

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: June 28, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Since the introduction of the Waterfall model, the first Software Development Life Cycle (SDLC), many other development models have been introduced. Around 2000, the “Agile revolution” led to the publishing of the Agile Manifesto. Because “agile” doesn’t apply only to developers, the agile approach resulted in a new methodology called DevOps.
In this tutorial, we’ll discuss three fundamental DevOps concepts and their differences – Continuous Integration, Continuous Deployment, and Continuous Delivery.
Continuous integration, deployment, and delivery refer to the code, build, test, release and deploy phases of the DevOps cycle. These phases are reflected in a software production pipeline with several stages, as shown in this picture:
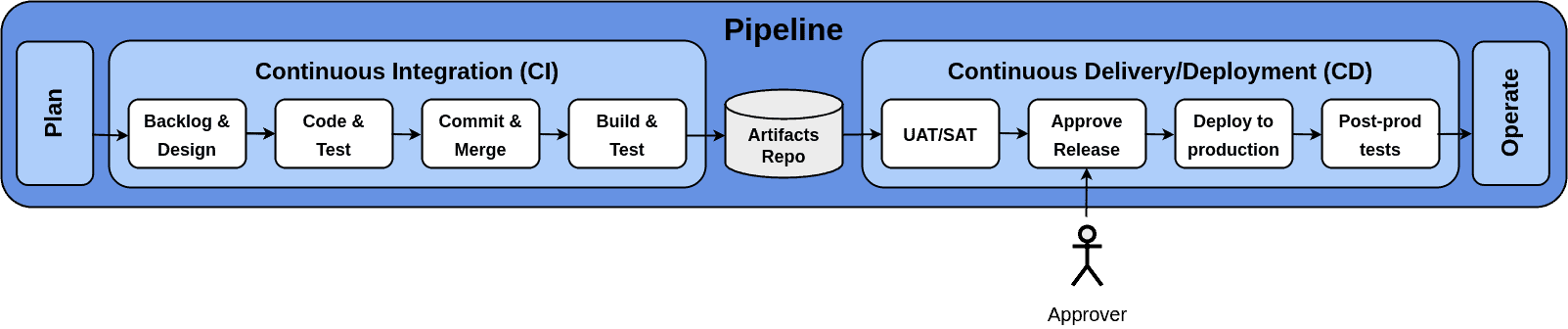
Each stage represents a task performed on the input product. The output product is then passed to the next stage, and so on. The term “product” usually refers here to a software artifact. As we can see, the initial input of the pipeline originates from planning and design activities as a backlog of particular tasks.
The developers then work on the tasks and commit changes to the source code repository. This usually happens on a development branch but may also happen on the main branch, depending on the workflow used. The source code is built and tested automatically as the developers merge their changes into the main branch.
If the automatic tests pass, the resulting artifacts are published in a repository. If they fail, the build is aborted, and the developers are notified. This also happens automatically. In this section of the pipeline, with every task completed, a new version of the software artifact is released.
The frequent adoption, implementation, and incorporation of changes into the software product are together referred to as Continuous Integration.
Software delivery and deployment are the last stages of the software production pipeline. Let’s explain what delivery means. From the point of view of a single developer, it may mean that a particular change was tested and merged into the main branch. This is how a developer delivers his work.
But does it work with the other changes made by other developers in the meantime? Or does it work with a new version of a dependency that had to be upgraded because the old one was vulnerable or deprecated? Moreover, did the developer understand the requirements of the new feature or bug fix correctly?
Now we can see that the delivery refers to the whole software product, not only to a single change. The delivery is the process of delivering the complete final software product to the customer.
A software product is usually composed of several components developed by different teams in parallel. So the entry point of the second section of the pipeline, where continuous delivery and deployment happen, is a confluence of several continuous integration (CI) pipelines. The final products of the CI pipelines usually land in a repository of intermediate artifacts, where they are stored and can be drawn from.
