

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explain zero trust security, or zero trust architecture (ZTA), and its core principles.
We’ll start with a brief overview of the traditional security model and why we need a new one. Next, we’ll explain the core principles of ZTA and its components. Finally, we’ll provide a summary of the main concepts of ZTA.
The traditional security model is based on the concept of a network perimeter. We can think of it as a “circle of trust”. Anyone who’s inside is trusted, and anyone who’s outside is not. To get inside the circle, we need to authenticate ourselves, and once we’re inside, we can access all the available resources.
The first problem with this approach is that the mechanism for user authentication is a single point of failure for the whole system’s security. The second problem is that once inside, we can access all the resources without limitations, no matter how we get inside.
Another drawback of the traditional security model is the definition of the network perimeter. Is it defined by the physical boundaries of the network or a range of IP addresses? What if we have clients accessing the network from outside using VPNs? What if there are outsourced services that are not part of the network? And what about mobile and IoT devices? With so many portable and IoT devices around, the concept of a network perimeter no longer works.
So how can we tackle these problems? The answer is Zero Trust Architecture – a new security model. The name “Zero Trust” may evoke the idea of not trusting anyone, but that’s not true. The idea is to move the access control mechanisms closer to the protected resources.
Although the Zero Trust Architecture was first specified in 2018 by NIST as Special Publication 800-207 in 2018 and updated in 2020, the term “Zero Trust” was first coined by Forrester Research in 2010.
ZTA isn’t a concept of not trusting anyone. ZTA is a strategy focused on resource protection under the premise that trust is never granted implicitly and must be continually evaluated.
This principle is often expressed as “never trust, always verify”. No one can access anything by default, and we grant only the minimum privileges necessary to perform a specific task. This sums up the goals of ZTA:
By implementing these goals, the network perimeter vanishes, and we get lots of small perimeters around resources. We call this micro-segmentation. It’s similar to breaking a monolithic application into microservices (microsegments):
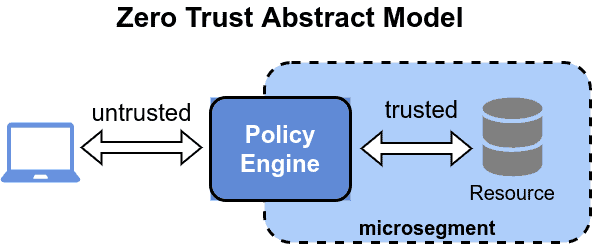
So, ZTA isn’t a particular technology but a strategy. In the following subsections, we’ll closely examine the fundamental parts of ZTA and their implementation.
Shrinking the network perimeter to a minimum (microsegment) reduces the attack surface. The attack surface is a collection of all the attack vectors, paths, or means by which a hacker can access an inner resource. Moreover, if the attacker is already inside the network, they can move laterally to access its resources.
Microsegments allow us to deploy the protected services in a container technology such as Docker. This makes it easier to deploy the protected services and, primarily, provides further isolation (aka sandboxing). Sandboxing prevents lateral movement because if a hacker breaks into a microsegment, he can’t access other microsegments.
The next key concept of ZTA is the software-defined perimeter (SDP). In the traditional security model, the perimeter is based on hardware devices such as routers and firewalls. SDP means:
These concepts aren’t new, as they build upon the idea of “port knocking”. This is a technique for hiding resources from the public network. A subject who wants to access a resource must first send the correct sequence of connection attempts to a set of predefined ports. Only in that case does the protected resource open the port and allow the subject to access it.
Because the port knocking technique is a “quick and dirty” solution, the idea was further developed into single packet authorization (SPA). This more systematic approach uses cryptographic techniques to authenticate the connecting subject and reveal the resource only to an authenticated subject. Some believe that SPA will replace VPNs in the future.
The identity-and-access management (IAM) is a pillar of the “never trust, always verify” principle. The IAM system is responsible for managing identities and access rights and for authentication and authorization.
