Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 16, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explain how weights and bias are updated during the backpropagation process in neural networks. First, we’ll briefly introduce neural networks as well as the process of forward propagation and backpropagation. After that, we’ll mathematically describe in detail the weights and bias update procedure.
The purpose of this tutorial is to make clear how bias is updated in a neural network in comparison to weights.
Neural networks are algorithms explicitly designed to simulate biological neural networks. In general, the idea was to create an artificial system that behaves like the human brain. Depending on the type of network, neural networks are based on interconnected neurons. There are many types of neural networks, but we can broadly divide them into three classes:
The main distinction between them is the type of neurons that comprise them, as well as the manner in which information flows through the network. In this article, we’ll explain backpropagation using regular neural networks.
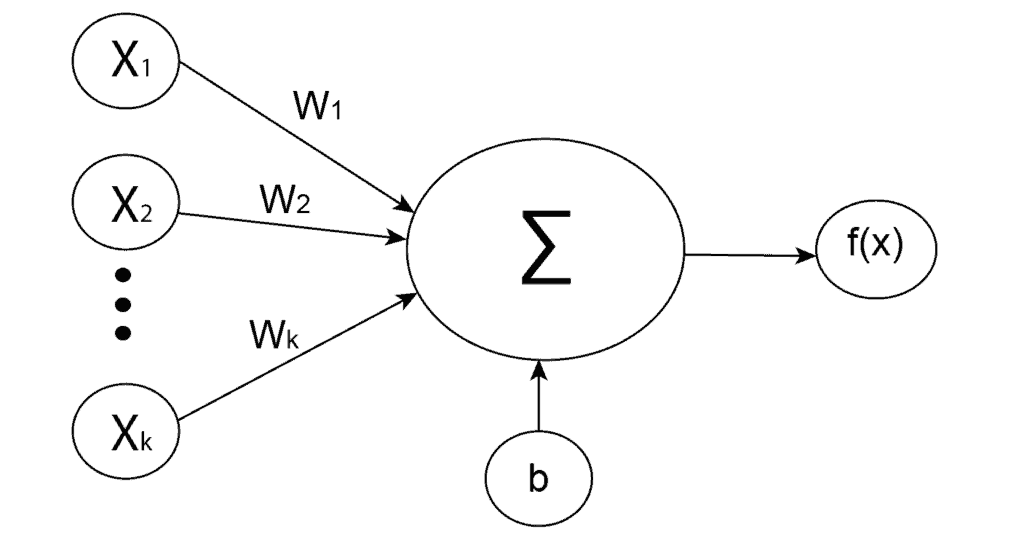
Artificial neurons serve as the foundation for all neural networks. They are units modeled after biological neurons. Each artificial neuron receives inputs and produces a single output, which we also send to a network of other neurons. Inputs are usually numeric values from a sample of external data, but they can also be other neurons’ outputs. The neural network’s final output neurons represent the value that defines prediction.
To obtain the output of the neuron, we need to compute the weighted sum of all the inputs and weights of the connections. Then we add bias to the sum and use the activation function. Mathematically, we define the weighted sum as:
(1) 
where  are weights,
are weights,  are inputs and
are inputs and  bias. After that, an activation function
bias. After that, an activation function  is applied to the weighted sum
is applied to the weighted sum  , which represents the final output of the neuron:
, which represents the final output of the neuron:
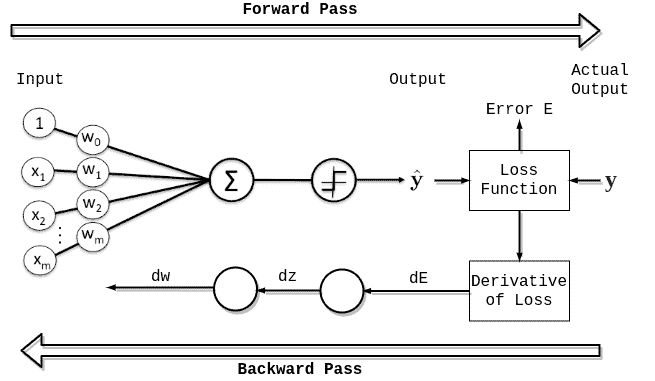
During the neural network training, there are two main phases:
First comes forward propagation which means that the input data is fed in the forward direction through the network. Overall, this process
covers the data flow from the initial input, passing by every layer in the network, and finally the computation of the prediction error. This is a typical procedure in feed-forward neural networks but for some other networks, such as RNNs, the forward propagation is slightly different.
To conclude, forward propagation is a process that starts with input data and ends when the error of the network is calculated.
After forward propagation comes backpropagation and it’s certainly the essential part of the training. In brief, it’s a process of fine-tuning the weights of a network based on the errors or loss obtained in the previous epoch (iteration). Proper weight tuning ensures lower error rates while increasing the model’s reliability by enhancing its generalization.
Initially, we have a neural network that doesn’t give accurate predictions because we haven’t tuned the weights yet. The point of backpropagation is to improve the accuracy of the network and at the same time decrease the error through epochs using optimization techniques.
