

1. Introduction
In this article, we’ll build an IoT application powered by Fauna and Spring.
NOTE: This article is using a deprecated version of the Fauna Query Language. Refer to Fauna’s Documentation for the latest version of the query language.
2. IoT Applications – Fast Edges and Distributed Databases
IoT applications work close to the users. They are responsible for consuming and processing large volumes of real-time data with low latency. They need fast Edge Computing servers and distributed databases to achieve low latency and maximum performance.
Also, IoT applications process unstructured data, mainly because of the varied source from which they consume them. IoT applications need databases that can process these unstructured data efficiently.
In this article, we’ll build the backend of an IoT application responsible for processing and storing the health vitals of individuals, such as temperature, heart rate, blood oxygen level, etc. This IoT application can consume health vitals from cameras, infra-red scanners, or sensors via wearables such as smartwatches.
3. Using Fauna for IoT Applications
In the previous section, we learned the features of a typical IoT application, and we also understand the expectation one has from a database to be used for the IoT space.
Fauna, due to its below features, can be best suited to be used as a database in an IoT application:
Distributed: When we create an application in Fauna, it automatically distributes across multiple cloud regions. It is hugely beneficial for Edge Computing applications using technologies like Cloudflare Workers or Fastly Compute @ Edge. For our use case, this feature can help us quickly access, process, and store the health vitals of individuals distributed across the globe with minimum latency.
Document-relational: Fauna combines the flexibility and familiarity of JSON documents with the relationships and querying power of a traditional relational database. This capability helps in processing unstructured IoT data at scale.
Serverless: With Fauna – we can purely focus on building our application, not the administrative and infrastructure overhead associated with databases.
4. High-Level Request Flow of the Application
On a high level, this is what the request flow of our application will look like:
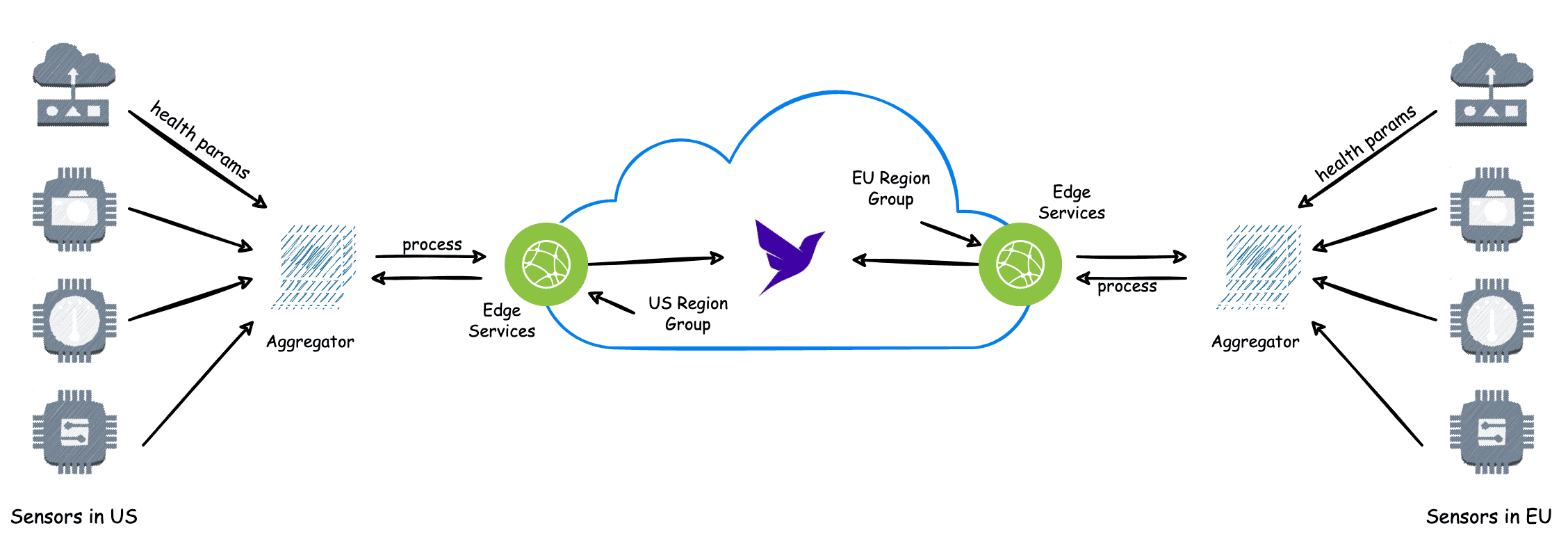
Here Aggregator is a simple application that aggregates the data received from various sensors. In this article, we will not focus on building the Aggregator, but we can solve its purpose by a simple Lambda function deployed on the cloud.
