

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about node impurity in decision trees. A decision tree is a greedy algorithm we use for supervised machine learning tasks such as classification and regression.
Firstly, the decision tree nodes are split based on all the variables. During the training phase, the data are passed from a root node to leaves for training. A decision tree uses different algorithms to decide whether to split a node into two or more sub-nodes. The algorithm chooses the partition maximizing the purity of the split (i.e., minimizing the impurity). Informally, impurity is a measure of homogeneity of the labels at the node at hand:
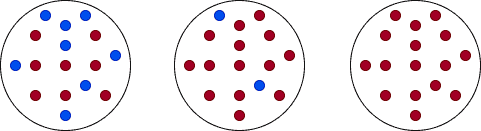
There are different ways to define impurity. In classification tasks, we frequently use the Gini impurity index and Entropy.
Gini Index is related to the misclassification probability of a random sample.
Let’s assume that a dataset  contains examples from
contains examples from  classes. Its Gini Index,
classes. Its Gini Index,  , is defined as:
, is defined as:
(1) 
where  is the relative frequency of class
is the relative frequency of class  in , i.e., the probability that a randomly selected object belongs to class .
in , i.e., the probability that a randomly selected object belongs to class .
As we can observe from the above equation, Gini Index may result in values inside the interval ![[0, 0.5]](/wp-content/ql-cache/quicklatex.com-68c9d4b30d8f8d3a649411af4d1dbc44_l3.svg "Rendered by QuickLaTeX.com") . The minimum value of zero corresponds to a node containing the elements of the same class. In case this occurs, the node is called pure. The maximum value of 0.5 corresponds to the highest impurity of a node.
. The minimum value of zero corresponds to a node containing the elements of the same class. In case this occurs, the node is called pure. The maximum value of 0.5 corresponds to the highest impurity of a node.
In this example, we’ll compute the Gini Indices for 3 different cases of a set with 4 balls of two different colors, red and blue:
![\[gini = 1 - \left(P(ball = red)^2 + P(ball = blue)^2\right) = 1 - (1 + 0) = 0\]](/wp-content/ql-cache/quicklatex.com-03178ed050fa7f5ac3d42af8f8535842_l3.svg "Rendered by QuickLaTeX.com")
![\[gini = 1 - \left(P(ball = red)^2 + P(ball = blue)^2\right) = 1 - \left(\left(\frac{1}{2}\right)^2 + \left(\frac{1}{2}\right)^2\right) = 0.5\]](/wp-content/ql-cache/quicklatex.com-feb5ec6ce739f898c6c6ff05c2a9b904_l3.svg "Rendered by QuickLaTeX.com")
![\[gini = 1 - \left(P(ball = red)^2 + P(ball = blue)^2\right) = 1 - \left(\left(\frac{3}{4}\right)^2 + \left(\frac{1}{4}\right)^2\right) = 0.375\]](/wp-content/ql-cache/quicklatex.com-26774e1805b1b0048d64045c59ca7593_l3.svg "Rendered by QuickLaTeX.com")
Ιn statistics, entropy is a measure of information.
Let’s assume that a dataset associated with a node contains examples from classes. Then, its entropy is:
(2) 
where is the relative frequency of class in . Entropy takes values from ![[0, 1]](/wp-content/ql-cache/quicklatex.com-944fdd98d4f1854c8720f98d8b20b6ad_l3.svg "Rendered by QuickLaTeX.com") . As is the case with the Gini index, a node is pure when
. As is the case with the Gini index, a node is pure when  takes its minimum value, zero, and impure when it takes its highest value, 1.
takes its minimum value, zero, and impure when it takes its highest value, 1.
Let’s compute the entropies for the same examples as above:
![\[entropy = P(ball = red) \cdot log_2 P(ball = red) + P(ball = blue) \cdot log_2 P(ball = blue) = \frac{4}{4} \cdot log_2\frac{4}{4} - \frac{0}{4} \cdot log_2\frac{0}{4} = 0\]](/wp-content/ql-cache/quicklatex.com-ba59773932c9932bd2af5ee6be657e67_l3.svg "Rendered by QuickLaTeX.com")
![\[entropy = P(ball = red) \cdot log_2 P(ball = red) + P(ball = blue) \cdot log_2 P(ball = blue) = \frac{2}{4} \cdot log_2\frac{2}{4} - \frac{2}{4} \cdot log_2\frac{2}{4} = 1\]](/wp-content/ql-cache/quicklatex.com-f8f46c401aa3e27c2e16351823618aa8_l3.svg "Rendered by QuickLaTeX.com")
![\[entropy = P(ball = red) \cdot log_2 P(ball = red) + P(ball = blue) \cdot log_2 P(ball = blue) = \frac{3}{4} \cdot log_2\frac{3}{4} - \frac{1}{4} \cdot log_2\frac{1}{4} = 0.811\]](/wp-content/ql-cache/quicklatex.com-6a910318c70392856b99697b48b0ecec_l3.svg "Rendered by QuickLaTeX.com")
The quality of splitting data is very important during the training phase. When splitting, we choose to partition the data by the attribute that results in the smallest impurity of the new nodes.
