

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Comparison Between BERT and GPT-3 Architectures
Last updated: January 26, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll explain the difference between BERT and GPT-3 architectures. Although both models are constructed as large language models using transformers, their applications vary significantly. Firstly, we’ll briefly introduce the attention mechanism, transformers, and types of transformers. Following that, we’ll explore more in-depth BERT and GPT-3 models.
2. Attention Mechanism and Transformers
For many years, neural networks have been used in natural language processing (NLP). However, significant advancements and the community’s growth truly started with introducing the attention mechanism.
This innovative approach was first introduced in 2017 through the well-known paper “Attention is All You Need,” authored by researchers from Google Brain. The presented technique enabled neural networks to focus on specific parts of the input sequence while processing the data.
The models that use attention mechanisms, particularly self-attention, were called “transformers”. Transformers demonstrated state-of-the-art performance across various NLP tasks, including machine translation, classification, generation, etc. The transformer model architecture from the “Attention is All You Need” paper is below:
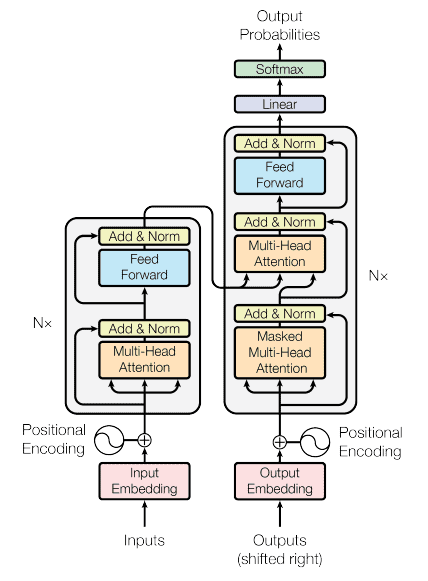
3. Types of Transformers
The original “Attention is All You Need” paper introduced a transformer model consisting of two components, an encoder and a decoder. However, over time, subsequent developments led to the creation of new transformer models designed with either an encoder or a decoder component alone. This evolution resulted in transformer models specialized for particular tasks.
Following that, we can categorize transformer models as:
- Encoder-only transformers – suitable for tasks that require understanding the input, such as sentence classification and named entity recognition. Some of the popular models are BERT, RoBERTa, and DistilBERT
