

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In the field of natural language processing (NLP) and sequence modeling, Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks have long been dominant. However, with the introduction of the Transformer architecture in 2017, a paradigm shift has occurred in the way we approach sequence-based tasks.
This tutorial aims to provide an overview of RNN/LSTM and Transformer models, highlight their differences, and discuss the implications of these advancements.
2. What Is RNN and LSTM?
RNNs are a class of neural networks which are able to handle sequential data by incorporating information from previous inputs. RNNs are neural networks that contain a hidden state, which allows them to retain information from previous time steps. They operate on sequential data by processing one input at a time, updating their hidden state based on the current and previous hidden states.
The figure below shows a basic RNN structure:
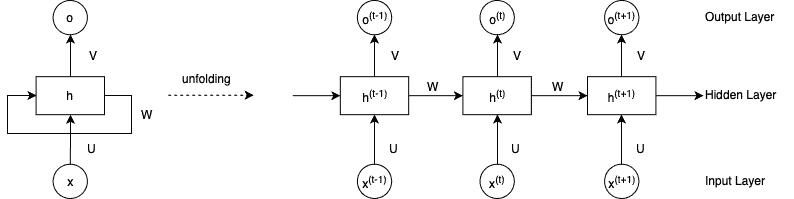 Where x, h, o are the input sequence, hidden state, and the output sequence, respectively. U, V, and W are the training weights.
Where x, h, o are the input sequence, hidden state, and the output sequence, respectively. U, V, and W are the training weights.
RNNs are particularly effective in capturing short-term dependencies in sequences. However, they suffer from the vanishing gradient problem, where the influence of earlier inputs diminishes exponentially as the sequence progresses, making it difficult to capture long-term dependencies.
LSTM is a specific type of RNN architecture that addresses the vanishing gradient problem, which occurs when training deep neural networks. LSTMs leverage memory cells and gates to selectively store and retrieve information over long sequences, making them effective for capturing long-term dependencies.
The figure below illustrates an LSTM cell:

Where ht is the hidden state at the time step t, and c is the cell state.
2.1. Sequence-to-Sequence Model
When applying RNN/LSTM on NLP tasks such as machine translation, and text summarisation, we leverage a structure called a sequence-to-sequence model (also known as an encoder-decoder model). As the name implies, it consists of two main components: an encoder and a decoder.
The encoder processes the input sequence and encodes it into a fixed-length representation, also known as a context vector or latent space representation. Usually, the final hidden state of the network serves as the context vector, which summarises the input information.
Once the model encodes the input sequence, the decoder takes over and generates an output sequence based on the encoded representation. The decoder usually will use a similar structure as the encoder. However, the hidden state of the decoder is initialized with the context vector from the encoder.
The decoder uses this initial hidden state to generate the first token of the output sequence. It then generates subsequent tokens, conditioning its predictions on both the previously generated tokens and the context vector. This process continues until an end-of-sequence token is generated or a maximum sequence length is reached.
