

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
With the advancement of technology in AI and machine learning, we require tools to recognize text within images.
In this tutorial, we’ll explore Tesseract, an optical character recognition (OCR) engine, with a few examples of image-to-text processing.
2. Tesseract
Tesseract is an open-source OCR engine developed by HP that recognizes more than 100 languages, along with the support of ideographic and right-to-left languages. Also, we can train Tesseract to recognize other languages.
It contains two OCR engines for image processing – a LSTM (Long Short Term Memory) OCR engine and a legacy OCR engine that works by recognizing character patterns.
The OCR engine uses the Leptonica library to open the images and supports various output formats like plain text, hOCR (HTML for OCR), PDF, and TSV.
3. Setup
Tesseract is available for download/install on all major operating systems.
For example, if we’re using macOS, we can install the OCR engine using Homebrew:
brew install tesseract
We’ll observe that the package contains a set of language data files, like English, and orientation and script detection (OSD), by default:
==> Installing tesseract
==> Downloading https://homebrew.bintray.com/bottles/tesseract-4.1.1.high_sierra.bottle.tar.gz
==> Pouring tesseract-4.1.1.high_sierra.bottle.tar.gz
==> Caveats
This formula contains only the "eng", "osd", and "snum" language data files.
If you need any other supported languages, run `brew install tesseract-lang`.
==> Summary
/usr/local/Cellar/tesseract/4.1.1: 65 files, 29.9MBHowever, we can install the tesseract-lang module for support of other languages:
brew install tesseract-langFor Linux, we can install Tesseract using the yum command:
yum install tesseractLikewise, let’s add language support:
yum install tesseract-langpack-eng
yum install tesseract-langpack-spaHere, we’ve added the language-trained data for English and Spanish.
For Windows, we can get the installers from Tesseract at UB Mannheim.
4. Tesseract Command-Line
4.1. Run
We can use the Tesseract command-line tool to extract text from images.
For instance, let’s take a snapshot of our website:
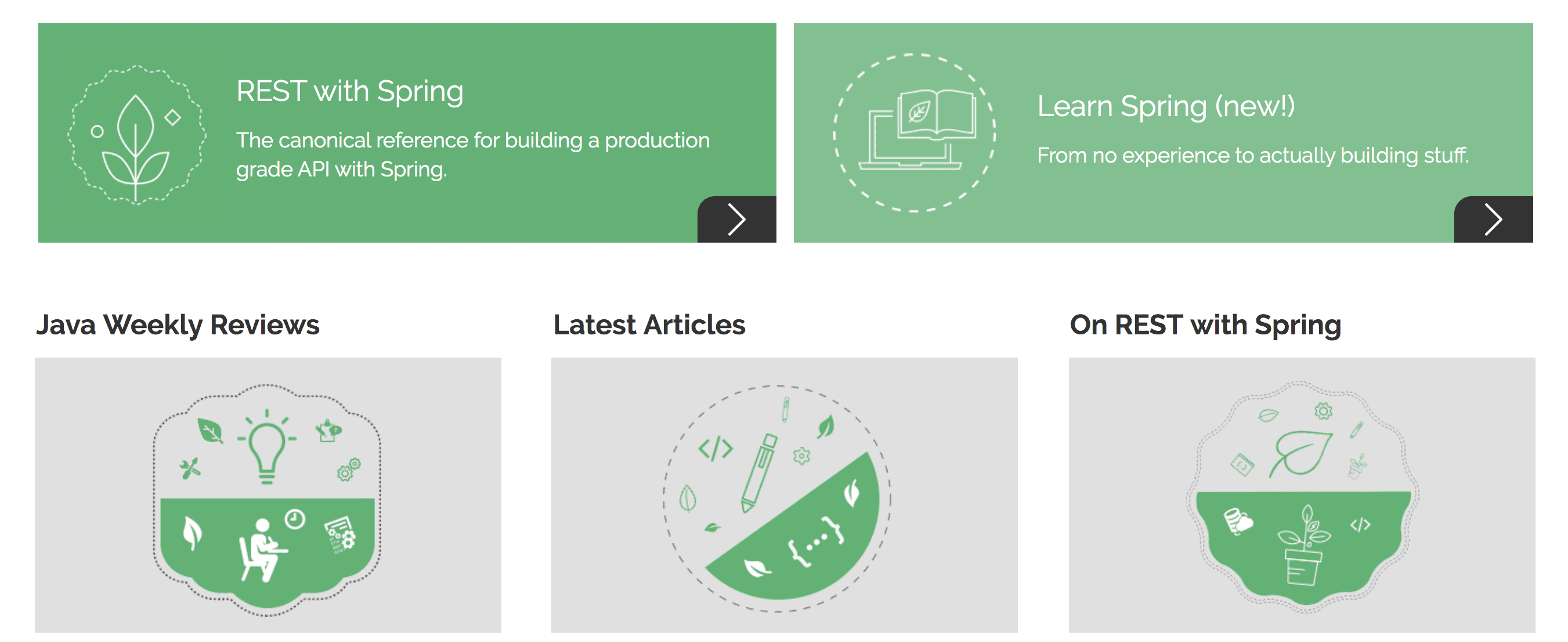
Then, we’ll run the tesseract command to read the baeldung.png snapshot and write the text in the output.txt file:
tesseract baeldung.png outputThe output.txt file will look like:
a REST with Spring Learn Spring (new!)
The canonical reference for building a production
grade API with Spring.
From no experience to actually building stuff.
y
Java Weekly ReviewsWe can observe that Tesseract hasn’t processed the entire content of the image. Because the accuracy of the output depends on various parameters like the image quality, language, page segmentation, trained data, and engine used for image processing.
4.2. Language Support
By default, the OCR engine uses English when processing the images. However, we can declare the language by using the -l argument:
Let’s take a look at another example with multi-language text:

