Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: August 31, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Computer vision is a field that’s been around almost as long as the computer itself. While the term “computer vision” was coined in 1960 by Robert Fischell, its applications have been around since even earlier: The first camera was invented in 1826, and scientists used cameras to analyze data as early as 1930.
Today, however, we’re seeing more and more uses for computer vision. From helping us navigate our homes to understanding what’s happening on our computers’ screens. There are lots of ways that computer vision can help us do better things faster.
In this tutorial, we’ll look at what computer vision is and where it’s used.
Computer vision or CV for short, it’s a field of study that focuses on how computers can be programmed to understand images and video.
There are many different ways to approach CV, but most researchers focus on solving certain problems in the following categories:
There are three main types of computer vision applications: visual perception, machine learning, and robotics. Visual perception involves analyzing an image or video frame by frame to identify objects in the scene; this can be used to build applications like self-driving cars or augmented reality systems.
Machine learning refers to building computer programs that have access to large amounts of data so they can learn how to make decisions based on certain criteria; this is commonly used for facial recognition systems like Apple’s Face ID.
Robotics involves developing machines capable of moving autonomously through their environment using sensors as input devices; examples include robots used in factories or drones used during search missions after natural disasters such as earthquakes or hurricanes.
Computer vision applies a lot of techniques to perform a variety of tasks including object detection, face recognition, image restoration, pose estimation, and event detection. In this section, we’ll elaborate on a few of the common techniques used by CV.
A lot of the research in the CV area is focused on object detection and classification. In recent years, there have been several papers that use Deep Learning models to detect objects in images or videos. There are a few different types of object detection models, but the most common is an instance segmentation model.
A computer vision technique called “object detection” is used to find specific objects in images or videos. It’s usually achieved by applying deep learning techniques and using pre-trained models or creating and teaching custom models. This is useful for applications like autonomous vehicles or self-driving cars, which need to know exactly where things are to make decisions about how the car should react when it sees them (e.g., stop at a red light or drive through it).
This is a very challenging problem because there are many different types of objects. Objects all look different depending on how they’re lit and positioned in an image (and also what kind of object it is). A lot of research has gone into finding ways to make this process more accurate.
Some of the most common techniques are:
Object detection using OpenCV’s DNN and a YOLOv3 model:
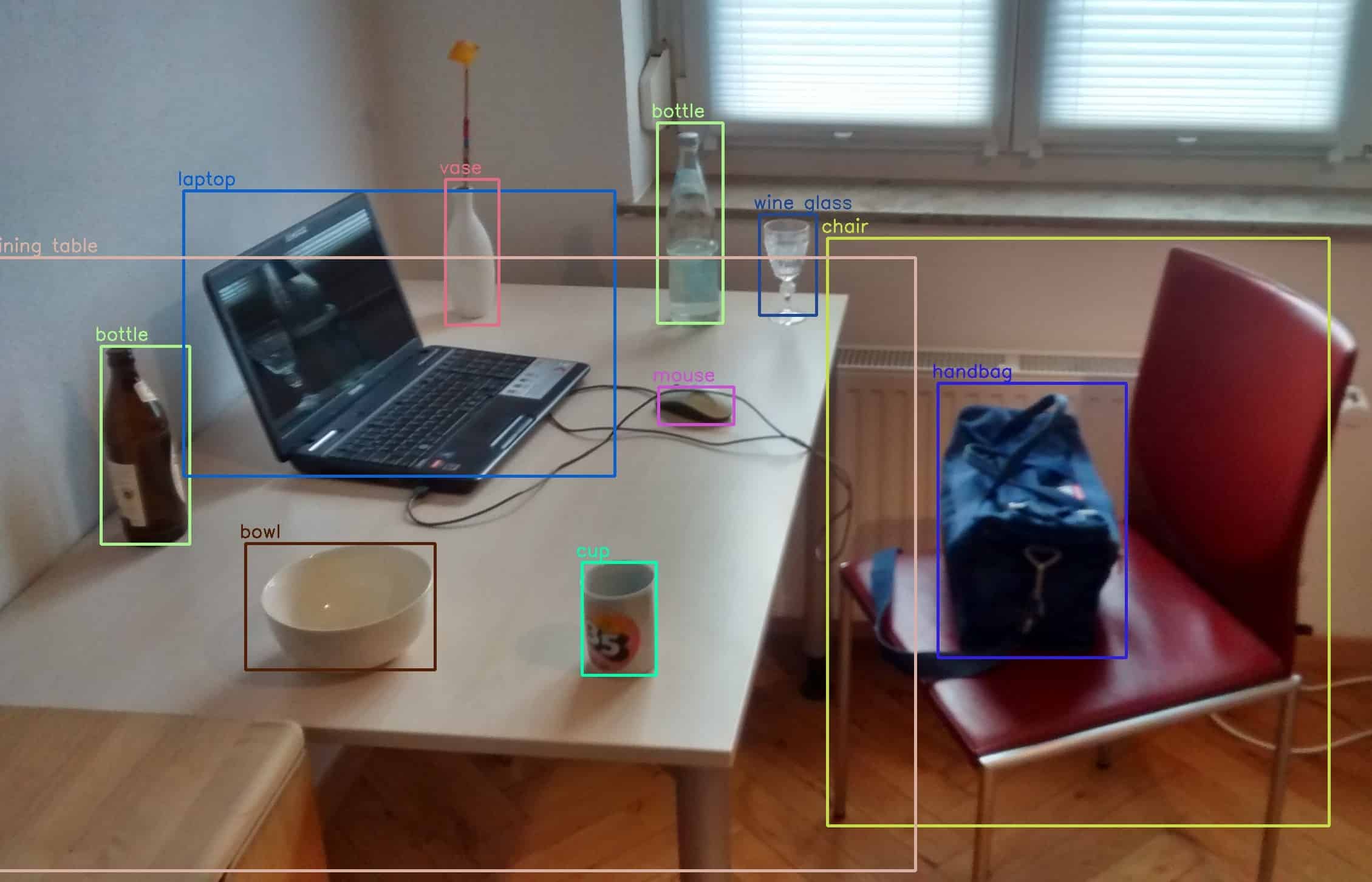
Semantic segmentation is the process of partitioning an image into multiple segments. It’s different from traditional pixel-wise classification because we’re not looking at individual pixels. Using semantic segmentation, we’re looking at the entire scene as a whole. Semantic segmentation can be used for object detection and human detection.
This might sound like a simple task — just draw some lines around objects in the image. But it turns out that finding those lines accurately can be challenging. For example: if we look at one part of our picture with good lighting conditions and another part with bad lighting conditions, which parts should belong together?
