

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about Content-Based Image Retrieval (CBIR) and its difference from Text-Based Image Retrieval (TBIR).
There are many real-world applications in which CBIR plays an important role. Some examples are medicine, forensics, security, and remote sensing.
Content-Based Image Retrieval (CBIR) is a way of retrieving images from a database. In CBIR, a user specifies a query image and gets the images in the database similar to the query image. To find the most similar images, CBIR compares the content of the input image to the database images.
More specifically, CBIR compares visual features such as shapes, colors, texture and spatial information and measures the similarity between the query image with the images in the database with respect to those features:
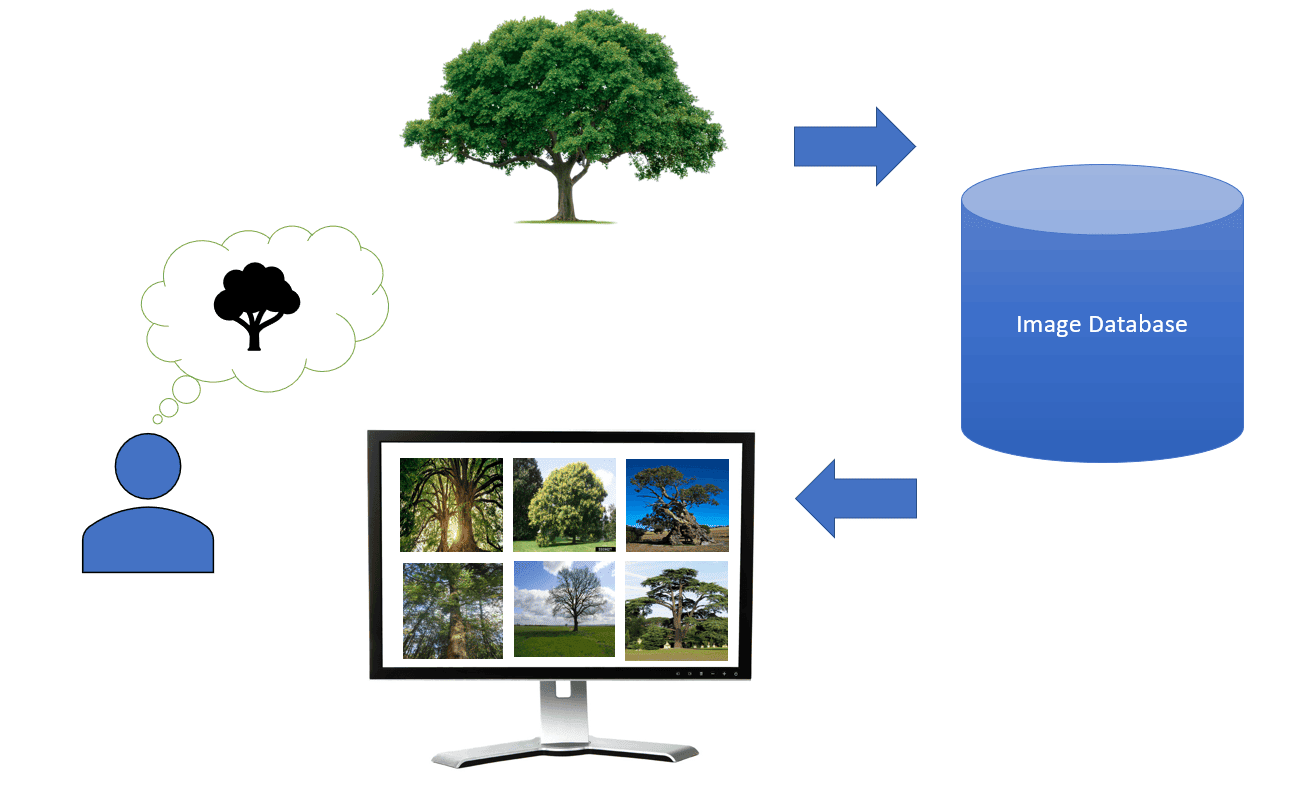
In this picture, we have an example query image that illustrates the user’s information need and a very large dataset of images. CBIR system’s task is to rank all the images in the dataset according to how likely they are to fulfill the user’s information need.