There are many different optimization techniques that are usually based on gradient descent methods but some of the most popular are:
In brief, gradient descent is an optimization algorithm that we use to minimize loss function in the neural network by iteratively moving in the direction of the steepest descent of the function. Therefore, in order to find the direction of the steepest descent, we need to calculate gradients of the loss function with respect to weights and bias. After that, we’ll be able to update weights and bias using negative gradients multiplied by the learning rate:
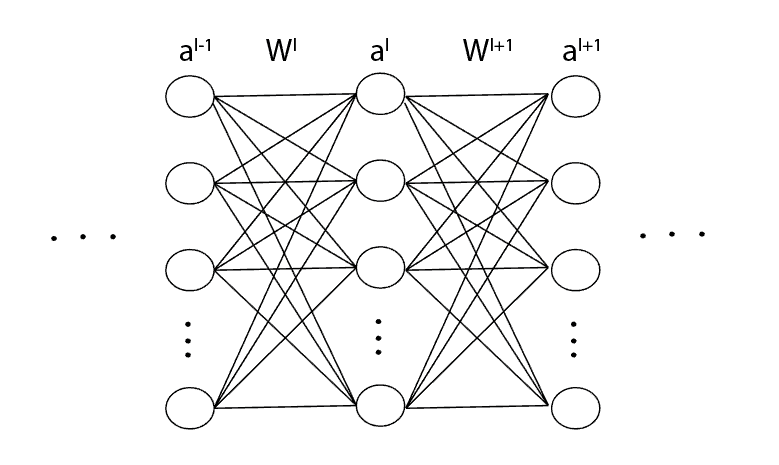
To begin with, let’s consider the snippet of the neural network presented below, where  indicates -th layer,
indicates -th layer,  is the activation column-vector or vector with neurons and
is the activation column-vector or vector with neurons and  is the weight matrix:
is the weight matrix:
Following neural network definition, the formula for one specific neuron  , in the -th layer is
, in the -th layer is
(2) 
where  is activation function,
is activation function,  weights and bias.
weights and bias.
Firstly, if we want to update one specific weight  , we would need to calculate the derivative of the cost function
, we would need to calculate the derivative of the cost function  with respect to that particular weight, or
with respect to that particular weight, or
(3) 
Now, if we apply the chain rule and extend the derivative, we’ll get
(4) 
or consequently presented graphically:
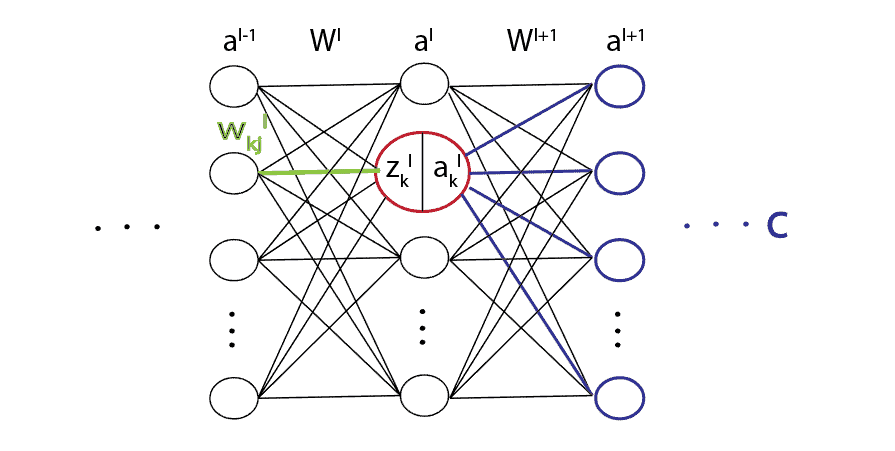
Basically, using the chain rule, we break a large problem into smaller ones and solve them one by one. Using the chain rule again, we would also need to break  even further into:
even further into:
(5) 
After that, let’s define the error signal of a neuron  in layer as
in layer as
(6) 
From the equation (5), we also can extract the recurrent expression
(7) 
or using the error signal notation
(8) 
This recurrent relation propagates to the last layer in the network and the error signal of a neuron in the last layer  is equal to
is equal to
(9) 
Finally, everything is explained and we can substitute the error signal (6) in the initial derivative (5)
(10) 
Lastly, we update the weight as
(11) 
where  is the learning rate.
is the learning rate.
Generally, a bias update is very similar to a weight update. Due to the derivative rule that for every 
(12) 
we also have that for any 
(13) 
Likewise, for -th bias in layer , we have that
(14) 
Now, similarly to weight update (11), we can update bias as
(15) 
In this article, we briefly explained the neural network’s terms with artificial neurons, forward propagation, and backward propagation. After that, we provided a detailed mathematical explanation of how bias is updated in neural networks and what is the main difference between bias update and weight update.
This article has both theoretical and mathematical parts and therefore requires some prior knowledge about derivatives.