The following figure gives an example of how an encoder-decoder model works:
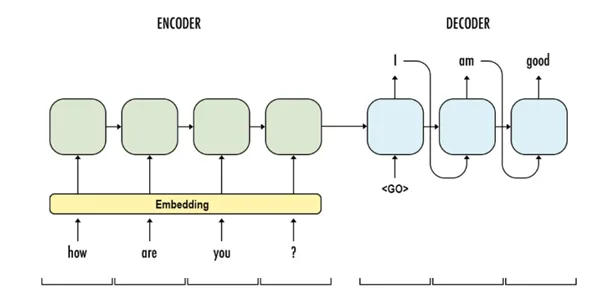{kind=link}
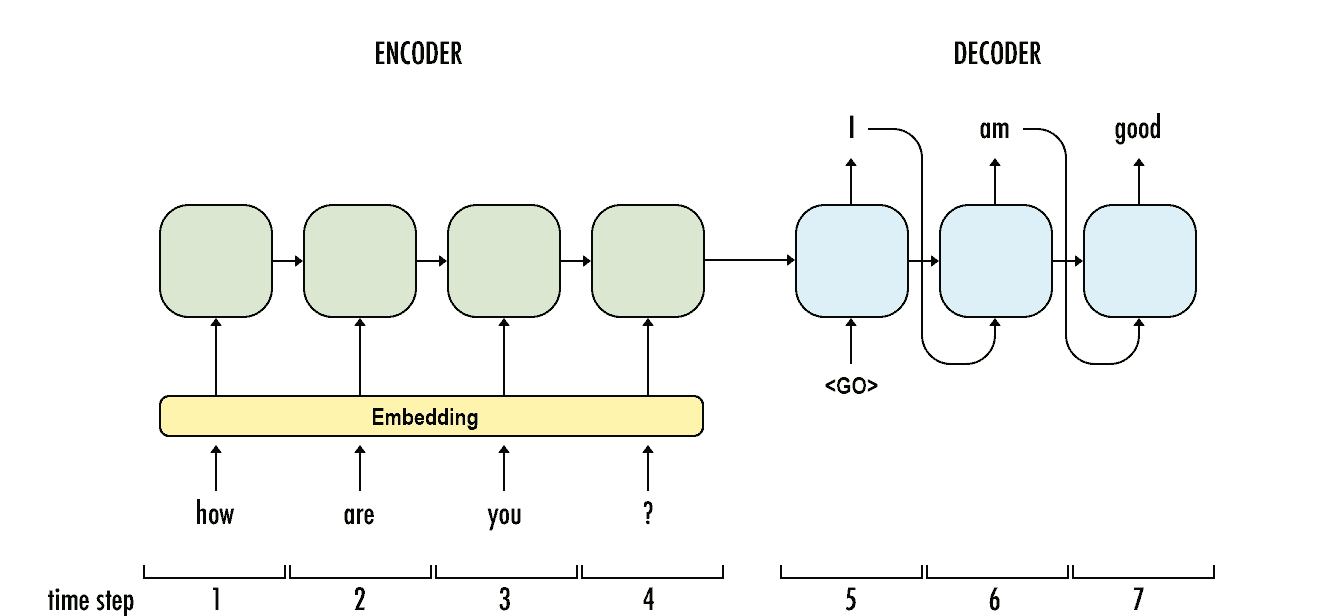
Despite being a useful model for summarising the input sequence, the sequence-to-sequence model has an issue when the input sequence is quite long and contains a lot of information. Not every piece of the input sequence’s context is required at every decoding stage for all text production activities. For instance, a machine translation model does not need to be aware of the other words in the sentence when translating “boy” in the phrase “A boy is eating the banana.”
Therefore, people have started using Transformer, which applies a special attention mechanism. Transformer is a state-of-the-art model that is widely used in NLP and Computer Vision.
3. What Are Transformers?
The Transformer is a neural network architecture proposed in the seminal paper “Attention Is All You Need” by Vaswani et al. Unlike RNNs, Transformers do not rely on recurrence but instead operate on self-attention.
Self-attention allows the model to weigh the importance of different input tokens when making predictions, enabling it to capture long-range dependencies without the need for sequential processing. Transformers consist of encoder and decoder layers, employing multi-head self-attention mechanisms and feed-forward neural networks.
The figure below shows the architecture of a Transformer network:
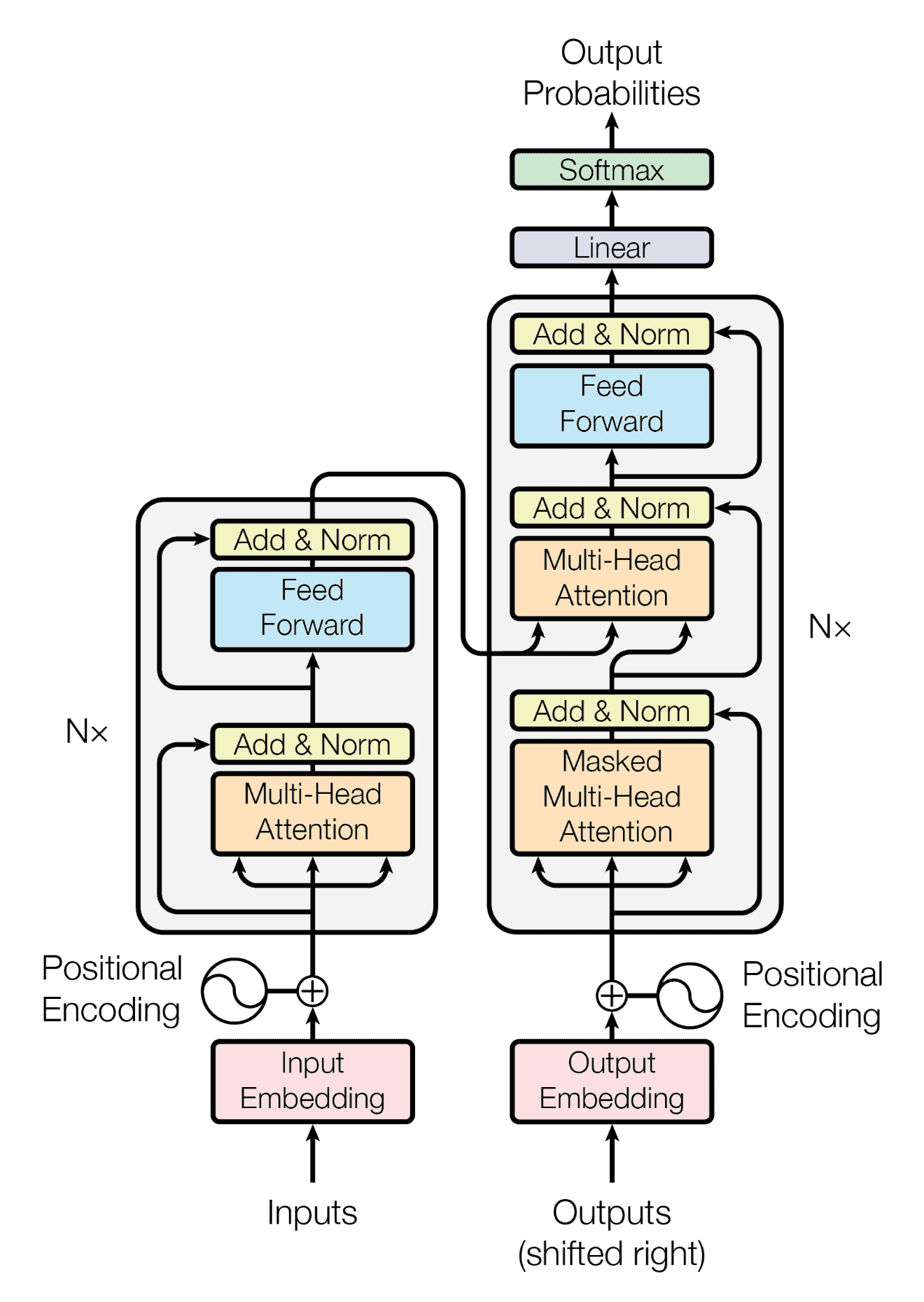
There are many types of Transformers. Two influential models have emerged in the field of NLP: BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer). BERT applies the encoder of the Transformer. Similar to the Transformer, GPT consists of both an encoder and a decoder. These models have pushed the boundaries of language understanding and generation, showcasing the power of large-scale pre-training and transfer learning.
4. Difference Between RNNs and Transformers
4.1. Architecture
RNNs are sequential models that process data one element at a time, maintaining an internal hidden state that is updated at each step. They operate in a recurrent manner, where the output at each step depends on the previous hidden state and the current input.
Transformers are non-sequential models that process data in parallel. They rely on self-attention mechanisms to capture dependencies between different elements in the input sequence. Transformers do not have recurrent connections or hidden states.
4.2. Handling Sequence Length
RNNs can handle variable-length sequences as they process data sequentially. However, long sequences can lead to vanishing or exploding gradients, making it challenging for RNNs to capture long-term dependencies.
Transformers can handle both short and long sequences efficiently due to their parallel processing nature. Self-attention allows them to capture dependencies regardless of the sequence length.
4.3. Dependency Modeling
RNNs are well-suited for modeling sequential dependencies. They can capture contextual information from the past, making them effective for tasks like language modeling, speech recognition, and sentiment analysis.