We’ll show how to split the data using entropy and the Gini index.
The information gain is the difference between a parent node’s entropy and the weighted sum of its child node entropies.
Let’s assume a dataset with  objects is partitioned into two datasets:
objects is partitioned into two datasets:  and
and  of sizes
of sizes  and
and  . Then, the split’s Information Gain (
. Then, the split’s Information Gain ( ) is:
) is:
(3) 
In general, if splitting into  subsets
subsets  with
with  objects, respectively, the split’s Information Gain () is:
objects, respectively, the split’s Information Gain () is:
(4) 
Let’s consider dataset , which shows if we’re going to play tennis or not based on the weather:
| Day | Outlook | Temperature | Humidity | Wind | Play Tennis? |
|---|---|---|---|---|---|
| D1 | Sunny | Hot | High | Weak | No |
| D2 | Sunny | Hot | High | Strong | No |
| D3 | Overcast | Hot | High | Weak | Yes |
| D4 | Rain | Mild | High | Weak | Yes |
| D5 | Rain | Cool | Normal | Weak | Yes |
| D6 | Rain | Cool | Normal | Strong | No |
| D7 | Overcast | Cool | Normal | Weak | Yes |
| D8 | Sunny | Mild | High | Weak | No |
| D9 | Sunny | Cool | Normal | Weak | Yes |
| D10 | Rain | Mild | Normal | Strong | Yes |
| D11 | Sunny | Mild | Normal | Strong | Yes |
| D12 | Overcast | Mild | High | Strong | Yes |
| D13 | Overcast | Hot | Normal | Weak | Yes |
| D14 | Rain | Mild | High | Strong | No |
It contains 9 positive outcomes (Yes) and 5 negatives (No). So, the starting structure is ![S=[9+, 5-]](/wp-content/ql-cache/quicklatex.com-1c9b95addb115c12f6eca9ebbb152bdc_l3.svg "Rendered by QuickLaTeX.com") . We want to determine the attribute that offers the highest Information Gain.
. We want to determine the attribute that offers the highest Information Gain.
Let’s see what happens if we split by Outcome. Outlook has three different values: Sunny, Overcast, and Rain. As we see, the possible splits are ![[2+, 3-], [4+, 0-]](/wp-content/ql-cache/quicklatex.com-04fe4da34ab13ebdf8ed6840cd2b3ba9_l3.svg "Rendered by QuickLaTeX.com") and
and ![[3+, 2-]](/wp-content/ql-cache/quicklatex.com-5672d85687d0dc4b7cc8393def059f4e_l3.svg "Rendered by QuickLaTeX.com") (
( and
and  stand for entropy and split):
stand for entropy and split):
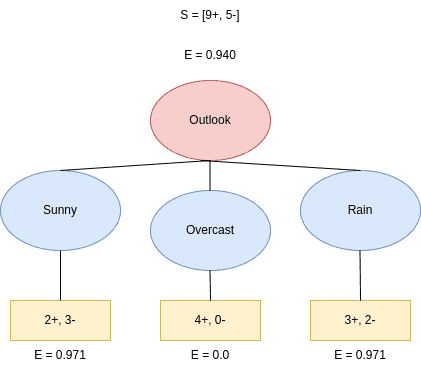
Firstly, we calculate the entropies. They are:  and
and  . Therefore, the Information Gain based on the Outlook,
. Therefore, the Information Gain based on the Outlook,  , is:
, is:
(5) 
Next, we split the tree based on the Wind feature. It can take two values: Weak and Strong, with the possible splits ![[6+, 2-]](/wp-content/ql-cache/quicklatex.com-5d23f45fc4650644c8a6e4f66dba9f51_l3.svg "Rendered by QuickLaTeX.com") and
and ![[3+, 3-]](/wp-content/ql-cache/quicklatex.com-27cafc7aa1172cd995e97e7a6189ceb6_l3.svg "Rendered by QuickLaTeX.com") :
:
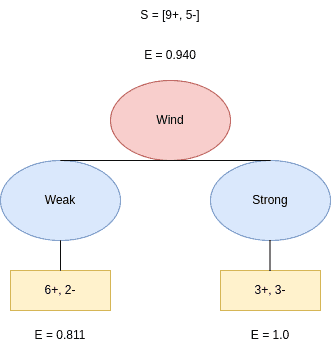
The corresponding entropies are:  and
and  . Therefore,
. Therefore,  is:
is:
(6) 
Following this idea, we calculate the gains for Humidity and Temperature as well.
