Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: September 18, 2022

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
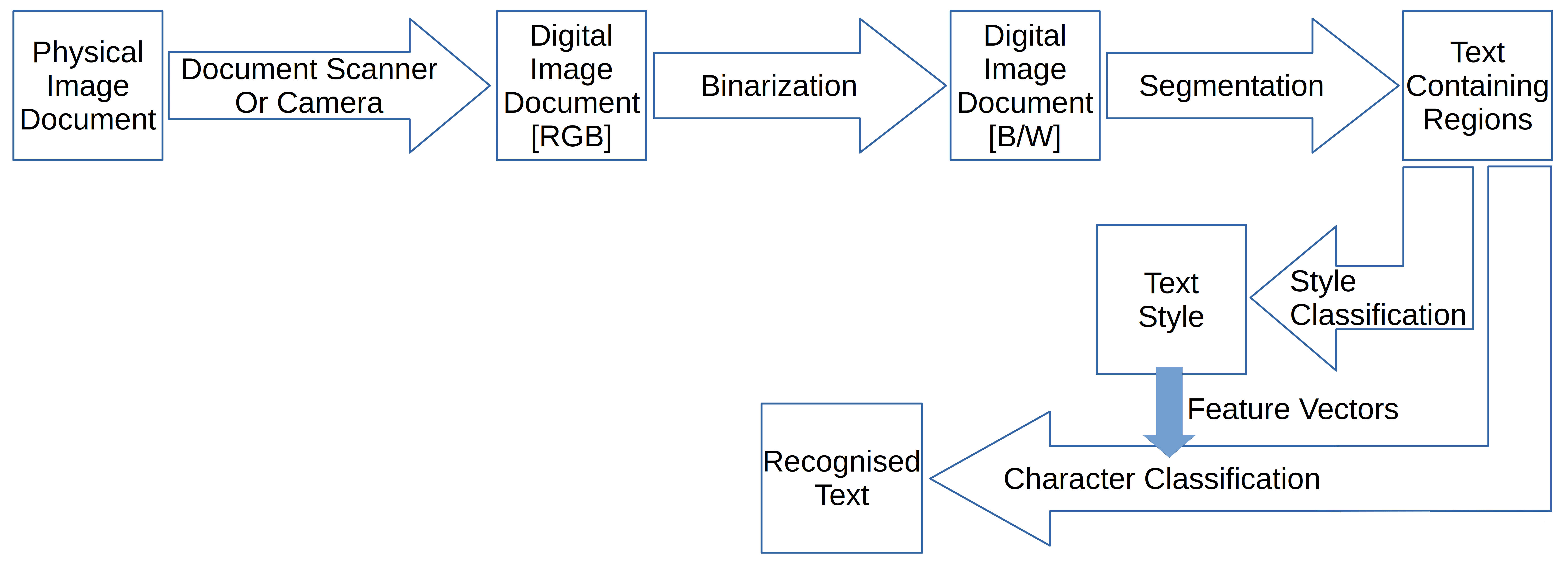
In this tutorial, we’ll learn about optical character recognition (OCR). We’ll first see the usefulness of OCR. We’ll learn its basic workflow, including popular models and training datasets used in its implementation.
Optical Character Recognition (OCR) is the process that converts an image of text into a machine-readable text format.
The fundamental advantage of OCR technology is that it makes text searches, editing, and storage simple, which simplifies data entry. OCR makes it possible for companies, people, and other entities to save files on their PCs, laptops, and other gadgets, guaranteeing ongoing access to all paperwork.
By leveraging automated data extraction and storage capabilities, OCR technology is an effective business procedure that conserves time, money, and other resources.
Text recognition is another name for OCR. An OCR application extracts data from scanned documents, camera photos, and image-only PDFs:

We can access and edit the original material by using OCR software, which isolates letters in the image, turns them into words, and then turns the words into sentences. Furthermore, it does away with the requirement for human data entry.
Data compression can reduce a data file’s size while maintaining the majority, if not all, of the original content. We can compress most file formats, including documents, music, video, and image files.
