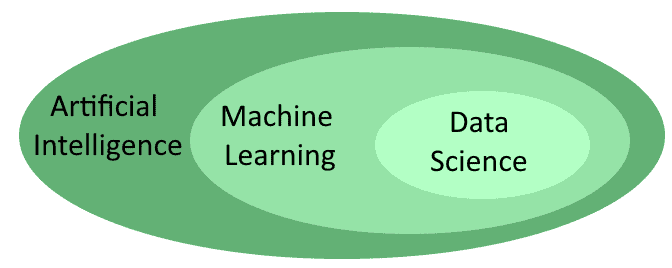
Let’s look at them into some more detail now.
2.1. Who Works in Each Branch?
A Data Scientist is a professional who works in the Data Science department of a company or public institution. The job of a Data Scientist is to process datasets, often significantly large. They also extract insights from them that allow the taking of informed decisions by senior management.
Machine Learning is the domain of software engineers. They’re the professionals competent for developing the databases used by an organization, and also the data pipelines which are associated with their exploitation.
In the sector of pure Artificial Intelligence work, for the most part, are academics and scientists. Surprisingly, many of them don’t belong to departments of Computer Science but work instead with a number of other branches. The most common of these, in addition to the obvious Computer Science are Psychology, Cognitive Science, Neurology, and Philosophy.
2.2. Which Branch Should We Choose?
The selection between these three branches, traditionally linked to machine learning, should be made on the basis of our individual propensity towards the study of the disciplines associated with them:
- Data Science requires deep knowledge of statistics, probability theory, and more in general of mathematics. This may not be accessible to everyone and should be pondered thoroughly when deciding in favor of this career path. It also requires knowledge in another orthogonal subject-matter: many Data Scientists aren’t pure programmers, but rather economists, marketing experts, or social scientists
- Machine Learning engineering is the domain of software engineers and involves writing and testing code in a number of languages. A programmer who is accustomed to relational databases, Java, C++, and Python, but prefers not getting involved with Calculus, should probably consider this career trajectory
- Artificial Intelligence, the pure discipline, is the domain of scientists. A person should approach this sector if they have an interest in fundamental or basic research, and if they’re looking to complement their knowledge in programming or statistics with a good theoretical understanding in other sectors such as cognitive sciences or psychology
Once the decision for a career path is made, we can then identify which disciplines should be known by all three types of professionals. Clearly the depth of knowledge associated with each subject will vary according to our chosen career trajectory, but professionals in all three branches should be familiar with the basics of all traditional prerequisites for machine learning.
3. The Traditional Prerequisites for Machine Learning
All those who want to work in the sector of Machine Learning, regardless of the specific career path they select, need to know at least the following disciplines: Statistics, Probability Theory, Linear Algebra, Calculus, and Programming. Let’s see why that is and what is their relevance for machine learning.
3.1. Statistics
Statistics is the discipline that’s competent for the identification, extraction, and generalization of patterns over a series of observations. While not all “learning” in machine learning is based on statistics, a good portion of it, indeed, is. For this reason, statistics is normally the first subject that should be studied when first approaching the sector of machine learning.
Some concepts taken from statistics are foundational concepts for machine learning. These concepts are:
- Observations, features, and datasets. The unit of analysis in statistics, observation, is also the unit of analysis in machine learning
- Pattern extraction and statistical modeling. The extraction of schemas or relationships between features of observations is one of the most common tasks in machine learning
- Regression analysis. While machine learning has some models that are not shared with statistics, such as neural networks, most of them are however common between the two. This means that a professional in machine learning should be familiar with all techniques commonly used in statistics, in addition to those peculiar to their own discipline
3.2. Statistics and the Problem of Replicability
Knowledge of the theoretical foundations of statistics is also required in order to understand the limitations to machine learning models since these limits are one and the same. One of these limits is particularly important and has to do with the issue of replicability of phenomena.
Statistics is the science concerned with the study of phenomena that repeat themselves, and so is most of the machine learning. Not all phenomena are however replicable, and if they aren’t then machine learning can’t study them. By understanding when statistics can be applied as well as not applied, we can immediately understand when Machine Learning can or can’t be applied, too.
Say we live in the 17th century, and that nobody has ever observed an exploding star yet. Tycho Brahe, the first who studied supernovae, couldn’t have used statistical analysis for his research because the phenomenon studied was at the time unique. That doesn’t mean that a unique phenomenon can’t be studied, but simply that statistical analysis isn’t the way to do it.
3.3. Probability Theory
Probability theory is the discipline concerned with the study of events whose outcome is uncertain. These events may have yet to occur or may have already taken place.
If they haven’t occurred yet, we can normally study the probability of their occurrence or the probability that they possess certain characteristics. If they’ve already taken place in the past, we can in that case use probabilities to indicate our measure of uncertainty.