Next, we will build the Edge Service using Spring Boot and set up the Fauna database with different region groups to handle requests from different regions.
5. Creating Edge Service – Using Spring Boot
Let’s create the Edge Service using Spring Boot that will consume the data from the health sensors and push it to the appropriate Fauna region.
In our previous tutorials on Fauna, Introduction to FaunaDB with Spring and Building a web app Using Fauna and Spring for Your First web Agency Client, we explored how to create a Spring Boot application that connects with Fauna. Feel free to dive into these articles for more details.
5.1. Domain
Let’s first understand the domain for our Edge Service.
As mentioned previously, our Edge Service will consume and process health vitals, let’s create a record having basic health vitals of an individual:
public record HealthData(
String userId,
float temperature,
float pulseRate,
int bpSystolic,
int bpDiastolic,
double latitude,
double longitude,
ZonedDateTime timestamp) {
}5.2. Health Service
Out health service will be responsible for processing the health data, identifying the region from the request, and routing it to the appropriate Fauna region:
public interface HealthService {
void process(HealthData healthData);
}Let’s start building the implementation:
public class DefaultHealthService implements HealthService {
@Override
public void process(HealthData healthData) {
// ...
}
}Next, let’s add the code for identifying the request region, i.e. from where the request is triggered.
There are several libraries in Java to identify geolocation. But, for this article, we will add a simple implementation that returns the region “US” for all the requests.
Let’s add the interface:
public interface GeoLocationService {
String getRegion(double latitude, double longitude);
}And the implementation that returns the “US” region for all requests:
public class DefaultGeoLocationService implements GeoLocationService {
@Override
public String getRegion(double latitude, double longitude) {
return "US";
}
}Next, let’s use this GeoLocationService in our HealthService; let’s inject it:
@Autowired
private GeoLocationService geoLocationService;And use it in the process method to extract the region:
public void process(HealthData healthData) {
String region = geoLocationService.getRegion(
healthData.latitude(),
healthData.longitude());
// ...
}Once we have the region, we have to query the appropriate Fauna region group to store the data, but before we get to it, let’s set up the Fauna databases with Region Groups. We will resume our integration after that.
6. Fauna with Region Groups – Setup