Bulky image documents can have their most relevant information extracted by being converted to plain or rich text. Recognizing the text alone, rather than its structure or typeface, is crucial when producing text from photos using OCR. Although welcome, this style (font, size and language) information is not the most crucial:

By transforming paper and scanned-image documents into machine-readable, searchable pdf files, OCR facilitates the optimization of big-data modelling. We cannot automate processing and extracting valuable information without first using OCR in documents where text layers are missing.
OCR systems transform physical, printed documents into machine-readable text by combining hardware and software. We copy or read the text using hardware, such as an optical scanner or a dedicated circuit board. The software usually handles advanced processing.
While digitizing old newspapers in the early 1990s, OCR technology gained popularity. Technology has advanced much since then. The technologies of today are capable of providing OCR accuracy that is almost perfect. Using cutting-edge techniques, we can automate these complex document-processing operations.
The OCR engine is the component of the software toolchain that conducts OCR. Transym, Tesseract, ABBYY, Prime, and Azure are examples of the most popular OCR engines.
We use a scanner for OCR to process a document’s physical form. OCR software turns the document into a two-color or black-and-white version after scanning. The OCR engine examines the scanned-in image or bitmap for bright and dark parts, with the light areas being classified as the background and the dark areas as characters.
The next step is to discover alphabetical or numerical digits by processing the dark regions. During this phase, we usually focus on one character, word, or section of text at a time. It is common to use one of two algorithms, pattern recognition or feature recognition, to identify the characters.
Feeding the OCR application with examples of text in different fonts and formats, we utilize pattern recognition to compare and identify characters in the scanned document or image file.
We call the second algorithm feature detection, where the OCR uses rules pertaining to the characteristics of a particular letter or number to recognize characters in the scanned document. These characteristics include things like how many curved, crossing, or angled lines there are.
