

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
What Is Retrieval-Augmented Generation (RAG)?
Last updated: February 28, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll explore the retrieval-augmented generation (RAG) process and learn how it works.
2. Overview of Natural Language Processing (NLP)
Natural Language Processing (NLP), as a subset of artificial intelligence, helps computers grasp the meaning of text and speech, including the intent, sentiment, and context. It breaks down language into components like words, phrases, and sentences to analyze their relationships. It can create human-like text, translate languages, write creative content, and answer a question informally.
NLP algorithms undergo training with extensive volumes of text and speech data, enabling them to grasp intricate patterns and language rules. They integrate insights from grammar, syntax, and semantics to comprehend language structure and significance.
NLP research might change how people communicate with computers and their environment, making it more natural and intuitive.
3. Retrieval-Based Model and Generative Model
3.1. Retrieval-Based Model
A retrieval-based model is a class of NLP models that generate responses by selecting and adapting the most relevant examples from a repository of pre-existing responses or a knowledge base. This repository can be formed from a preprocessed dataset or curated from external sources like FAQs, customer support logs, or online forums. Within the knowledge base are pairs of input queries and their corresponding responses, utilized as training examples for the model.
These models are commonly used in applications like question-answering systems, information retrieval systems, and chatbots, where accurate and relevant responses based on user queries are crucial. They prove efficient and effective for tasks where the relevant information already exists in the database or corpus being searched.
An example of a retrieval-based model is the OpenAI Generative Pre-Trained Transformer 3 (GPT-3) model.
3.2. Generative Model
Generative models designed to produce fresh data samples resembling the training data they trained. It learns from the training data’s structure to generate new samples, capturing its essential traits, and requires even more processing power and training time than retrieval-based models.
These models have numerous applications in various fields, such as image generation, text generation, speech synthesis, and data augmentation. It plays a crucial role in tasks where generating new data samples that capture the underlying characteristics of the training data is essential.
Some common types of generative models are Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Autoregressive Models.
4. What Is Retrieval-Augmented Generation (RAG)?
RAG is an innovative approach in natural language processing (NLP) that combines the strengths of retrieval-based models and generative models to improve the accuracy, relevance, and explainability of text generation tasks. This integrated approach promotes more fluid and lifelike conversations in conversational AI systems, ensuring it upholds accuracy and relevance.
The use of RAG in natural language processing offers several benefits, including contextual relevance, improved content quality, diverse responses, reduced data sparsity, and real-time response generation. These benefits make it a valuable approach for a wide range of NLP tasks and applications, enhancing the quality and effectiveness of text generation systems.
5. Architecture
The architecture of RAG typically consists of two main components: the retriever and the generator. These components work together to integrate retrieval-based and generative approaches in NLP tasks such as question-answering and dialogue generation.
The process starts with an initial input, which could be given to the retrieval system in the form of a question or prompt. The retrieval module searches the knowledge database for relevant data related to the input. This involves the utilization of methods such as keyword matching, semantic similarity evaluations, or more sophisticated retrieval approaches:
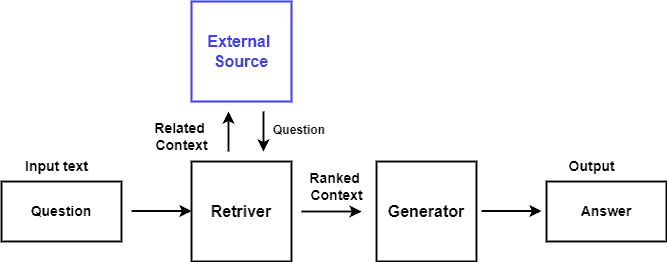
The retrieval module deems relevant and returns a set of retrieved documents or passages to the initial input. We then score the retrieved passages based on their relevance to the input query. This scoring mechanism helps prioritize passages that are most likely to contain useful information for generating a response.
These retrieved pieces of information serve as the context for the subsequent generation step. The generation module commonly includes a transformer-based language model, such as Generative Pre-trained Transformer (GPT) or Bidirectional Encoder Representations from Transformers (BERT).
We encode the retrieved documents or passages, along with the initial input, into a format suitable for input to the transformer model. This encoding may involve techniques like tokenization and embedding.
The transformer model generates a response or continuation based on the encoded input. The final output of the RAG model is a response or continuation generated by the generation module. We expect this output to be coherent and contextually relevant to both the initial input and the retrieved context from the database.
6. Advantages of Using RAG
RAG uses real-world information to give more accurate responses, avoiding made-up details or personal opinions that can come from models creating responses from nothing. We can use different sets of information to change RAG to work in different areas. This makes it flexible and handy for many different uses. RAG doesn’t need to adjust a lot on huge sets of data like other models. This makes training faster, uses less computer power, and could save money overall.
When the outside information changes, RAG learns it automatically and gets better at giving useful answers as time goes on. RAG can also improve user satisfaction in conversational AI systems by offering accurate, contextually relevant, and varied responses, resulting in a more enjoyable user experience.
It handles out-of-vocabulary tokens better by using relevant retrieved passages, reducing nonsensical or irrelevant responses.
7. Challenges and Limitations
RAG depends on outside sources, so their quality and reliability matter. Bad or biased information can lead to incorrect responses. RAG’s retrieval process can be computationally expensive, especially with large knowledge bases or web searches, potentially slowing response times. Smoothly combining the retrieval and generation parts requires careful planning and optimization, which might pose challenges during training and deployment.
Finally, RAG focuses on factual accuracy. However, creating imaginative or fictional content may be challenging, which restricts its applicability in creative content generation.
8. Future of RAG
Future research may enhance its efficiency in utilizing external knowledge for better NLP performance. Advancements may focus on enhancing the scalability of RAG models to handle larger knowledge bases and datasets. This involves refining retrieval strategies and model architectures to efficiently process vast external information, enhancing RAG’s response quality.
Future versions of RAG could integrate multimodal abilities, enabling the model to utilize textual, visual, and other data modalities. This advancement could result in more nuanced responses, especially in tasks involving diverse analysis and generation data types.
Future efforts may focus on mitigating biases, improving privacy, and enhancing transparency in RAG systems.
9. Conclusion
In this article, we discussed retrieval-augmented generation (RAG) and its major components. RAG blends retrieval and generative methods to create precise, varied, and contextually appropriate responses in NLP.