- Decoder-only transformers – effective for generative tasks such as text generation. Some of the popular models are GPT, LLaMA, and Falcon
- Encoder-decoder transformers – suitable for generative tasks that require input, such as translation or summarization. Popular encoder-decoder models are BART, T5, and UL2
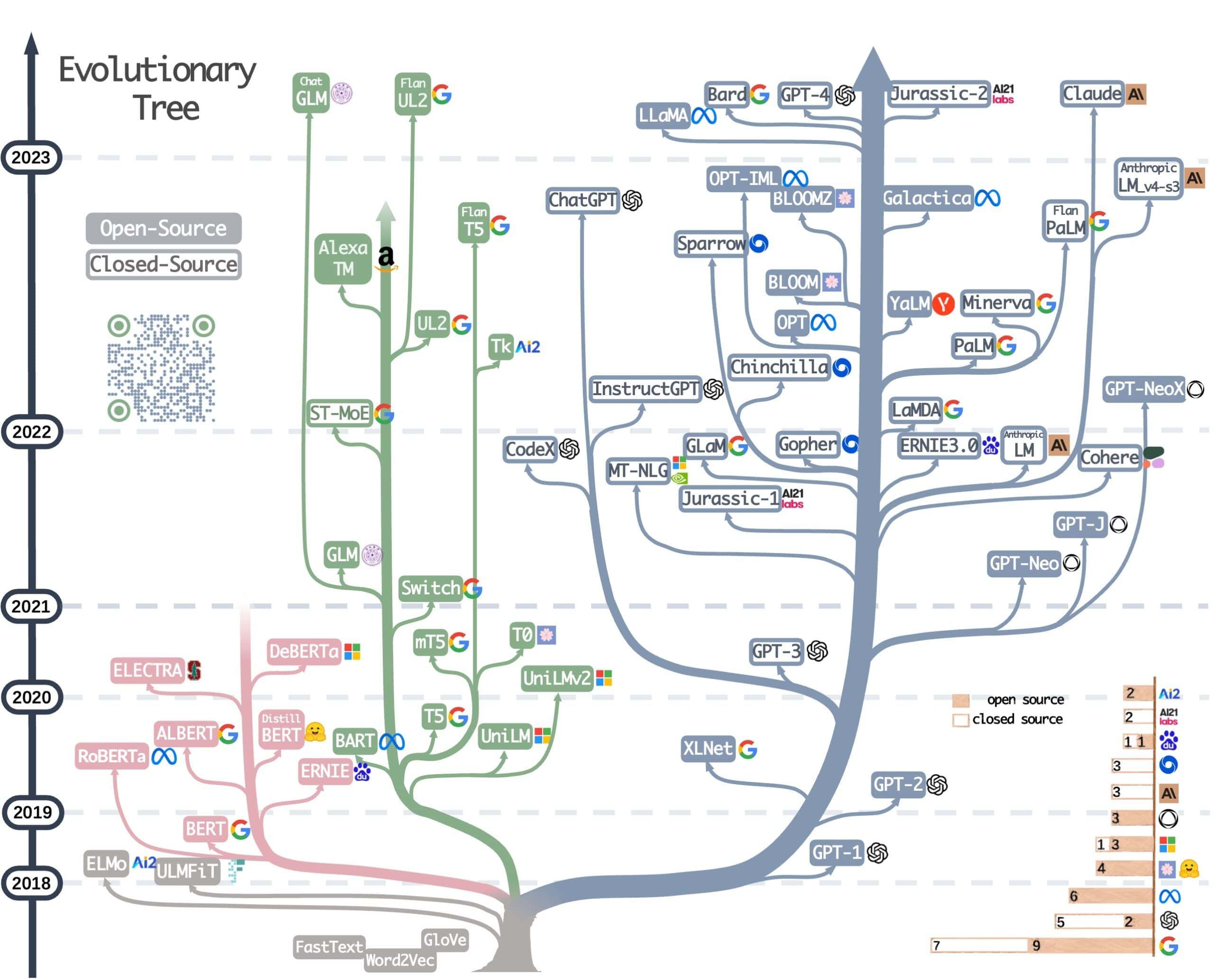
All models above are large language models (LLM). They operate with human language and usually have from a few hundred million to a few hundred trillion parameters. LLMs are a trendy topic today. Many big tech companies actively participating in their development. The image below illustrates the progress of the most popular LLMs:
4. BERT Architecture
BERT (Bidirectional Encoder Representations from Transformers) is a language model developed by Google in 2018. The key technical innovation in this model was its bi-directional nature. The BERT paper’s results show that a bi-directionally trained language model can better understand language context and flow than single-directional language models.
Nowadays, there are many types of BERT models. Here, we’ll present the architecture of the two original types of BERT: base and large. These models use the same architecture of encoders as the original transformers. In one sentence, BERT is a stack of multiple encoders from the original transformer model:
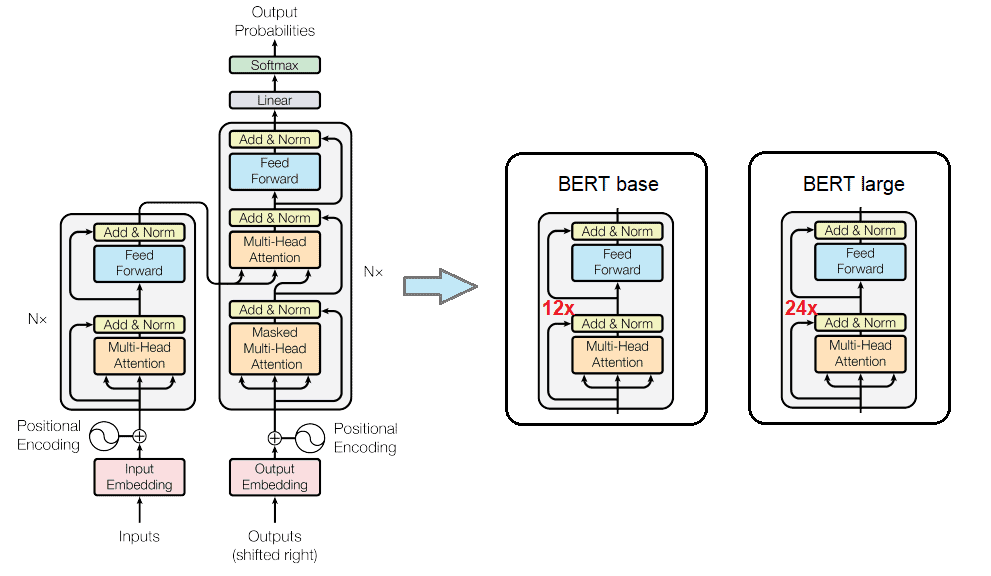
The base model has 12 transformer layers, while the large has 24. In addition, there is a difference in feed-forward networks (number of hidden neurons). The base model has 768 neurons in the feed-forward network, while the large model has 1024. In total, the BERT base has 110 million parameters, and BERT large has 340 million. The size of the input and hidden layer embeddings in BERT are the same. Also, both models can accept up to 512 tokens at a time, which means that the input embedding matrix has a size of 512 times the hidden size.