In a Zero Trust system, it is important that each request is authenticated, authorized, or comes with security context information, also known as an authentication token. The policy engine usually uses the security context to decide whether to allow the request.
Because the subject’s identity is the basis for the access control decision, we use strong authentication or multi-factor authentication (MFA) in ZTA.
Communication must be secure because it isn’t trusted outside of microsegments. Usually, we accomplish this by using data encryption and signing.
Concerning data storage, the data must be encrypted and protected as well. Even if we store the data in a microsegment, a trusted user can steal them, or something can compromise the underlying storage service.
Role-based access control (RBAC) is a critical component of ZTA. A policy engine implements it. The engine is responsible for evaluating policies and making access decisions.
If we look at the Zero Trust Logical Model, we have the policy decision point (PDP) and the policy enforcement point (PEP):
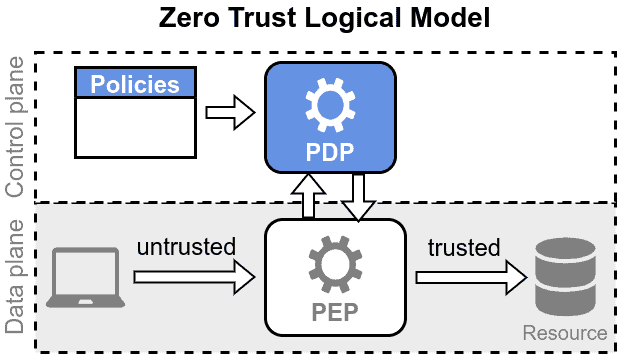
There’s a PEP for each microsegment, which asks the PDP for an access decision. The inputs for the decision process are the security context of the incoming request (user, privileges, and access type) and the policies an administrator defines. After evaluating the request in the context of the defined policies, the PDP returns the decision to the PEP, which enforces it.
Since the policy engine’s security is fundamental to the whole system’s security, ensuring it isn’t compromised is important. Also, because the number of microsegments is usually large, and so is the number of policies, the scalability of the PDP and the policy management are crucial.
To scale the PDP, we can replicate it. Concerning the policies, we could store them in a file or a database or even “hard code” them in the PDP. But this approach isn’t very flexible. In large systems with lots of policies, we also want to have control over policy changes and audit them.
Moreover, we want to plan and test the changes before applying them. This is similar to continuous integration and continuous delivery (CI/CD) in software development. This approach became very common, and we call it the policy-as-code concept. We define policies using a high-level language and store them in a version control system. Through a CI/CD pipeline, we test the policies and deploy them to the PDP.
Another key concept of the “zero trust mantra” is the assumption that the system is already compromised. This means that we constantly monitor the system to detect and respond to a breach. This part is endpoint detection and response (EDR). It’s a system that monitors the endpoints and detects suspicious activities.
EDR has two primary components: detection and response. The detection component is usually implemented by telemetry agents, which collect data from the endpoints and send it to a threat detection system. When they find a threat, the response component acts accordingly. Moreover, collecting data from endpoints also increases the visibility of what happens in the system.
Ensuring the EDR system can process many logged events is essential for scalability. Because breaches may display significant variability, the detection engines must be able to detect a wide range of threats. We often use suitable machine-learning algorithms for this.
Let’s now summarize the main concepts of Zero Trust Security in the table below:
| Main concepts | Benefits |
|---|---|
| Never trust, always verify | Reduced risk |
| Implement least privilege | Greater control |
| Assume breach | Extended security |
| Microsegmentation | Increased visibility |
In this article, we explained the core principles of zero trust security (zero trust architecture, ZTA). It’s based on the “never trust, always verify” principle. ZTA isn’t a technology but a strategy or mindset, just like DevOps or microservices. We can use various technologies to implement it.
ZTA isn’t a silver bullet. Like many other security concepts, it can be compromised if incorrectly implemented. The system’s security is only as strong as its weakest link.