Transformers excel at modeling dependencies between elements, irrespective of their positions in the sequence. They are particularly powerful for tasks involving long-range dependencies, such as machine translation, document classification, and image captioning.
4.4. Size of the Model
The size of an RNN is primarily determined by the number of recurrent units (e.g., LSTM cells or GRU cells) and the number of parameters within each unit. RNNs have a compact structure as they mainly rely on recurrent connections and relatively small hidden state dimensions. The number of parameters in an RNN is directly proportional to the number of recurrent units and the size of the input and hidden state dimensions.
Transformers tend to have larger model sizes due to their architecture. The main components contributing to the size of a Transformer model are self-attention layers, feed-forward layers, and positional encodings. Transformers have a more parallelizable design, allowing for efficient computation on GPUs or TPUs. However, this parallel processing capability comes at the cost of a larger number of parameters.
4.5. Training and Parallelisation
For RNN, we mostly train it in a sequential approach, as the hidden state relies on previous steps. This makes parallelization more challenging, resulting in slower training times.
On the other hand, we train Transformers in parallel since they process data simultaneously. This parallelization capability speeds up training and enables the use of larger batch sizes, which makes training more efficient.
4.6. Interpretability
RNNs have a clear temporal flow, making interpreting their decisions easier and understanding how information flows through the sequence.
Transformers rely on self-attention mechanisms, which may make it more challenging to interpret their decisions. However, techniques like attention visualization can provide insights into the model’s focus.
4.7. Pre-training and Transfer Learning
Pre-training RNNs is more challenging due to their sequential nature. Transfer learning is typically limited to specific tasks or related domains.
We can pre-trained the Transformer models on large-scale corpora using unsupervised objectives like language modeling or masked language modeling. After pre-training, we can fine-tune the model on various downstream tasks, enabling effective transfer learning.
5. Conclusion
In this article, we explain the basic idea behind RNN/LSTM and Transformer. Moreover, we compare these two types of networks in multiple aspects.
While RNNs and LSTMs were the go-to choices for sequential tasks, Transformers have proven to be a viable alternative due to their parallel processing capability, ability to capture long-range dependencies, and improved hardware utilization. However, RNNs still hold value when dealing with tasks where temporal dependencies play a critical role.
In conclusion, the choice between RNN/LSTM and Transformer models ultimately depends on the specific requirements of the task at hand, striking a balance between efficiency, accuracy, and interpretability.