Semantically segmented images usually contain hundreds or thousands of segments, so there are lots of potential answers as to where each line should go (and sub-segmentation within each larger category). These kinds of problems have led to many computer vision applications that would otherwise be impossible without semantic segmentation being solved first:

Face recognition is the process of identifying a person from a digital image or a video frame from a video source. It is used in security systems, social media, and other applications. It is also one form of biometrics that refers to the use of physiological or behavioral characteristics for identification.
Face detection involves locating human faces within an image, whereas face recognition attempts to identify who those people are by comparing them to known entries in some sort of database:

Computer vision is a subset of image processing. Image processing is the process of taking raw data from a camera and turning it into something useful for humans or machines to use. For example, we might use image processing to turn our smartphone camera’s photos into meme-worthy images, or we could use it to detect anomalies in medical x-rays (a form of computer vision).
Computer vision involves more than just taking pictures; it’s about how computers can understand what they see. This includes understanding exactly where an object is in an image, whether that object has changed position over time (motion tracking), whether two things are the same or different (object recognition), and much more!
To understand what something looks like in an image, computers need examples: lots and lots of examples! The more examples we give them, the better their performance will be at finding objects in new images based on what they’ve seen before. This process is called learning from examples because we teach our algorithm by showing it many different samples first so that once we start using it later there aren’t any surprises.
Computer vision is used in an array of industries, including medicine, robotics, and self-driving cars. Image processing is also used in many sectors. For example, it can be found in manufacturing where it’s used to inspect products or determine what the quality of a particular product should be based on things like color and shape.
Retail uses image processing as well – this includes analyzing facial expressions through cameras built into store mirrors so that store clerks can suggest certain products based on whether shoppers look happy or sad.
Gaming companies are also beginning to incorporate computer vision into their games; some use it as a way of detecting whether someone has cheated by using bots or other cheats (this can happen when players play against each other online).
The reason why this is so important is that it can help companies make more money. For example, if a retailer knows that customers are happier when they’re given certain products based on their facial expressions, they can use this information to make better decisions about how to sell things.
Image processing is also used to detect things like faces and objects in videos. This can be helpful for companies that need to monitor what’s happening in their facilities – like security guards who are trying to keep track of everyone who enters or leaves a building.
Computer vision is a complex field that can be applied in many different industries. It has been used for everything from making sure we’re not buying counterfeit items to identifying the best product package design for customers. In this article, we looked at what computer vision is and how it works, including some of its applications.