(7) 
(8) 
We see that the feature with the maximum Information Gain is Outlook. Thus, we conclude that Outlook is the best attribute to split the data at the tree’s root.
We can split the data by the Gini Index too. Let’s compute the required probabilities:
(9) 
Out of the 14 days in the above example, Sunny, Overcast, and Rain occur 5, 4, and 5 times, respectively. Then, we compute the probabilities of a Sunny day and playing tennis or not. Out of the 5 times when Outlook=Sunny, we played tennis on 2 and didn’t play it on 3 days:
![\[P(Outlook = Sunny \;\&\; Play \; Tennis = Yes) = \frac{2}{5}\]](/wp-content/ql-cache/quicklatex.com-7e01c6bea8a0f7657118254fc012bd0f_l3.svg "Rendered by QuickLaTeX.com")
![\[P(Outlook = Sunny \;\&\; Play \;Tennis = No) = \frac{3}{5}\]](/wp-content/ql-cache/quicklatex.com-689a87b13c42581d65aad50a9209e355_l3.svg "Rendered by QuickLaTeX.com")
Having calculated the required probabilities, we can compute the Gini Index of Sunny:
![\[gini(Outlook = Sunny) = 1 - \left(\left( \frac{2}{5}\right)^2 + \left( \frac{3}{5}\right)^2 \right) = 0.48\]](/wp-content/ql-cache/quicklatex.com-8d03fd5da574e841f2fd8586f6e17f02_l3.svg "Rendered by QuickLaTeX.com")
We follow the same steps for Overcast and Rain:
![\[P(Outlook = Overcast \;\&\; Play \; Tennis = Yes) = \frac{4}{4}\]](/wp-content/ql-cache/quicklatex.com-214bec6309aac6b91689229bfbf91990_l3.svg "Rendered by QuickLaTeX.com")
![\[P(Outlook = Overcast \;\&\; Play \;Tennis = No) = \frac{0}{4}\]](/wp-content/ql-cache/quicklatex.com-f7318a717698c014f5fb20f049408945_l3.svg "Rendered by QuickLaTeX.com")
![\[gini(Outlook = Overcast) = 1 - \left(\left( \frac{4}{4}\right)^2 + \left( \frac{0}{4}\right)^2 \right) = 0\]](/wp-content/ql-cache/quicklatex.com-17a30d07808a60aa6087c5d386009e74_l3.svg "Rendered by QuickLaTeX.com")
![\[P(Outlook = Rain \;\&\; Play \; Tennis = Yes) = \frac{3}{5}\]](/wp-content/ql-cache/quicklatex.com-9d8c81d1aade12f5cab24a592ae90554_l3.svg "Rendered by QuickLaTeX.com")
![\[P(Outlook = Rain \;\&\; Play \;Tennis = No) = \frac{2}{5}\]](/wp-content/ql-cache/quicklatex.com-6789bd2be0918a61003641db0f94b29f_l3.svg "Rendered by QuickLaTeX.com")
![\[gini(Outlook = Rain) = 1 - \left(\left( \frac{3}{5}\right)^2 + \left( \frac{2}{4}\right)^2 \right) = 0.48\]](/wp-content/ql-cache/quicklatex.com-7f87e993c444b25f4f609d24a9a896da_l3.svg "Rendered by QuickLaTeX.com")
Therefore, the weighted sum  of the above Gini Indices is:
of the above Gini Indices is:
(10) 
Similarly, we compute the Gini Index of Temperature, Humidity, and Wind:
(11) 
We conclude that Outlook has the lowest Gini Index. Hence, we’ll choose it as the root node.
In this article, we talked about how we can compute the impurity of a node while training a decision tree. In particular, we talked about the Gini Index and entropy as common measures of impurity. By splitting the data to minimize the impurity scores of the resulting nodes, we get a precise tree.