The structure of a picture or a document is likewise examined by an OCR program. It separates the page into sections that include text blocks, tables, and graphics. Words are first separated from lines to form words and then characters. After identifying the characters, the algorithm compares them to a collection of pattern images. We’re shown the recognized text by the software once it has gone through all potential matches:
The key idea here is to remove non-text artefacts from the image document.
Often, the documents are kept in computer memory as a grey level, which has a maximum of 256 distinct grey values ranging from 0 to 255. The greyscale palette’s grey values each produce a different color. If the document picture must provide any information, we must repeat the process many times for different colors. A binary picture is more helpful because it can reduce the amount of time needed to extract the section of the image:

We can convert any multi-tone grayscale image into a black-and-white image using the binarization technique (two-tone image). To begin the binarization process, determine the grayscale threshold value and whether or not a pixel has a specific grey value. If a pixel’s grey value is more than the threshold, the pixel turns white. Similarly, pixels become black if their grey value is lower than the threshold:
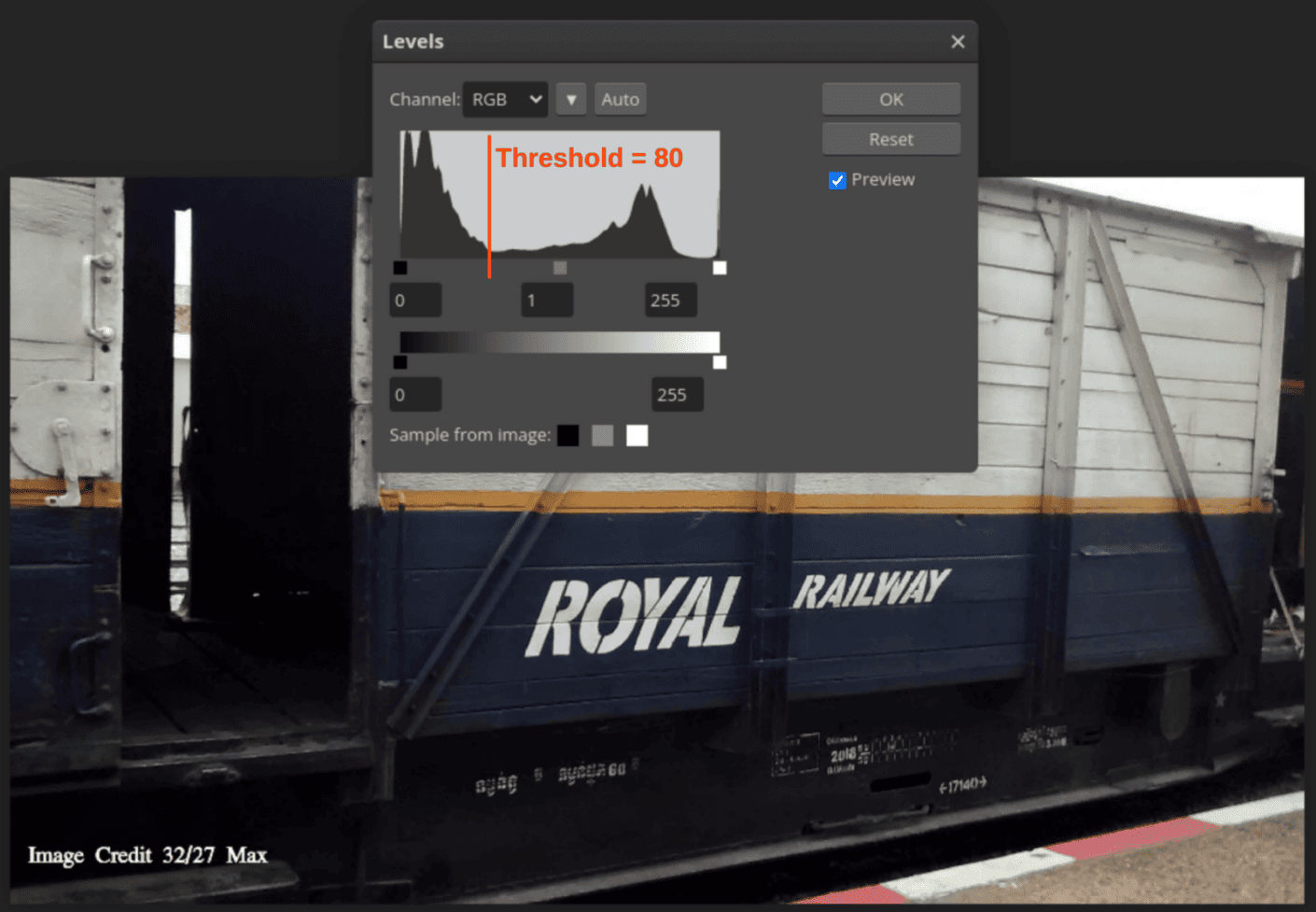
Broadly two different binarization techniques exist. We can create a crude binarized image using a single global threshold. Using a moving window (sub-image) with adjustable thresholds for each window is a more advanced technique.
The aim here is to identify the font in which the text is written. Font identification includes identifying if the text is written by hand, and in some cases, written by a specific person.
Identifying the language of the text is part of its style classification. This is important since languages belonging to different regions of the world (Asia, for example) have special characters or writing styles that are unique only to that language.
The writing direction of a language or the way we join characters to form words may differ from one language to another. We write Arabic from right to left, and in several Indian languages, we link a line with several characters to form a word:
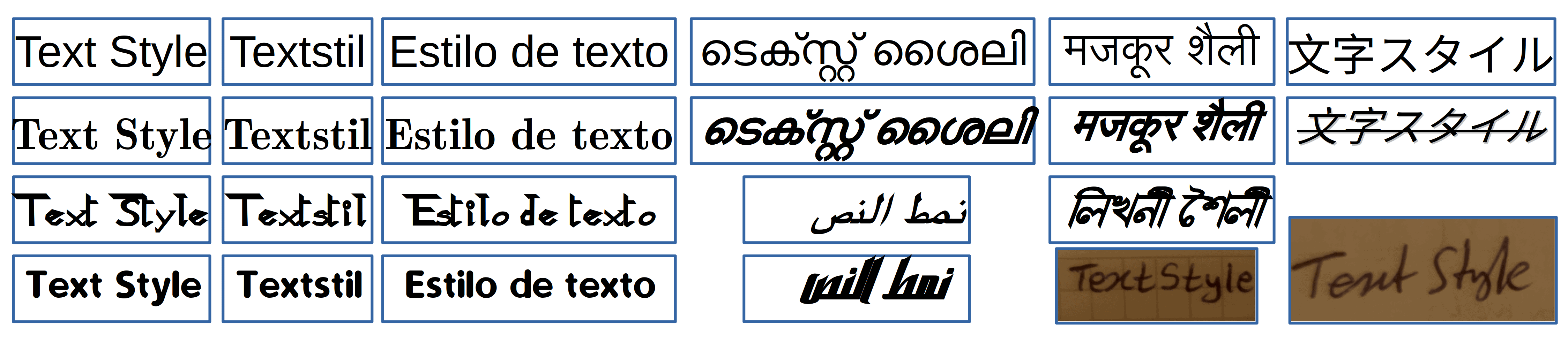
Identification of writing styles is essential in the choice of the character recognition algorithm that is best suited for a piece of text.