In the Text-Based Image Retrieval (TBIR) approach, experts manually annotate images with geolocation, keywords, tags, labels, or short descriptions. Users can use keywords, annotations, or descriptions to retrieve similar images that exist in the database:
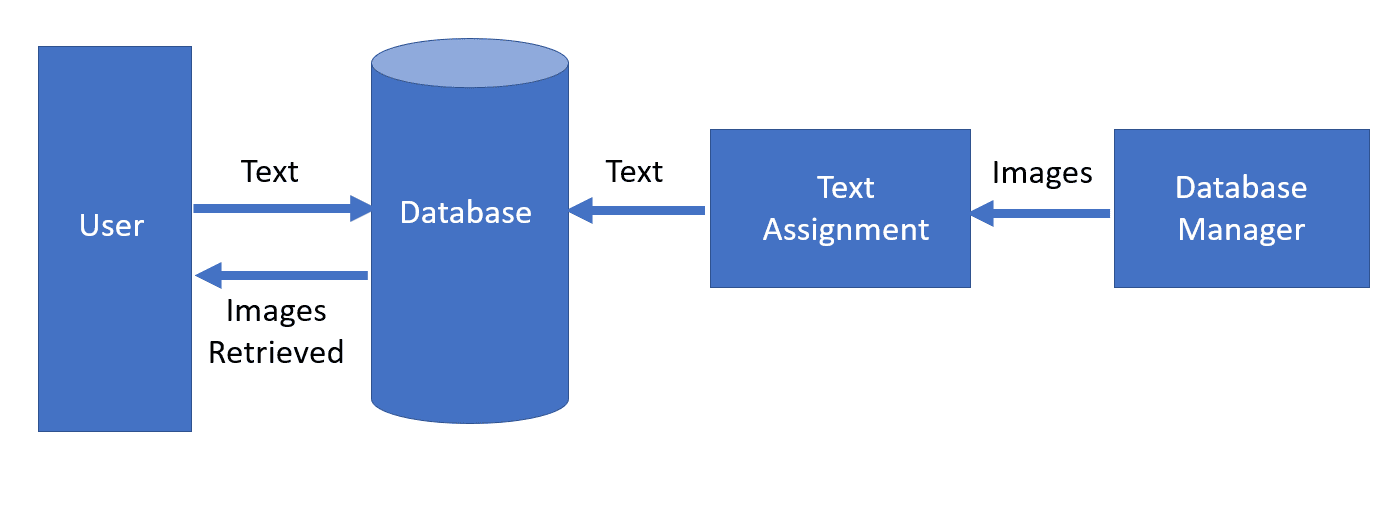
As we see, when users specify text or description as a search term, TBIR will retrieve the images that were assigned similar textual tags.
The approach is simple and intuitive but has some disadvantages. Firstly, since it takes a considerable amount of time to annotate images manually, it’s labor-intensive. Further, the tags may be unreliable due to the dependency on people’s perceptions and interpretations that can vary widely across groups of individuals. To address those problems, CBIR compares the visual contents of images directly. In that way, there is no need for human labor as well as their subjective and error-prone perception.
CBIR systems need to perform feature extraction, which plays a significant role in representing an image’s semantic content.
There are two main categories of visual features: global and local.
Global features are those that describe an entire image. They contain information on the entire image. For example, several descriptors characterize color spaces, such as color moments, color histograms, and so on.
Other global features are concerned with other visual elements such as e.g. shapes and texture.
