Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: May 4, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
It was a symbolic day in 1997 when the chess world champion, Garry Kasparov, lost his rematch against IBM’s Deep Blue chess computer. This was an event that caused a paradigm shift in the perception of machine learning systems. This event demonstrated the ability of machines to triumph over humans in complex zero-sum games. Ever since the chess engines only keep getting better.
In this tutorial, we document the evolution of machine learning methods in chess.
The idea of having a machine play chess against a human has been around for a long time and could have started in the late 18th century from an elaborate hoax. Author and inventor Wolfgang von Kempelen unveiled a machine of his making called “The Mechanical Turk” to woo Empress Maria Theresa of Austria.
This machine not only appeared to play an impressive game of chess but also could solve puzzles such as “The Knight’s Tour” (in which the knight moves to each square on the board only once).
However, this machine was found to be a hoax, requiring an operator to stay inside the box.
Even though this actually was not an implemented algorithm, it surely sparked the minds of engineers for years to come.
The invention of the first electronic computers came hand in hand with the first chess-playing algorithms. Notable historical actors from the field of computer science contributed to these first chess algorithms.
One of the bright minds that developed the first algorithm for chess was the British computer scientist and mathematician Alan Turing. Turing is most famous for cracking the intercepted encrypted messages from Nazis during World War II. In the years after the war, Turing designed the first chess engine to run on a computer that did not yet exist.
Later, his former undergraduate colleague David Gawen Champernowne and himself designed the heuristic algorithm Turochamp and tried to run it on a 1951 Ferranti Mark 1 computer, but were unable to do so because of limited computational power. However, they implemented it manually on a chess board.
Simultaneously, a notable first scientific paper on the subject was published by Turing’s former cryptoanalyst colleague Claude Shannon on the subject. Both of these bright computer scientists introduced the basic ideas in chess programming.
