Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: June 19, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Object detection in simple words is a computer technology related to computer vision and image processing that deals with detecting objects of a certain class in digital images and videos. Every object class has unique characteristics that aid in classification; for example, all circles are circular. These particular properties are used in object class recognition. When looking for circles, for example, items that are a certain distance from a point (i.e. the center) are searched. Similarly, while searching for squares, items with perpendicular corners and identical side lengths are required. A similar method is utilized for facial recognition, where traits such as skin color and distance between eyes may be identified, as well as eyes, nose, and lips.
Single Shot Detectors (SSDs) are a popular and efficient type of method used to perform these tasks. They are capable of detecting objects in real time, making them useful for applications such as self-driving cars, surveillance systems, and robotics.
In this tutorial, we’ll go deeper into the theoretical details of SSD, including how it works, and its advantages and disadvantages in this article.
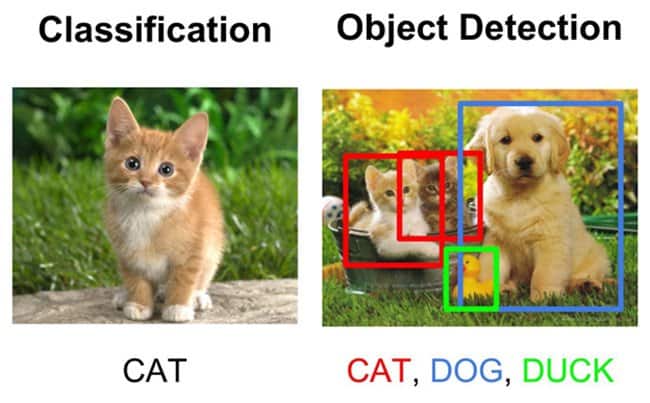
Image classification in computer vision takes an image and predicts the object in an image, while object detection not only predicts the object but also finds its location in terms of bounding boxes.
For example, when we build a classifier to classify animals with classes (cat, dog, and duck), we take an input image and predict whether it contains a cat or dog, while an object detection model would also tell us the location of the cat, dog, or duck:
We can divide the object detection methods into:
With the development of deep learning, object detection has gained lots of improvements and is widely used in many real-world applications such as self-driving cars, surveillance systems, and object tracking. These algorithms typically leverage a pre-trained deep neural network, such as a convolutional neural network (CNN), which has been trained on a large dataset of annotated images to learn the features and representations required for object detection.
SSDs are a popular and efficient method for object detection. One of the key features of SSDs is that they use CNN to predict bounding boxes and class labels for objects in an image. This contrasts with other object detection algorithms, such as the popular R-CNN family of methods, which use multiple networks and stages to detect objects. Using a single network allows SSDs to be faster and more efficient than these other methods.
Generally, the architecture of an SSD typically consists of a base network, such as VGG or ResNet, that is pre-trained on a large image classification dataset, such as ImageNet. This base network is then followed by several additional layers, known as the “extra layers,” that are added on top of the base network. These extra layers are responsible for detecting objects at different scales and are typically composed of convolutional and pooling layers:
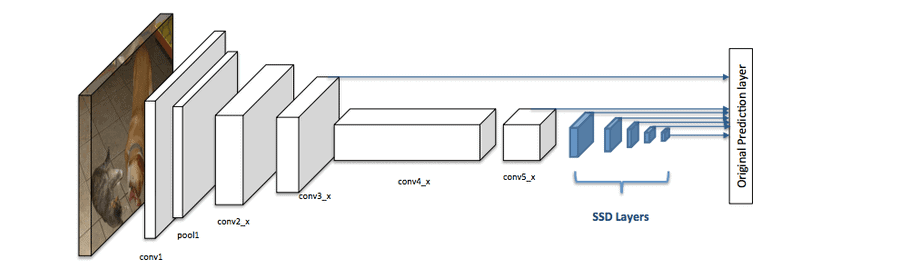
One of the main advantages of SSDs is their speed and efficiency. Because they use a single network, they can detect objects in real-time, making them suitable for applications such as self-driving cars and surveillance systems.
Additionally, because they use a pre-trained base network, SSDs can take advantage of a large amount of labeled data available for image classification tasks. This allows them to achieve high accuracy even when trained on relatively small datasets.
On the other hand, SSDs have some limitations. First, they are not as accurate as other methods, such as the R-CNN family of methods. This is because using a single network means SSDs cannot take advantage of the additional context and information that multiple networks provide.
Another limitation of SSDs is that they can be sensitive to the scale of the objects in an image. Because the extra layers are designed to detect objects at different scales, SSDs may have difficulty seeing objects significantly smaller or larger than the objects in the training dataset.
As described above the whole architecture of the SSD. In this section, we can illustrate the flow of the SSD as follows:
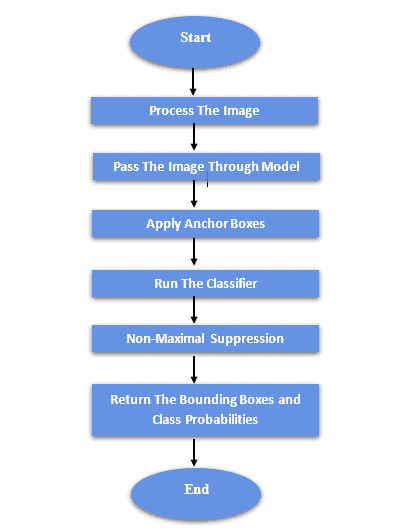
The flowchart shows the main processes needed to perform the SSD task. So, firstly the input image is preprocessed to prepare it for processing by the model. This can involve steps such as resizing, normalizing, and data augmentation. Then, the preprocessed image is passed through the model to obtain feature maps representing a high-level abstraction of the image.
After passing the image through the model, the anchor boxes, or default boxes, are applied to the feature maps to generate a set of potential bounding boxes for objects in the image. Hence, a classifier is run on each bounding box to determine the class of the object contained within the box. Moreover, to eliminate overlapping boxes and refine the final set of bounding boxes, Non-Maximal Suppression is applied. Finally, a set of bounding boxes and their corresponding class probabilities are returned as the output of the algorithm.
In conclusion, Single Shot Detectors (SSDs) are a popular and efficient method for object detection. They use a single convolutional neural network (CNN) to predict bounding boxes and class labels for objects in an image, making them faster and more efficient than other methods.