

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Introduction
Apache Spark is an open-source cluster-computing framework. It provides elegant development APIs for Scala, Java, Python, and R that allow developers to execute a variety of data-intensive workloads across diverse data sources including HDFS, Cassandra, HBase, S3 etc.
Historically, Hadoop’s MapReduce prooved to be inefficient for some iterative and interactive computing jobs, which eventually led to the development of Spark. With Spark, we can run logic up to two orders of magnitude faster than with Hadoop in memory, or one order of magnitude faster on disk.
2. Spark Architecture
Spark applications run as independent sets of processes on a cluster as described in the below diagram:
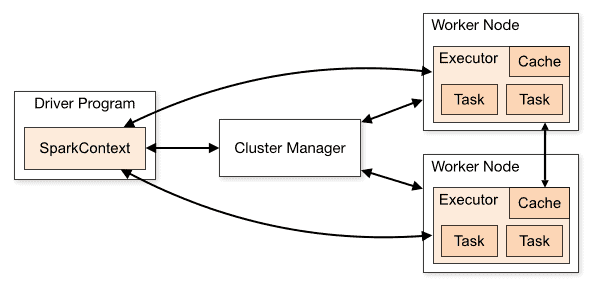
These set of processes are coordinated by the SparkContext object in your main program (called the driver program). SparkContext connects to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN), which allocate resources across applications.
Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application.
Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
3. Core Components
The following diagram gives the clear picture of the different components of Spark:

3.1. Spark Core
Spark Core component is accountable for all the basic I/O functionalities, scheduling and monitoring the jobs on spark clusters, task dispatching, networking with different storage systems, fault recovery, and efficient memory management.
Unlike Hadoop, Spark avoids shared data to be stored in intermediate stores like Amazon S3 or HDFS by using a special data structure known as RDD (Resilient Distributed Datasets).
Resilient Distributed Datasets are immutable, a partitioned collection of records that can be operated on – in parallel and allows – fault-tolerant ‘in-memory’ computations.
RDDs support two kinds of operations:
- Transformation – Spark RDD transformation is a function that produces new RDD from the existing RDDs. The transformer takes RDD as input and produces one or more RDD as output. Transformations are lazy in nature i.e., they get execute when we call an action
- Action – transformations create RDDs from each other, but when we want to work with the actual data set, at that point action is performed. Thus, Actions are Spark RDD operations that give non-RDD values. The values of action are stored to drivers or to the external storage system
An action is one of the ways of sending data from Executor to the driver.
Executors are agents that are responsible for executing a task. While the driver is a JVM process that coordinates workers and execution of the task. Some of the actions of Spark are count and collect.
3.2. Spark SQL
Spark SQL is a Spark module for structured data processing. It’s primarily used to execute SQL queries. DataFrame constitutes the main abstraction for Spark SQL. Distributed collection of data ordered into named columns is known as a DataFrame in Spark.
Spark SQL supports fetching data from different sources like Hive, Avro, Parquet, ORC, JSON, and JDBC. It also scales to thousands of nodes and multi-hour queries using the Spark engine – which provides full mid-query fault tolerance.
3.3. Spark Streaming
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from a number of sources, such as Kafka, Flume, Kinesis, or TCP sockets.
Finally, processed data can be pushed out to file systems, databases, and live dashboards.
3.4. Spark Mlib
MLlib is Spark’s machine learning (ML) library. Its goal is to make practical machine learning scalable and easy. At a high level, it provides tools such as:
- ML Algorithms – common learning algorithms such as classification, regression, clustering, and collaborative filtering
- Featurization – feature extraction, transformation, dimensionality reduction, and selection
- Pipelines – tools for constructing, evaluating, and tuning ML Pipelines
- Persistence – saving and load algorithms, models, and Pipelines
- Utilities – linear algebra, statistics, data handling, etc.
3.5. Spark GraphX
GraphX is a component for graphs and graph-parallel computations. At a high level, GraphX extends the Spark RDD by introducing a new Graph abstraction: a directed multigraph with properties attached to each vertex and edge.
To support graph computation, GraphX exposes a set of fundamental operators (e.g., subgraph, joinVertices, and aggregateMessages).
In addition, GraphX includes a growing collection of graph algorithms and builders to simplify graph analytics tasks.
4. “Hello World” in Spark
Now that we understand the core components, we can move on to simple Maven-based Spark project – for calculating word counts.
We’ll be demonstrating Spark running in the local mode where all the components are running locally on the same machine where it’s the master node, executor nodes or Spark’s standalone cluster manager.
4.1. Maven Setup
Let’s set up a Java Maven project with Spark-related dependencies in pom.xml file:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>4.2. Word Count – Spark Job
Let’s now write Spark job to process a file containing sentences and output distinct words and their counts in the file:
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile(args[0], 1);
JavaRDD<String> words
= lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones
= words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairRDD<String, Integer> counts
= ones.reduceByKey((Integer i1, Integer i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}Notice that we pass the path of the local text file as an argument to a Spark job.
A SparkContext object is the main entry point for Spark and represents the connection to an already running Spark cluster. It uses SparkConf object for describing the application configuration. SparkContext is used to read a text file in memory as a JavaRDD object.
Next, we transform the lines JavaRDD object to words JavaRDD object using the flatmap method to first convert each line to space-separated words and then flatten the output of each line processing.
We again apply transform operation mapToPair which basically maps each occurrence of the word to the tuple of words and count of 1.
Then, we apply the reduceByKey operation to group multiple occurrences of any word with count 1 to a tuple of words and summed up the count.
Lastly, we execute collect RDD action to get the final results.
4.3. Executing – Spark Job
Let’s now build the project using Maven to generate apache-spark-1.0-SNAPSHOT.jar in the target folder.
Next, we need to submit this WordCount job to Spark:
${spark-install-dir}/bin/spark-submit --class com.baeldung.WordCount
--master local ${WordCount-MavenProject}/target/apache-spark-1.0-SNAPSHOT.jar
${WordCount-MavenProject}/src/main/resources/spark_example.txtSpark installation directory and WordCount Maven project directory needs to be updated before running above command.
On submission couple of steps happens behind the scenes:
- From the driver code, SparkContext connects to cluster manager(in our case spark standalone cluster manager running locally)
- Cluster Manager allocates resources across the other applications
- Spark acquires executors on nodes in the cluster. Here, our word count application will get its own executor processes
- Application code (jar files) is sent to executors
- Tasks are sent by the SparkContext to the executors.
Finally, the result of spark job is returned to the driver and we will see the count of words in the file as the output:
Hello 1
from 2
Baledung 2
Keep 1
Learning 1
Spark 1
Bye 15. Conclusion
In this article, we discussed the architecture and different components of Apache Spark. We also demonstrated a working example of a Spark job giving word counts from a file.


