There are no surprises here, it is evident that the program has to use some representation of the squares and the pieces to be able to make decisions. There are two main ways to represent a board.
Claude Shannon notes in his paper that there are two common ways of representing a chess board. The first one we will explore is the piece-centric representation
In this method, the computer keeps a list of all the pieces and their occupied squares.
We can represent the starting position in this manner:
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Inversely, there exists a board-centric representation that keeps a list of all the squares and the pieces that are occupying them or not. This was the representation that Claude Shannon preferred in his paper. Although it is not the most efficient encoding of a position, it was more convenient for calculations.
 |
 |
 |
 |
 |
|
|
|
 |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
 |
 |
 |
 |
 |
|
|
|
A board representation and a move generator that can output valid moves that respect chess rules is the first step to writing a program that can play chess.
Because each position can be represented as the result of a previous position and a move, any chess program has an interest in searching through a directed graph to find the best moves.
We can see how the initial position can yield a limited number of moves, and as the tree grows deeper, move after move, so do the number of different positions available:
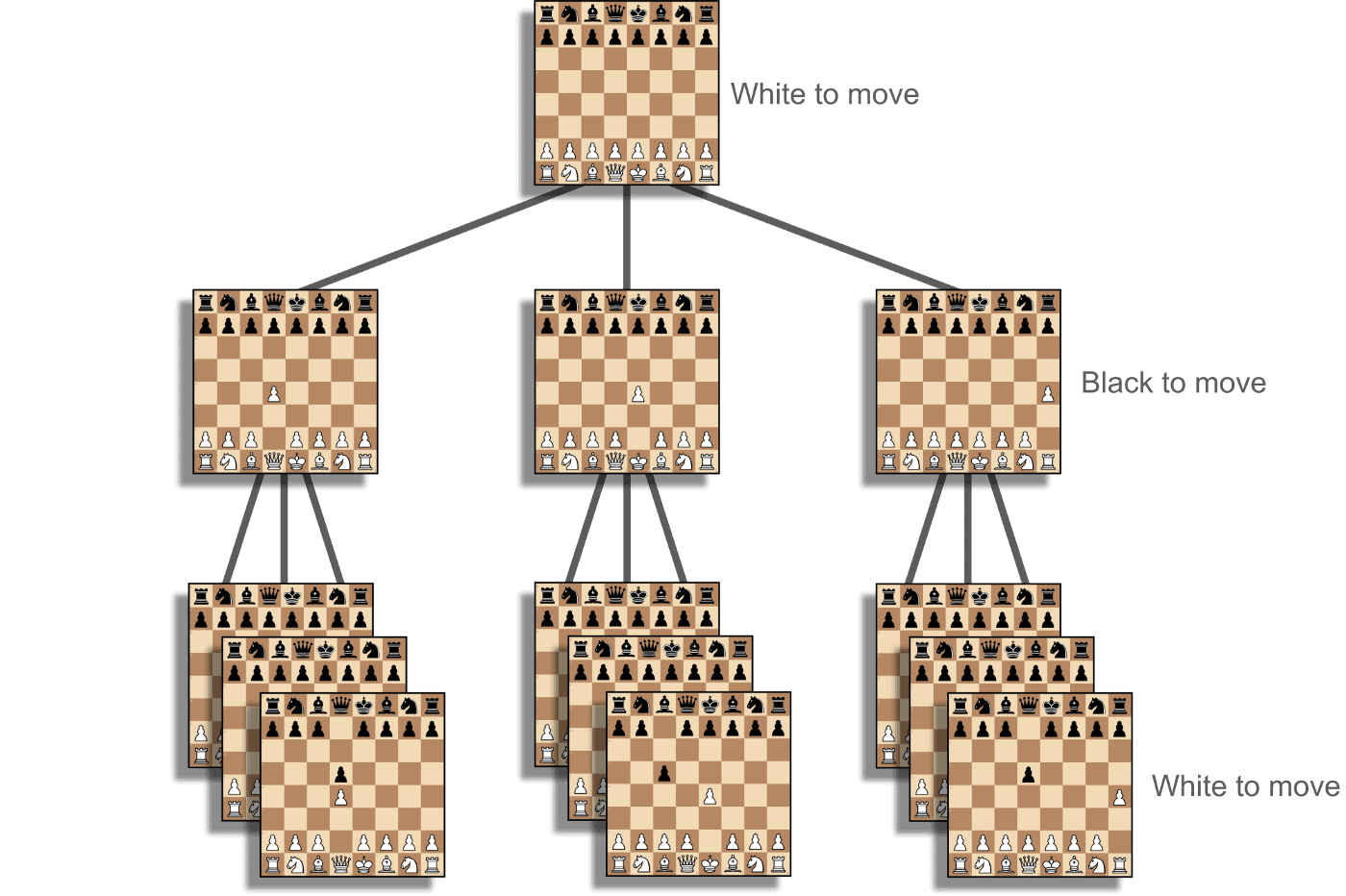
Claude Shannon coarsely categorized searches into two types: brute-force and selective searches. While brute-force searches look at every move on the board with a fixed depth of moves, selective searches prioritize the best candidate moves with more depth and ignore other branches.
Although Shannon prioritized selective searches (probably because of the limited computing power at the time), most programs before DeepMind’s Alpha series in 2017 behaved like brute-force searches, with some selective elements.
Inside the brute-force and selective search types, there are different algorithms that can be implemented based on the desired output. The most basic brute-force algorithm is probably a depth-first search of the directed graph.
Many search types exist for different game types, including but not limited to: Threat Space Search, Expectimax, Beam Search, Hill Climbing Search, Best First Search and others.