Let’s start with creating new databases in the Fauna. We need to create an account if we don’t already have one.
6.1. Creating Databases
Once we’ve logged in, let’s create a new database:
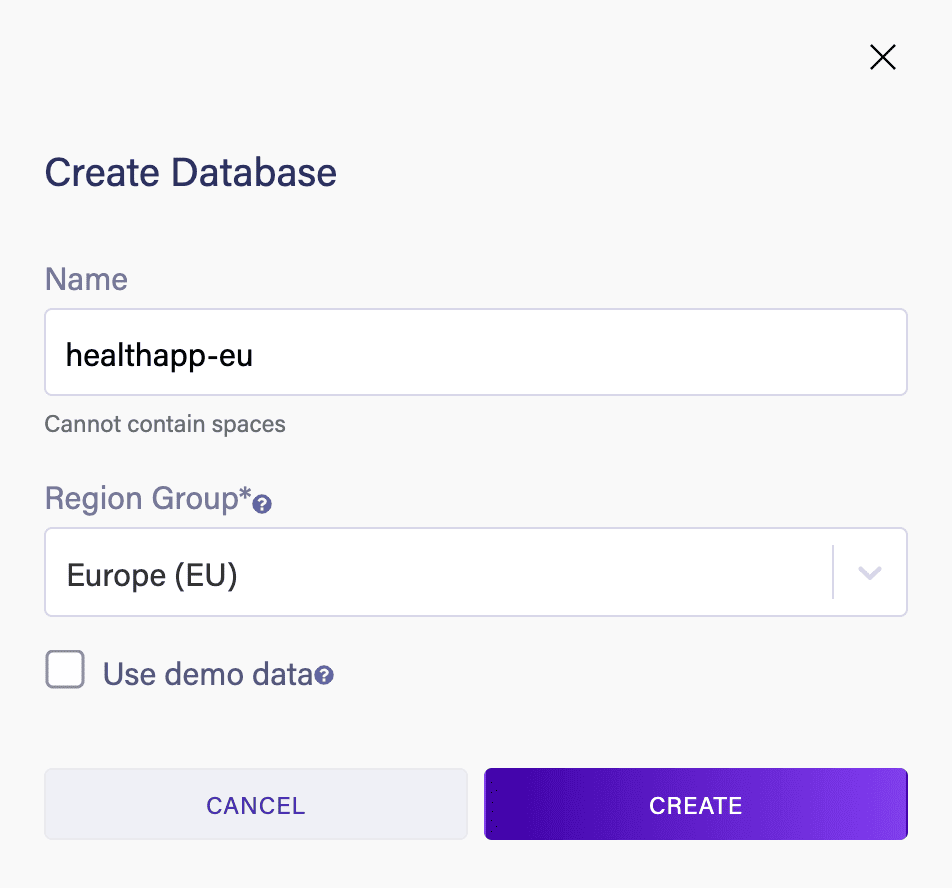
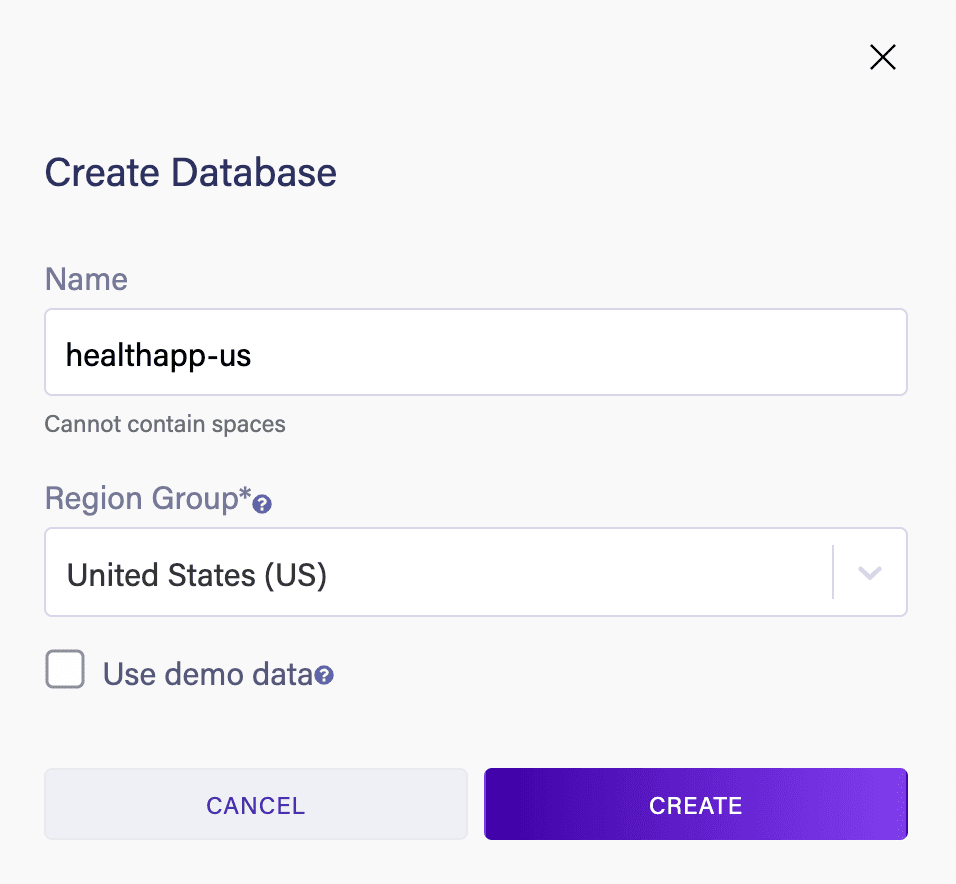
Here, we’re creating this database in the Europe (EU) region; let’s create the same database in the US region to handle our requests from the United States:
Next, we need a security key to access our database from outside, in our case, from the edge service we have created. We’ll create the keys separately for both databases:
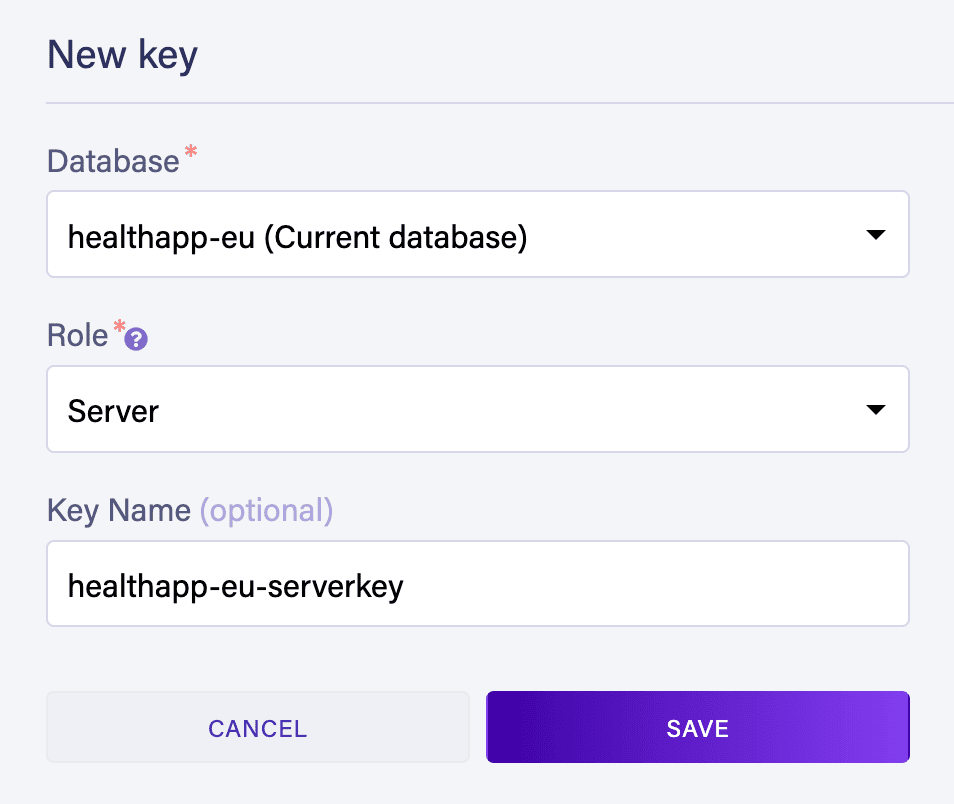
Similarly, we’ll create the key for accessing the healthapp-us database. For more detailed instructions on creating databases and security keys in Fauna, head to our Introduction to FaunaDB with Spring article.
Once keys are created, let’s store the region-specific Fauna connection URLs and security keys in the application.properties of our Spring Boot service:
fauna-connections.EU=https://db.eu.fauna.com/
fauna-secrets.EU=eu-secret
fauna-connections.US=https://db.us.fauna.com/
fauna-secrets.US=us-secretWe’ll need these properties when we use them to configure the Fauna client to connect with Fauna databases.
6.2. Creating a HealthData Collection
Next, let’s create the HealthData collection in Fauna to store the health vitals of an individual.