Probability theory is the basis for the construction of machine learning models that involve uncertainties. Some, and in particular all Bayesian models, are founded upon theoretical assumptions elaborated in probability theory.
As is the case for statistics, machine learning experts need to know probability theory in order to understand when models can’t be applied because of violations in their theoretical assumptions.
3.4. Linear Algebra
Linear algebra is the branch of mathematics that focuses on vectors, vector spaces, matrices, and tensors, and on all of the operations around them. Since most of the activities related to data mining and statistical modeling involve computation over matrices of some sort, we need knowledge of linear algebra in order to work with those models.
Concretely, most of the time spent applying linear algebra to machine learning consists in identifying the correct shapes or dimensionality for matrices and tensors. It’s also however equally important to understand the theory specific to the discipline, because some typical tasks in machine learning, such as dimensionality reduction and Principal Component Analysis, require an understanding of the underlying algebraic rationale for their implementation.
Linear algebra is normally the simplest mathematical discipline to acquire by students of machine learning, and we should, therefore, study it at the same time as statistics or immediately after.
3.5. Calculus
Calculus is the discipline which concerns itself with the study of the continuum, but not one thing in classical computation is continuous in nature. Why is thus calculus often associated with machine learning? To understand why we need to take a step back from computers, and think about scientific modeling in general.
When we model a phenomenon, we have to adopt some assumptions about it that are presumed, but never demonstrated. One of these assumptions relates to what happens to a variable when we don’t look at it; that is when we aren’t performing the measurements associated with it:
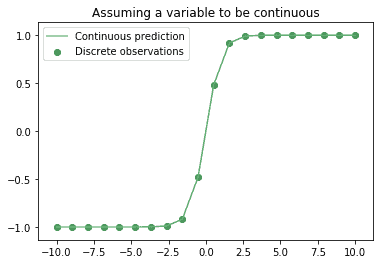
We never, ever, have any guarantee as to what happens to a variable when we aren’t performing measurements. One of the most frequent assumptions is thus that the variables we measure are continuous, and that they might in principle assume all possible values between observations, if we conducted more of them or if we increased our instruments’ resolution.
If this assumption is false, though, all consequences which we deduce from it are also false. If the assumption is valid, on the other hand, we have a whole set of machine learning tools that we can use to work with the data collected.
3.6. Why Does Calculus Matter?
The question is therefore whether we can assume that our variables are continuous, and thus apply calculus in our models. Let’s go back to computers now, in order to answer this question.
Computers don’t operate in continuous spaces but merely approximate them. Nonetheless, since the approximation is good enough for most practical purposes, we can generally treat our measurements as continuous and therefore apply calculus.
It’s important to note that the considerations made in this paragraph apply not only to observations in a dataset but also to other discrete variables which we presume to be continuous, such as the weights or error in a neural network. If they aren’t continuously distributed, we can’t apply gradient descent on the neurons to guide their learning.
Practically, though, when first approaching machine learning, we’re required to know enough calculus so as to understand how to compute the derivatives of the most common activation functions in neural networks, but not much more.
3.7. Programming
Last, but not least, specialists in machine learning must obviously know programming. The degree to which they’ll need to be proficient with it varies significantly. Data scientists require the least experience in programming and machine learning engineers and artificial intelligence researchers require the most.
These are the programming languages typically associated with machine learning:
- Python and R for Data Analysis
- Python, C, and C++ for production
- Scala, Kotlin, and Java for the Java Virtual Machine
- Unity (C#) and NetLogo for multi-agent simulations
It’s important to stress that, from the perspective of machine learning, programming is only a tool we use. It’s not the finality of our work though.
4. The Equally Important but Often Overlooked Alternative Approaches
There are also other theoretical approaches to machine learning and artificial intelligence, with as many corresponding disciplines, that can guide the study of those who first approach the sector. The ones we’ll discuss here are:
- Psychology and cognitive science
- General systems theory
- Agent-based modeling
- Complexity theory
Let’s see now what is their less-known, but equally important, relationship with artificial intelligence.
4.1. Psychology and Cognitive Science
As mentioned earlier, artificial intelligence arises as an extension of the research on cognition to non-human systems. The source of inspiration for all work done for artificial neural networks is in fact the human brain, which artificial neural networks attempt to replicate in a computable manner.
The approach to the replication of human cognition by means of artificial neural networks takes the name of Connectionism, which is one of the two theoretical approaches to artificial intelligence. This approach is the main one that data scientists and machine learning engineers apply in their jobs. Equally important, though, is the one which relates to symbolic reasoning in humans.
Symbolism, this is the name of this second approach, is the theory that covers the application of artificial intelligence to symbolic reasoning. The construction of knowledge graphs, chatbots, and the methodology of Natural Language Processing, are all based upon the theoretical approach of Symbolism towards artificial intelligence.
While machine learning engineers typically focus on the Connectionist approach to artificial intelligence, other types of engineers, such as knowledge engineers, dedicate themselves to implementing symbolic reasoning in expert systems. This type of profession normally requires a good understanding of both programming and psychology or cognition.