It’s important to mention that BERT is pre-trained using a masked language model (MLM) objective. It learns to predict masked words in a sentence. Before feeding word sequences into BERT, 15% of the words in each sequence are randomly replaced with a [MASK] token. The model then tries to predict the original value of the masked words based on the context provided by the other non-masked words in the sequence.
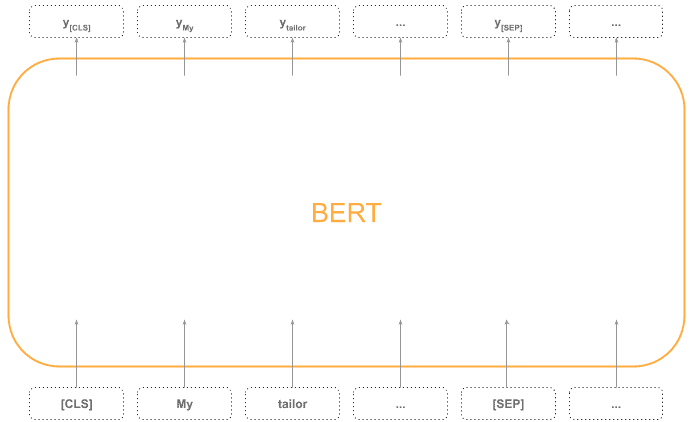
This bidirectional training allows BERT to capture contextual information from both the left and right sides of each word:
4.1. BERT Applications
Thanks to the MML, BERT learns contextualized representations of words by considering both the left and right context in a given sentence. But after that, we can fine-tune BERT model for our specific purposes.
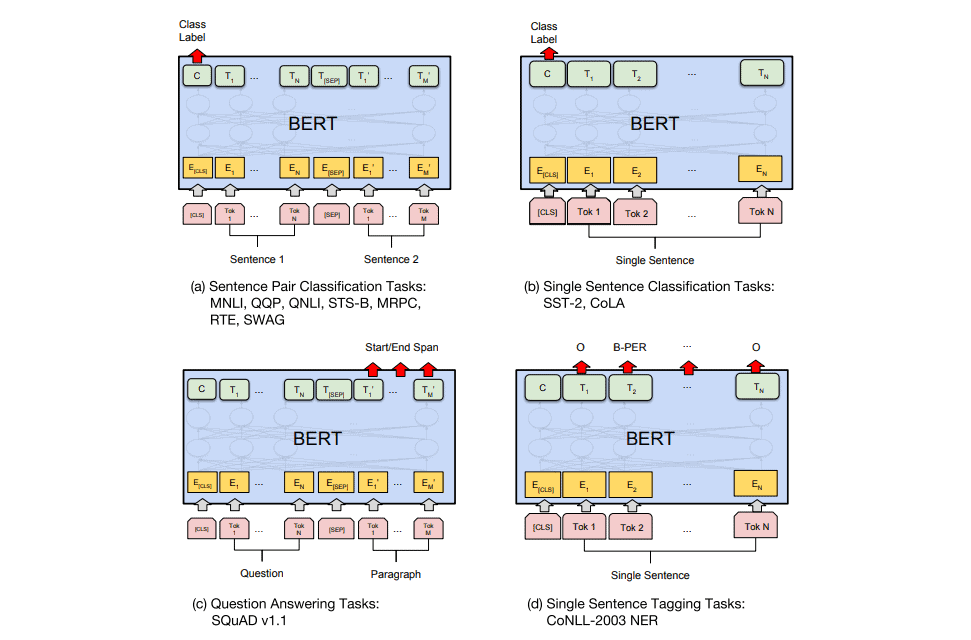
For example, the first input token [CLS] stands for “classification”, and the first output can represent sentence classification. Besides that, BERT can be adjusted and fine-tuned for some other tasks such as sentence pair classification, question answering, sentence tagging, and similar:
5. GPT-3 Architecture
Firstly, it’s important to note that GPT-3 is not an open-source model, which implies that the exact details of its development and architecture are not publicly available. However, despite this limitation, there is some publicly available information about this model.