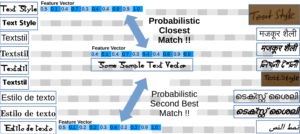
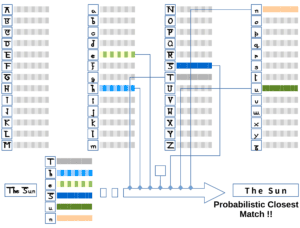
One way to achieve style identification is to extract a few random sections of the text as test samples. We then convert these test samples into feature vectors that uniquely identify the style features of the sample text.
We can now match these feature vectors against an existing database of feature vectors that identify a particular language, font, or handwriting. This way, we can identify the style of the full text as the probabilistic closest match to the feature vector of the test samples:
In this last segment of the OCR engine, we identify the individual characters. Based on the style determined in the preceding stage, individual characters are split out of the image document (style classification).
We then separate the characters into segments and use their geometric properties to identify them (feature detection) or use a recognition model trained on a prior database (pattern recognition):
We can further refine OCR’s output by using a dictionary to convert nonsensical words to their closest correct versions. This is similar to the spelling auto-correct feature on several devices these days.
The physical placement of the text in the image also provides information on what sub-group of characters to expect there. An example of this is that a sequence of numbers is expected in the section for telephone numbers while a name is mostly a string of non-numeric characters.
Contextual information serves as another refinement since a sentence in a particular language follows set rules. This is similar to grammar checks performed in the state-of-the-art word processing software.
Deep learning and other advanced character recognition models work on several other environmental factors in refining the identified text to the final output of the OCR engine.
The OCR engine uses one or more classification models for style and character classification as discussed above. There are classical methods using simplistic models that might be ideal for some specific use cases. Several modern methods, however, deploy advanced computing and data science-driven models for style and character recognition.
Text recognition tests involving continuous speech, handwriting, and cursive script have all been completed effectively using hidden Markov models (HMMs). HMMs have the advantage of recognizing connected characters without breaking them up into smaller components in cursive or handwritten text recognition.
HMMs are statistical models where we view the system under study as a Markov process with hidden or unobserved states. OCR engines benefit from using some other Natural Language Processing (NLP) models.
Support Vector Machines (SVMs) are a class of supervised learning techniques that are widely used in OCR engines for both regression and classification. SVMs are a good tool for handling image data difficulties. They are highly accurate in recognizing visual patterns and are capable of learning complicated patterns without being unduly sensitive to noise.
The performance of standard OCR systems is subpar when dealing with low-resolution photos. In these situations, we can apply data boosting algorithms that improve the image data using super-resolution techniques.
These days, especially in big data-driven corporations, we prefer the deep learning-based OCR model over other models. For structured text like library books scanned by Google, we can expect the text to follow the book’s typeset. Deep learning in this application helps mitigate the poor quality of scanned old books and newspapers. An example of deep learning for unstructured text scanning would be how Google Earth is using OCR to identify street addresses, or how paper documents can be digitized and data-mined.
Although there are many datasets available in English, finding datasets in other languages might be challenging.
Different datasets bring various challenges that must be overcome. The Street View House Numbers dataset (SVHN) includes 26032 test digits, 531131 extra training digits, and 73257 training digits. 3000 photos in various settings and lighting situations with text in Korean and English make up the Scene Text collection.
About 25 different native writers have compiled the Devanagri character collection. Used in various Indian languages, we have 1800 samples from 36-character classes in the Devanagari script.
In this article, we learned about optical character recognition (OCR), which has a wide field of application in today’s electronic age.
We learned that the basic workflow of an OCR engine is to prepare the image for style and character recognition, followed by refinements based on style, context, and application. We also touched upon popular models used by OCR engines together with the training datasets used by those models.