First, let’s process the image with the default English language:
tesseract multiLanguageText.png output
The output will look like:
Der ,.schnelle” braune Fuchs springt
iiber den faulen Hund. Le renard brun
«rapide» saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra il cane pigro. El zorro
marron rapido salta sobre el perro
perezoso. A raposa marrom rapida
salta sobre 0 cao preguicoso.Then, let’s process the image with the Portuguese language:
tesseract multiLanguageText.png output -l porSo, the OCR engine will also detect Portuguese letters:
Der ,.schnelle” braune Fuchs springt
iber den faulen Hund. Le renard brun
«rapide» saute par-dessus le chien
paresseux. La volpe marrone rapida
salta sopra il cane pigro. El zorro
marrón rápido salta sobre el perro
perezoso. A raposa marrom rápida
salta sobre o cão preguiçoso.Similarly, we can declare a combination of languages:
tesseract multiLanguageText.png output -l spa+porHere, the OCR engine will primarily use Spanish and then Portuguese for image processing. However, the output can differ based on the order of languages we specify.
4.3. Page Segmentation Mode
Tesseract supports various page segmentation modes like OSD, automatic page segmentation, and sparse text.
We can declare the page segmentation mode by using the –psm argument with a value of 0 to 13 for various modes:
tesseract multiLanguageText.png output --psm 1Here, by defining a value of 1, we’ve declared the Automatic page segmentation with OSD for image processing.
Let’s take a look of all the page segmentation modes supported:

4.4. OCR Engine Mode
Similarly, we can use various engine modes like legacy and LSTM engine while processing the images.
For this, we can use the –oem argument with a value of 0 to 3:
tesseract multiLanguageText.png output --oem 1The OCR engine modes are:

4.5. Tessdata
Tesseract contains two sets of trained data for the LSTM OCR engine – best trained LSTM models and fast integer versions of trained LSTM models.
The former provides better accuracy, and the latter offers better speed in image processing.
Also, Tesseract provides a combined trained data with support for both legacy and LSTM OCR engine.
If we use the Legacy OCR engine without providing the supporting trained data, Tesseract will throw an error:
Error: Tesseract (legacy) engine requested, but components are not present in /usr/local/share/tessdata/eng.traineddata!!
Failed loading language 'eng'
Tesseract couldn't load any languages!So, we should download the required .traineddata files and either keep them in the default tessdata location or declare the location using the –tessdata-dir argument:
tesseract multiLanguageText.png output --tessdata-dir /image-processing/tessdata4.6. Output
We can declare an argument to get the required output format.
For instance, to get searchable PDF output:
tesseract multiLanguageText.png output pdfThis will create the output.pdf file with the searchable text layer (with recognized text) on the image provided.
Similarly, for hOCR output:
tesseract multiLanguageText.png output hocrAlso, we can use tesseract –help and tesseract –help-extra commands for more information on the tesseract command-line usage.
5. Tess4J
Tess4J is a Java wrapper for the Tesseract APIs that provides OCR support for various image formats like JPEG, GIF, PNG, and BMP.
First, let’s add the latest tess4j Maven dependency to our pom.xml:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.1</version>
</dependency>Then, we can use the Tesseract class provided by tess4j to process the image:
File image = new File("src/main/resources/images/multiLanguageText.png");
Tesseract tesseract = new Tesseract();
tesseract.setDatapath("src/main/resources/tessdata");
tesseract.setLanguage("eng");
tesseract.setPageSegMode(1);
tesseract.setOcrEngineMode(1);
String result = tesseract.doOCR(image);Here, we’ve set the value of the datapath to the directory location that contains osd.traineddata and eng.traineddata files.
Finally, we can verify the String output of the image processed:
Assert.assertTrue(result.contains("Der ,.schnelle” braune Fuchs springt"));
Assert.assertTrue(result.contains("salta sopra il cane pigro. El zorro"));Additionally, we can use the setHocr method to get the HTML output:
tesseract.setHocr(true);By default, the library processes the entire image. However, we can process a particular section of the image by using the java.awt.Rectangle object while calling the doOCR method:
result = tesseract.doOCR(imageFile, new Rectangle(1200, 200));Similar to Tess4J, we can use Tesseract Platform to integrate Tesseract in Java applications. This is a JNI wrapper of the Tesseract APIs based on the JavaCPP Presets library.
6. Conclusion
In this article, we’ve explored the Tesseract OCR engine with a few examples of image processing.
First, we examined the tesseract command-line tool to process the images, along with a set of arguments like -l, –psm and –oem.
Then, we’ve explored tess4j, a Java wrapper to integrate Tesseract in Java applications.

