Let’s add the collection by navigating to the Collections tab in our database dashboard and clicking on the “New Collection” button:
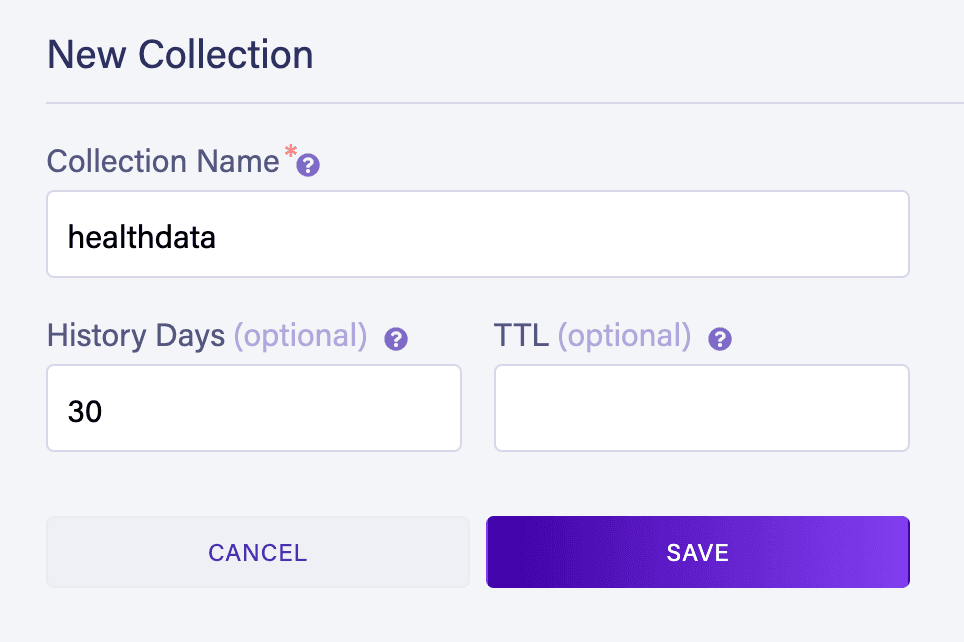
Next, let’s click on the “New Document” button on the next screen to insert one sample document and add the below JSON in the JavaScript console:
{
"userId": "baeldung-user",
"temperature": "37.2",
"pulseRate": "90",
"bpSystolic": "120",
"bpDiastolic": "80",
"latitude": "40.758896",
"longitude": "-73.985130",
"timestamp": Now()
}The Now() function will insert the current timestamp in the timestamp field.
As we hit save, the above data is inserted, and we can view all inserted documents in the Collection tab within our healthdata collection:

Now that we have the databases, secret keys, and collections created, let’s go forward and integrate our Edge Service with our Fauna databases and perform operations on them.
7. Integrating Edge Service with Fauna
To integrate our Spring Boot application with Fauna, we need to add the Fauna driver for Java to our project. Let’s add the dependency:
<dependency>
<groupId>com.faunadb</groupId>
<artifactId>faunadb-java</artifactId>
<version>4.2.0</version>
<scope>compile</scope>
</dependency>We can always find the latest version for faunadb-java here.
7.1. Creating Region-Specific Fauna Clients
This driver provides us FaunaClient that we can configure easily with a given connection endpoint and secret:
FaunaClient client = FaunaClient.builder()
.withEndpoint("connection-url")
.withSecret("secret")
.build();In our application, depending on where the request comes from, we need to connect with Fauna’s EU and US regions. We can solve this by either pre-configuring different FaunaClient instances for both regions separately or dynamically configuring the client on runtime. Let’s work on the second approach.
Let’s create a new class, FaunaClients, that accepts a region and returns the correctly configured FaunaClient:
public class FaunaClients {
public FaunaClient getFaunaClient(String region) {
// ...
}
}We have already stored the Fauna’s region-specific endpoints and secrets in the application.properties; we can inject the endpoints and secrets as a map:
@ConfigurationProperties
public class FaunaClients {
private final Map<String, String> faunaConnections = new HashMap<>();
private final Map<String, String> faunaSecrets = new HashMap<>();
public Map<String, String> getFaunaConnections() {
return faunaConnections;
}
public Map<String, String> getFaunaSecrets() {
return faunaSecrets;
}
}Here, we have used @ConfigurationProperties, which injects the configuration properties in our class. To enable this annotation, we will also need to add:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>Finally, we need to pull the correct connection endpoint and secret from the respective maps and use them accordingly to create FaunaClient:
public FaunaClient getFaunaClient(String region) {
String faunaUrl = faunaConnections.get(region);
String faunaSecret = faunaSecrets.get(region);
log.info("Creating Fauna Client for Region: {} with URL: {}", region, faunaUrl);
return FaunaClient.builder()
.withEndpoint(faunaUrl)
.withSecret(faunaSecret)
.build();
}We have also added a log to check that the correct Fauna URL was picked while creating the client.