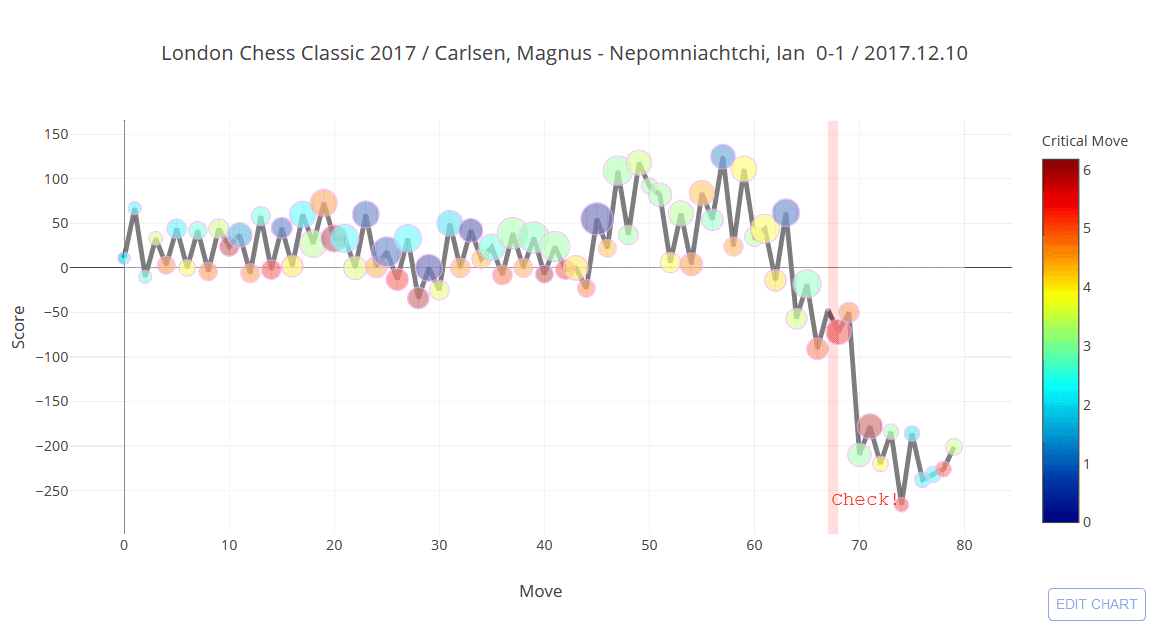
We can visualize evaluations and much more using Python and a simple chess package. Using this, we can have an idea of who is winning at which point in the game. In the graph below, we can see a graph of the score attributed to a position. Positive values mean a position is better for the white pieces, and negative values indicate the position is better for the black pieces.
The score is usually calculated in centipawns. One centipawn is 1/100th of a pawn, which is usually worth one point in chess. Bishops and knights have usually attributed 3 points, rooks are worth 5 points and the queen is worth 10 points conventionally. Of course, these values can vary depending on the position:
Turing’s Turochamp works by taking in the adversarial player’s move as input and calculating all of the possible moves, as well as the player responses, and attributing points based on the moves. This evaluation algorithm is primarily centered around deciding whether to take a piece or not. For example, if a knight is worth 3 points and a queen is worth 10, the algorithm will vote for the move that earns the most points in the short run.
Placing the king in check could be attributed a half a point for example. Turing described his own algorithm as being able to play a low-level game of chess. This could be attributed to having a low-depth analysis of the game.
A recreation of this algorithm was implemented at the 2012 Alan Turing Centenary Conference against former world champion Garry Kasparov. Of course, it didn’t stand a chance.
After Turochamp came to a long list of chess algorithms. The first to play a full game against a human was made in 1957 by IBM’s Alex Bernstein, which ran on an IBM 704 mainframe, taking a now grueling 8 minutes per move. In 1976, leveraging the rise of commercial computing, Peter Jennings created the first commercial chess program for microcomputers, MicroChess. The following year, Fidelity Electronics of Chicago released the first computer dedicated only to chess, the “Chess Challenger”.
By 1986, computer software with full GUIs like “The Chessmaster” was being released, with particularly strong algorithms. The engine used in this program, “The King“, was already estimated to have a chess rating or ELO of 2858 in its most complete implementation. This is the rating of a strong chess expert.
The evaluation function for this particular software was complex and hence a little slow. Positional scores could easily exceed the value of several pawns. Different algorithms are used for three different stages of the game: opening, middle and endgame. A fuzzy definition for the different game phases is attained by weighing the 3 different terms.
In the case of selective search, moves can be extended as a way to try and find better moves faster.
“The King” uses various extensions including check extensions (that is to say extending the depth of the search after a check) and chess-specific static (or strategic) rules for additional extensions (we can think of prioritizing pawn structures and their role as the game progresses).