In complex software products, there may also be several customers or software consumers. Complex software requires large teams with different areas of work. A team may be developing a core library used by other teams. As the core library is developed, new versions are continuously delivered to an internal repository and used by other teams.
In summary, continuous delivery is a process of delivering a software product or artifact to the final consumer at a place where it can be drawn from and used. With “used”, we mean that it may be included in a larger software product or it may be deployed in a production environment. The deployment of a new release must usually be approved by a product manager or the customer (see Approver actor in the picture above).
In practice, a new product release delivery happens in two steps. In the first step, the software is automatically deployed to a testing (or staging) environment. The developers, as well as the customer, have access to this environment and can test the bug fixes and new features. This step is called “user acceptance tests” (UAT) or “site acceptance tests” (SAT) and can also be partly automated. So, the deployment to the testing environment is continuous, while the deployment to the production environment must be approved.
With the rise of cloud applications that often work together with mobile applications, software complexity grew by several orders of magnitude. For example, cloud services are running on thousands of virtual machines, and manually approving the deployment of each software release on these machines is not feasible anymore. So, the deployment of a software release is now also automated, and we refer to it as Continuous Software Deployment.
Of course, the new release is not deployed on all machines at once. Instead, it is deployed in a controlled way, with a certain percentage of machines receiving the new release. If it works as expected, the percentage of machines is increased. Otherwise, the deployment is either rolled back or the machines are destroyed, and new ones with the previous release are created, which is more common and cheaper.
Because the released changes are small, it is also easy to automate tests to determine whether the new release works correctly. This is done in the last stage, labeled “Post-prod tests”, of the “Continuous Delivery/Deployment” section of the pipeline.
Why are these processes called “continuous”? Because they are performed continuously. In the beginning, the software development was done in long cycles. Requirements were gathered and analyzed, a design was created, and the software was developed, tested, and then released. The releases were a kind of “big bang” event, and the customers had to wait for a long time until the next release.
In this approach, no changes were allowed in between because the software specification was frozen. This caused frustration among the customers as well as among the developers. Customers didn’t get the product they wanted, and developers didn’t get the feedback they needed. The product features drifted away from the customer’s needs.
Moreover, software updates were expensive and time-consuming. Not only the development of the new features and necessary tests took a lot of time, but also the migration of the existing software and production data to the new version was complex and error-prone. As a result, both sides feared the next release. This phenomenon is often expressed by the developers as “big changes hurt” and was the main motivation for introducing the agile approach and later DevOps.
If the software evolves in small steps, then the changes are minor. Small changes are easier to implement, test, and deploy. They are less error-prone and also can be rolled back easily. The software development cycle becomes short, so the frequency of releases increases as the new changes are continuously integrated into the software.
Customers get the latest features and bug fixes faster, and developers don’t fear the next release because their trust in the developed software is high. Further, by automating the build, test, deliver and deploy processes, the human labor and errors are reduced, and the trust in the software is even higher. Nobody is now afraid to release on Friday afternoon.
In summary, we can now review in the table below, what Continuous Integration, Continuous Delivery, and Continuous Deployment processes are. Although they are three separate processes, together, they form a bigger part: the software production pipeline.
| Process | Input | Activities | Output |
|---|---|---|---|
| Continuous Integration | Backlog tasks | Planning, designing, writing code, merging, building and testing | Software artifacts |
| Continuous Delivery | Software artifacts | Assembling, packaging, acceptance testing, and publishing of the final product | Final product |
| Continuous Deployment | Final product | Applying automated deployment strategies, automated post-prod tests and rollbacks | Operated production software |
In this article, we discussed the main processes that together constitute the software production pipeline and their differences. We also emphasized that if the changes processed in this pipeline are small, the whole software development process becomes smoother and faster, in other words: Continuous. Also, the automation of tasks plays an important role here. It eliminates the human factor, increases the reliability and repeatability of particular tasks, and enables the whole software production process to scale well.