4.2. General Systems Theory and Cybernetics
Systems Theory or General Systems Theory is a discipline that focuses on the formulation of principles that are applied to all other theories that talk about systems. In a sense, since most theories deal with systems, it’s a meta-theory that has, as content, all other theories.
The relationship between General Systems Theory and machine learning is not obvious. It will become however apparent if we conceptualize machine learning systems as systems necessarily embedded in larger systems:

These larger systems can be either social, biological, electronic, informational, or can belong to other kinds. But in all cases, some kind of non-machine learning system always exists, which includes the machine learning system as its subsystem. Since no machine learning system lives in a vacuum, its capacity to operate depends largely on its interaction with other components of the larger system, and this interaction can be studied under General Systems Theory.
General Systems Theory is also related to Cybernetics. The latter is the discipline concerned with the study of feedback and communication between components of a system. Cybernetics, in turn, is the science from which the modern disciplines of Computer Science and Artificial Intelligence originate.
General Systems Theory is the domain expertise of systems engineers. These are the professionals in AI responsible for the integration of machine learning systems into the larger social or robotic systems. If our interest in machine learning is related to robotics or world representations, then General Systems Theory is the way to go for us.
4.3. Agent-Based Modeling
Agent-based or multi-agent modeling is a methodology rather than a discipline or theoretical approach. It’s still important to mention it here though because of its wide-spread usage in computer simulations on artificial intelligence.
Its relationship with Artificial Intelligence descends from the definition of intelligence that is given by Russel and Norvig. According to them, intelligence is a property that emerges from the interaction between an agent and its environment. This means that, when building an artificial intelligence system, we have to first define an environment; only then we can build an agent that operates in it.
Any study with the methodology of agent-based modeling starts by defining an agent and the environment in which this agent lives. It then defines the goals of this agent and its perceptual capacity in relation to that environment:
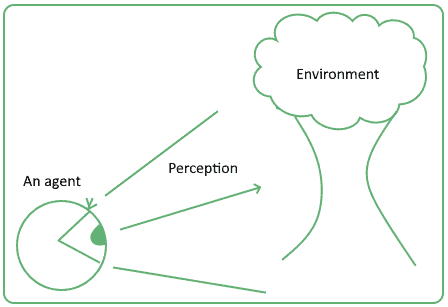
The methodology often involves the study of the learning process which takes place as the agents behave in their environment and adapt their behavior in relation to it. This type of learning differs from the one which is most common in machine learning. It’s in fact based on a bottom-up rather than a top-down approach, where the rules of the system are not explicitly programmed aprioristically.
Agent-based modeling is one of the most prolific approaches to the subject of machine learning. It allows in fact the study of emergent properties of a system, which we can’t otherwise derive analytically.
4.4. Complexity Theory and Non-Linear Dynamics
One last alternative approach to artificial intelligence is the one that uses the theory on complex systems. Complex systems are systems whose behavior isn’t reducible to the aggregate behavior of their components; but that instead exhibit emergent properties, which we can’t necessarily infer by studying the operation of their elements.
A typical application of complexity theory is for the study of non-linear systems. If a system presents non-linear dynamics, we can’t correctly model it as a linear dynamical system. A typical example of this is the Lorenz system and the corresponding attractors:
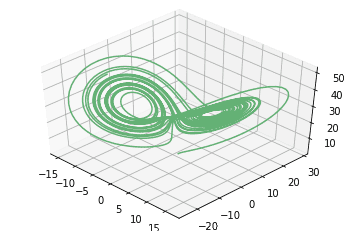
The system has a clear dynamic that appears if we study it as a non-linear system, but is invisible to us otherwise. Many systems normally encountered in machine learning are secretly non-linear systems; because for them the machine learning model, as it operates, causes effects that influence and modify its underlying physical system.
Say we’re building a model for predicting house prices, but say also that on the basis of that model’s predictions we actually decide to buy or sell houses.
The model, with its predictions, will impact the factors upon which the system operates. This, in turn, will eventually invalidate the model. Over time, we should expect to observe an increasingly higher discrepancy between the model’s predictions and its underlying system.
If we’re trying to predict the future behavior of a system, but at the same time our predictions influence that system’s behavior, then the modeling of the system through standard machine learning techniques becomes impossible. In these cases, complexity theory can help us tackle an otherwise unsolvable task.
5. Conclusion
In this article, we’ve seen how the three different branches typically associated with machine learning – i.e., data science, machine learning engineering, and artificial intelligence – relate and differ from one another.
We’ve seen also what are the common prerequisites to the study of machine learning. In connection with them, we’ve identified the reasons why they matter to specialists.
We’ve finally seen some alternative approaches to the study of artificial intelligence. These approaches, while less common, bring academic and professional credit to us if we master them.