This heuristic is simply the observation that a good move or a set of moves in a particular position may be equally strong in similar positions at the same move (ply) in the game tree.
“The King” successfully implements the best moves from earlier iterations, heuristics from the history of games presented to the algorithm, killer heuristic, priority to captures and a refutation table to order moves. Finally, for the end game, specialized knowledge is included.
IBM’s T. J. Watson Research Center specialists Feng-Hsiung Hsu, Murray S. Campbell, and A. Joseph Hoane, Jr. built the system that would dramatically change the perception of computer systems’ role in zero-sum games by defeating world chess champion Garry Kasparov in their 1997 rematch.
The IBM team published an overview of their work in a scientific article. Essentially, this system leverages Alpha-Beta tree pruning to search through thousands of human games.
Alpha-Beta Pruning is a way to decrease the total number of branches that a minimax algorithm has to search by reducing the size of its search tree. This type of algorithm will stop evaluating a move when a move that has been previously evaluated proves to be better. It yields the same results as a minimax algorithm, but faster.
Deep Blue combines 14 parallel Alpha-Beta search engines to find the best moves. Each engine had its own dedicated chips and searched 400,000 positions per second for a total of 3 to 5 million positions searched per second. Even with these stats, it only barely managed to win its rematch against Garry Kasparov with an ELO rating of ~2800.
DeepMind Technologies was founded in 2010 and acquired by Google in 2014. This British artificial intelligence laboratory would go on to change the world. Focusing on Reinforcement Learning research, by 2017 they had built a neural network capable of defeating world champions in go, a game radically more complex than chess.
Their algorithm, Alpha Go was the object of an award-winning documentary. This Alpha Go algorithm was trained using human data. However, the successive algorithm, AlphaGo Zero, defeat its predecessor with a score of 100 – 0 games, no human data and less computation.
Finally, AlphaZero generalizes these different game algorithms into one network, playing chess, go and shogi with impressive mastery. These types of results are the product of Reinforcement Learning, a field in Machine Learning that uses penalties in the environment to learn and emphasizes self-play.
Residual Networks are the backbone of many popular neural networks. These structures allow us to encode and decode information present in data. The advantage of these structures is that they allow the gradient signal from the loss function to travel further into the network, facilitating the training of deeper neural networks.
Using these types of networks to dictate the system’s next move provides rich feature maps that detail the information present in each position. Policy networks dictate the most likely moves while value networks dictate the depth of the search through the tree. These two networks work in unison to limit the search space.
Reinforcement learning (RL) is one of three main machine learning paradigms. The other two are supervised learning (with labels) and unsupervised learning (without labels). RL focuses on maximizing the rewards from a specific environment as opposed to learning from an explicit loss function.
We can see how an agent performs an action and receives a reward (score) from the environment that places the agent in a new state:
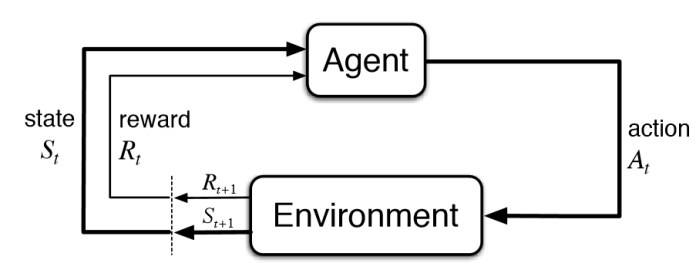
RL leverages adversarial approaches that place the network with a similar-level opponent as it learns the game. Pitting the network against itself is an idea referred to as “self-play”.
The random sampling “Monte Carlo” approach for solving difficult problems has been around since the 1950s. This random sampling was combined with the minimax search algorithm to create the Monte Carlo Tree Search, a method of searching through infinitely broad and deep trees for potential moves.
This is used by computer scientists in many board games that can be characterized by a complexity emerging from the multitude of possible moves that a player can choose from. There exist multiple surveys covering the use of different variants of this search method. Additionally, there exist other search algorithms that game-playing systems may use.
In this article, we saw the different functioning components that make an AI engine understand and play chess and other board games.