In this diagram, we find various methods for global feature extraction:
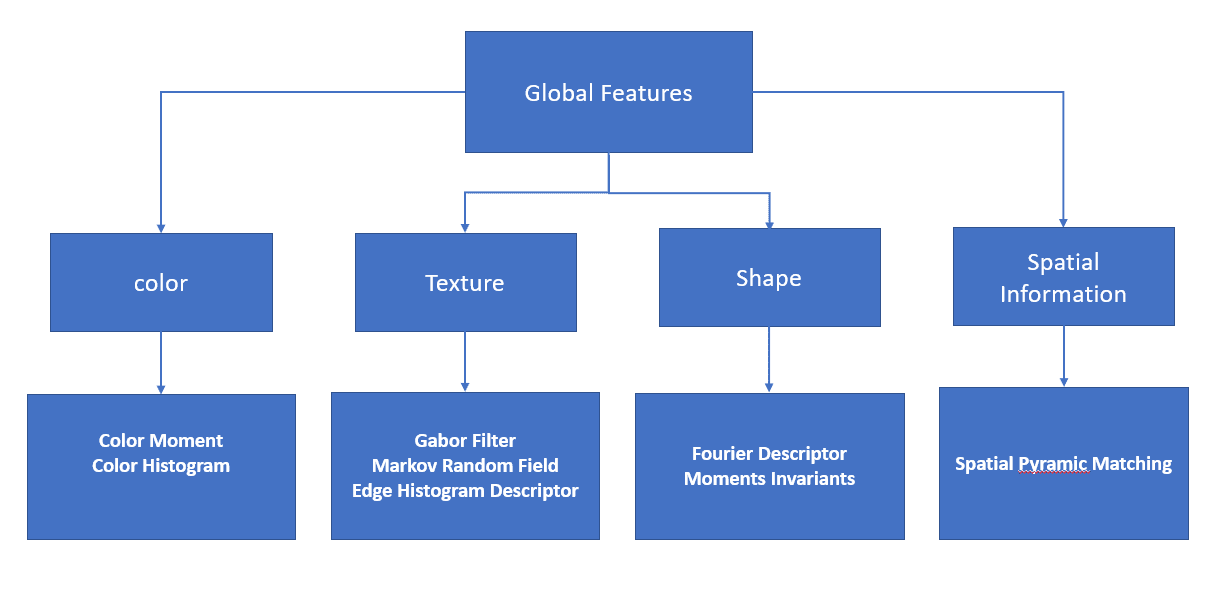
While global features have many advantages, they change under scaling and rotation. For this reason, local features are more reliable in various conditions.
Local features describe visual patterns or structures identifiable in small groups of pixels. For example, edges, points, and various image patches.
The descriptors used to extract local features consider the regions centered around the detected visual structures. Those descriptors transform a local pixel neighborhood into a vector presentation.
One of the most used local descriptors is SIFT which stands for Scale-Invariant Feature Transform. It consists of a descriptor and a detector for key points. It doesn’t change when we rotate the image we’re working on. However, it has some drawbacks, such as needing a fixed vector for encoding and a huge amount of memory.
Recently, state-of-the-art CBIR systems have started using machine-learning methods such as deep-learning algorithms. They can perform feature extraction far better than traditional methods.
Usually, a Deep Convolutional Neural Network (DCNN) is trained using available data. Its job is to extract features from images. So, when a user sends the query image to the database system, DCNN extracts its features. Then, the query-image features are compared to those of the database images. In that step, the database system finds the most similar images using similarity measures and returns them to the user:
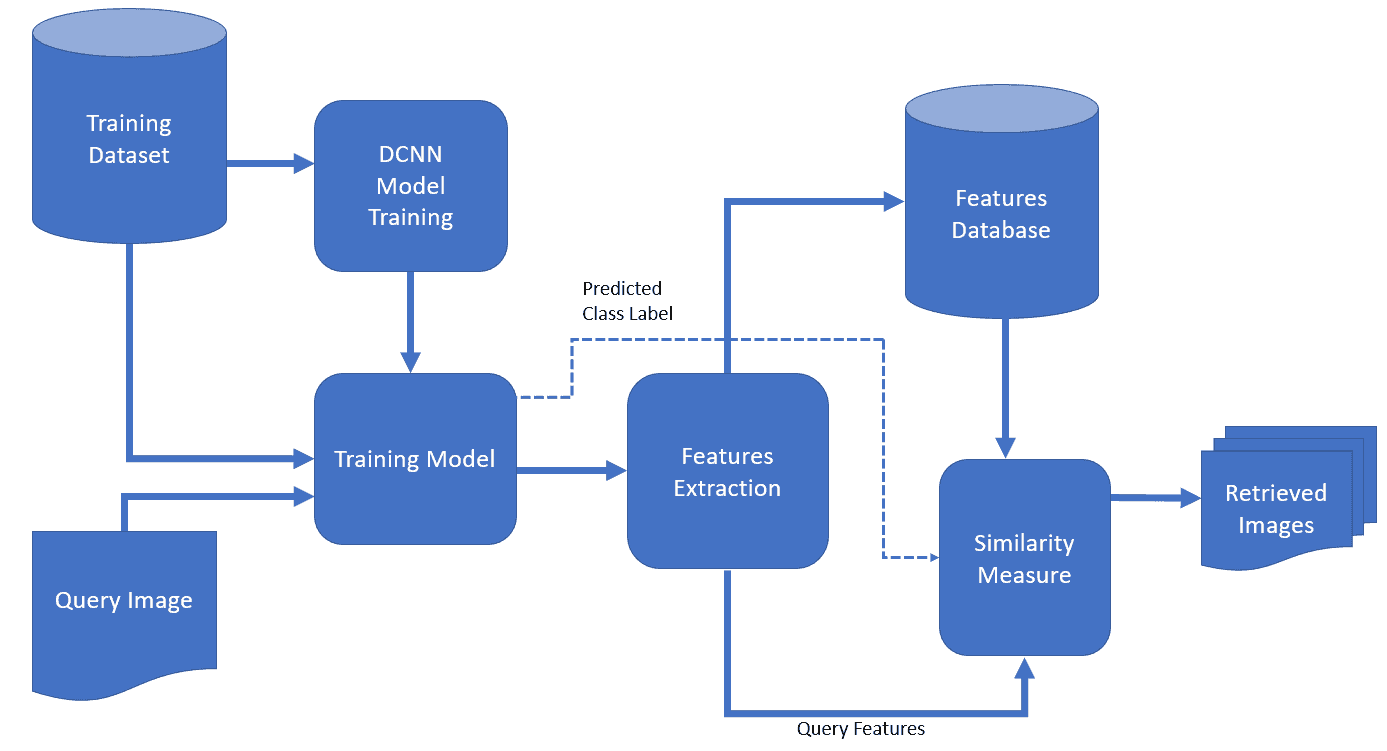
Since there are various pre-trained convolutional networks as well as Computer Vision Datasets, some people prefer ready-to-use models such as AlexNet, GoogLeNet, and ResNet50 over training their networks from scratch.
So, deep-learning models such as DCNN extract features automatically. In contrast, in traditional models, we pre-define the features to extract.
Similarity measures quantify how similar a database image is to our query image. The selection of the right similarity measure has always been a challenging task.
The structure of feature vectors drives the choice of the similarity measure. There are two types of similarity measures: distance measures and similarity metrics.