GPT-3 (Generative Pre-trained Transformer 3) follows a similar architecture to the original GPT models based on the transformer architecture. It uses a transformer decoder block with a self-attention mechanism. It has 96 attention blocks, each containing 96 attention heads with a total of 175 billion parameters:
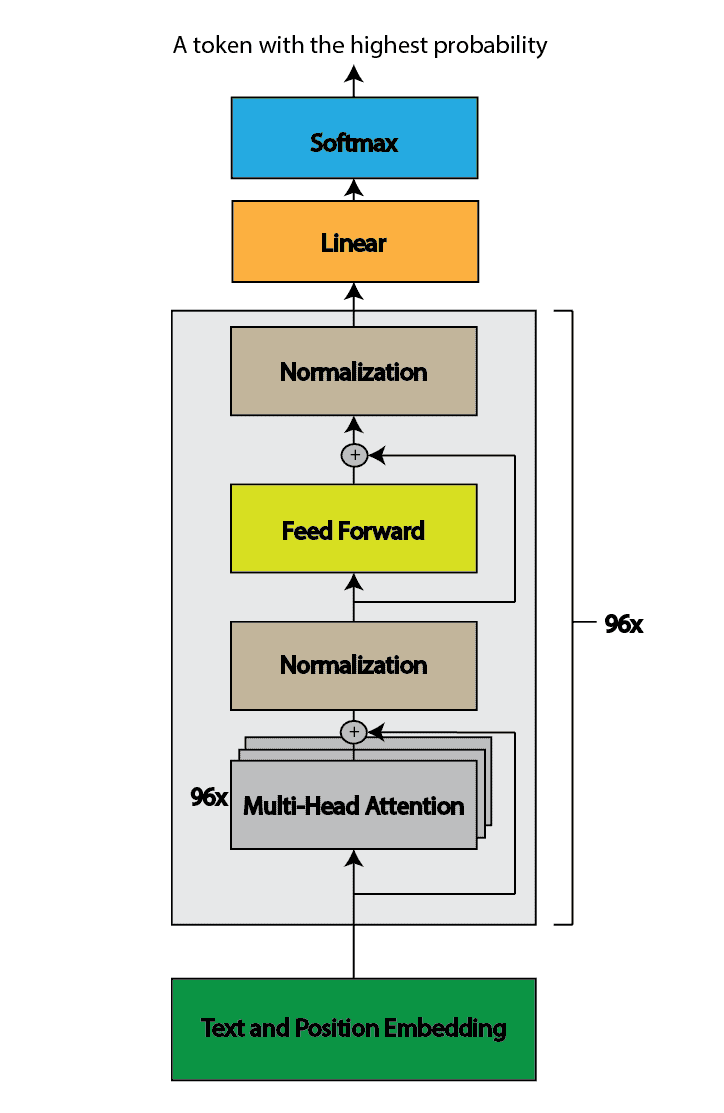
GPT-3 is much bigger than BERT. It can accept up to 2048 tokens at a time, and the input embedding vectors have 12288 dimensions.
In contrast to BERT, GPT-3 is a unidirectional model. An autoregressive model predicts the next token in a sequence based on the preceding context. This model predicts only a single token in one forward pass, then appends that token back to the input and autoregressively generates the next token until the stop token is not generated.
It’s essential to notice that both BERT and GPT models share the same foundational architectural components, including attention, normalization, and feed-forward layers. The key difference between them comes from the distinct pre-training tasks employed during the model training process. As a result of this pre-training, these shared components have been tailored in distinct ways, contributing to their different behaviours.
6. Conclusion
In this article, we’ve explained the architectures of two language models, BERT and GPT-3. Both models are transformers and share similar components in their architecture.
While original GPT-1 and BERT have around the same number of components, GPT-3 model is more than a thousand times bigger. This is because generative AI is a widely discussed subject, leading to significant investments from major tech companies in developing larger models. These models aim to achieve superior performance and be more suitable for commercialization.
In summary, both models have very similar components but were trained for entirely different objectives. This leads to other behaviours and distinct applications.