

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about a computer vision technique, object detection, and the different architectures used to locate certain objects within a picture.
Mainly, we’ll walk through SSD (Single-Shot object Detection) and YOLO (You Only Look Once) algorithms that are used to recognize objects by creating boundary boxes within an image, and we’ll explore their different approach to object detection tasks.
The architecture of a Single Shot MultiBox Detector looks as follows:
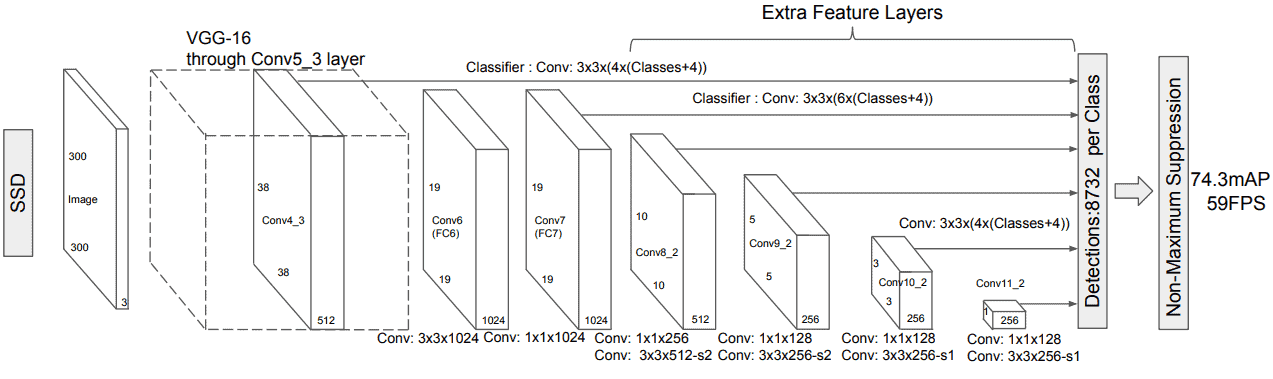
The SSD algorithm was introduced by Wei Liu in 2016. The authors presented a method that could identify objects by using a feed-forward convolutional network by using a single forward pass. Single shot means that in a single forward pass of the neural network (single run of the algorithm), the identification and classification of an object are possible. As we can see, the base of the model consists of a VGG-16 convolutional neural network followed by some additional convolutional layers, which reduce the dimensions of the input at each layer. The network constructs a group that includes all the default bounding boxes within an image and produces the possibility of the presence of an object inside this box by applying convolutional filters to the feature maps that are created. We can notice that the convolutional layers are applied at different scales in order for the network to be capable of detecting objects of different scales and sizes.
The architecture results in the Non-Maximal Suppression (NMS), which is a pruning technique that discards the bounding boxes with a confidence level less than a certain threshold.
The architecture of You Only Look Once is shown below:
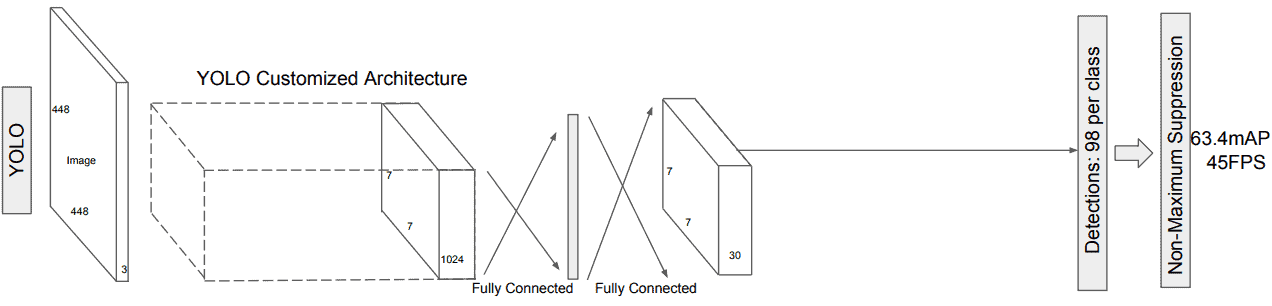
The YOLO algorithm was introduced by Joseph Redmon in 2016. The authors presented an end-to-end method that can predict object bounding boxes and class probabilities of them within an entire image simultaneously. Like SSD, YOLO can identify objects by using a single forward pass. As we can see, YOLO’s architecture is influenced by the GoogLeNet model and includes 24 convolutional layers, which are preceded by 2 fully connected layers.
An input image is divided into a fixed-size grid, while each grid is responsible for predicting a number of bounding boxes and calculating the confidence score of each box, whether it contains an object or not.
The object can be identified if the middle point of a bounding box is held in a single cell of the image. In case the single cell holds more than one middle point, there is an overlap of the boundary boxes. YOLO deals with this occasion by checking the overlap score and comparing it with a threshold in the Non-Maximum Suppression unit and discards boxes with overlap greater than 50%.
Although SSD and YOLO architectures seem to have a lot in common, their main difference lies in how they approach the case of multiple bounding boxes of the same object. First of all, SSD makes use of fixed-size anchor boxes and takes into consideration the IoU metric (a metric that specifies the amount of overlap between the predicted and ground truth bounding box) with a threshold greater than 0.5.
Moreover, the convolutional model of SSD differs for each feature layer, which is not the case with YOLO’s architecture.
Another difference is that YOLO is limited to predicting bounding boxes since each grid cell is capable of producing predictions for only two boxes and can only belong in one class. This fact practically affects the network, which cannot handle well images that contain small objects, such as birds, in contrast with SSD.
As for performance issues, SSD is more accurate in results than YOLO. Despite this, YOLO is faster and may seem more useful in real-time applications. One should take into consideration this trade-off of accuracy and speed in order to decide which model is more suitable for his application.
Object detection algorithms can be applied in a wide variety of applications. Both YOLO and SSD can be used in biomedical tasks, for tumor detection, or for decoding DNA chains and locating nucleotides.
Also, autonomous driving is a rapidly developing area. Autonomous cars need to have fast and accurate detectors that can detect pedestrians, traffic lights, and roads in real-time.
Another application that can be used for the models is cropping. The models can use satellite images to predict whether crops need more irrigation and distinguish useful crops from non in order to increase the aid and augment crop production.
In order to choose a model, we have to understand the needs of the application and whether we need to make quick or more accurate predictions. A medical application that may be responsible for detecting heart attacks needs a model that can make predictions quick and is not so interested in any false positive results in terms of accuracy.
In this article, we walked through a computer vision task, object detection. In particular, we discussed in detail two main object detection algorithms, SSD and YOLO. We talked about their different model architecture and the applications that they can be applied, depending on their needs.