A distance measure typically quantifies the dissimilarity of two feature vectors. We calculate it as the distance between two vectors in some metric space.
From there, the most similar images to the input image are those with the smallest distances to it.
There are several distance functions we can use. Manhattan distance, Mahalanobis distance, and Histogram Intersection Distance (HID) are some examples of distance measure functions.
We calculate HID as:
where  is the histogram of the input image and
is the histogram of the input image and  is the histogram of the model (object) in the
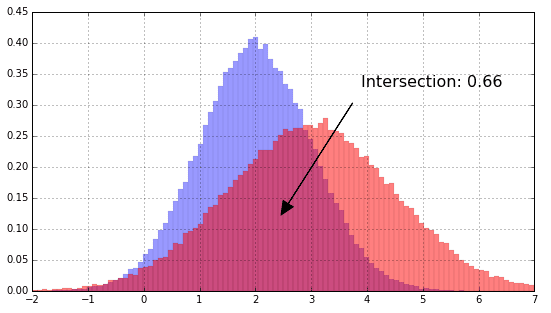
is the histogram of the model (object) in the  -dimensional Euclidean Space. HID computes the similarity of two histograms (distributions), with the possible values of the intersection between 1 (identical) and 0 (no overlap). The distance denotes the number of pixels with similar colors.
-dimensional Euclidean Space. HID computes the similarity of two histograms (distributions), with the possible values of the intersection between 1 (identical) and 0 (no overlap). The distance denotes the number of pixels with similar colors.
Geometrically, HID is the intersection of two histograms:
On the other hand, a similarity metric quantifies the similarity between two feature vectors. So, it works the opposite way to distance metrics: the most significant value shows the image similar to the query image.
For example, the cosine distance measures the angle between two feature vectors.
Given two vectors of features, X and Y:
In this tutorial, we explained Content-Based Image Retrieval (CBIR) and its difference from Text-Based Image Retrieval. Modern CBIR systems use deep convolutional networks to extract features from a query image and compare them to those of the database images. The most similar images constitute the query’s result.
![\[HID(S, M) = \sum_{i=1}^{n} min(M_{i}, S_{i})\]](/wp-content/ql-cache/quicklatex.com-df2e6659e528f221eb3f18165a69b4a4_l3.svg "Rendered by QuickLaTeX.com")
![\[CosineDistance(X, Y) = \frac{\langle X , Y \rangle}{\lvert X\rvert \times \lvert Y \rvert}\]](/wp-content/ql-cache/quicklatex.com-6cbe974b5aa486b453f5bdf946087a96_l3.svg "Rendered by QuickLaTeX.com")