7.2. Using Region-Specific Fauna Clients in Health Service
Once our clients are ready, let’s use them in our Health Service to send health data to Fauna.
Let’s inject the FaunaClients:
public class DefaultHealthService implements HealthService {
@Autowired
private FaunaClients faunaClients;
// ...
}Next, let’s get the region-specific FaunaClient by passing in the region extracted previously from the GeoLocationService:
public void process(HealthData healthData) {
String region = geoLocationService.getRegion(
healthData.latitude(),
healthData.longitude());
FaunaClient faunaClient = faunaClients.getFaunaClient(region);
}Once we have the region-specific FaunaClient, let’s use it to insert the Health data into the specific database.
We’ll base this on our existing Faunadb Spring Web App article, where we have written several CRUD queries in FQL (Fauna Query Language) to integrate with Fauna.
Let’s add the query to create the Health data in Fauna; we will start with the keyword Create and mention the collection name for which we are inserting the data:
Value queryResponse = faunaClient.query(
Create(Collection("healthdata"), //)
).get();Next, we will create the actual data object to be inserted. We will define the attributes of the object and its values as entries of a Map and wrap it using the FQL’s Value keyword:
Create(Collection("healthdata"),
Obj("data",
Obj(Map.of(
"userId", Value(healthData.userId())))))
)Here, we are reading the userId from the Health Data record and mapping it to the userId field in the document we are inserting.
Similarly, we can do for all the remaining attributes:
Create(Collection("healthdata"),
Obj("data",
Obj(Map.of(
"userId", Value(healthData.userId()),
"temperature", Value(healthData.temperature()),
"pulseRate", Value(healthData.pulseRate()),
"bpSystolic", Value(healthData.bpSystolic()),
"bpDiastolic", Value(healthData.bpDiastolic()),
"latitude", Value(healthData.latitude()),
"longitude", Value(healthData.longitude()),
"timestamp", Now()))))Finally, let’s log the response of the query so that we are aware of any issues during query execution:
log.info("Query response received from Fauna: {}", queryResponse);
Note: For the purpose of this article, we have built the Edge services as a Spring Boot application. In production, these services can be built in any language and deployed across the global network by Edge providers such as Fastly, Cloudflare Workers, Lambda@Edge etc.
Our integration is complete; let’s test the entire flow with an integration test.
8. Testing End-to-End Integration
Let’s add a test to verify that our integration is working end-to-end and our requests are going to the correct Fauna regions. We’ll mock the GeoLocationService to toggle the region for our tests:
@SpringBootTest
class DefaultHealthServiceTest {
@Autowired
private DefaultHealthService defaultHealthService;
@MockBean
private GeoLocationService geoLocationService;
// ...
} Let’s add a test for the EU region:
@Test
void givenEURegion_whenProcess_thenRequestSentToEURegion() {
HealthData healthData = new HealthData("user-1-eu",
37.5f,
99f,
120, 80,
51.50, -0.07,
ZonedDateTime.now());
// ...
}Next, let’s mock the region and call the process method:
when(geoLocationService.getRegion(51.50, -0.07)).thenReturn("EU");
defaultHealthService.process(healthData);When we run the test, we can check in the logs that the correct URL was fetched to create the FaunaClient:
Creating Fauna Client for Region:EU with URL:https://db.eu.fauna.com/And we can also check the response returned from the Fauna server that confirms the record was created correctly:
Query response received from Fauna:
{
ref: ref(id = "338686945465991375",
collection = ref(id = "healthdata", collection = ref(id = "collections"))),
ts: 1659255891215000,
data: {bpDiastolic: 80,
userId: "user-1-eu",
temperature: 37.5,
longitude: -0.07, latitude: 51.5,
bpSystolic: 120,
pulseRate: 99.0,
timestamp: 2022-07-31T08:24:51.164033Z}}We can also verify the same record in our Fauna dashboard under the HealthData collection for the EU database:
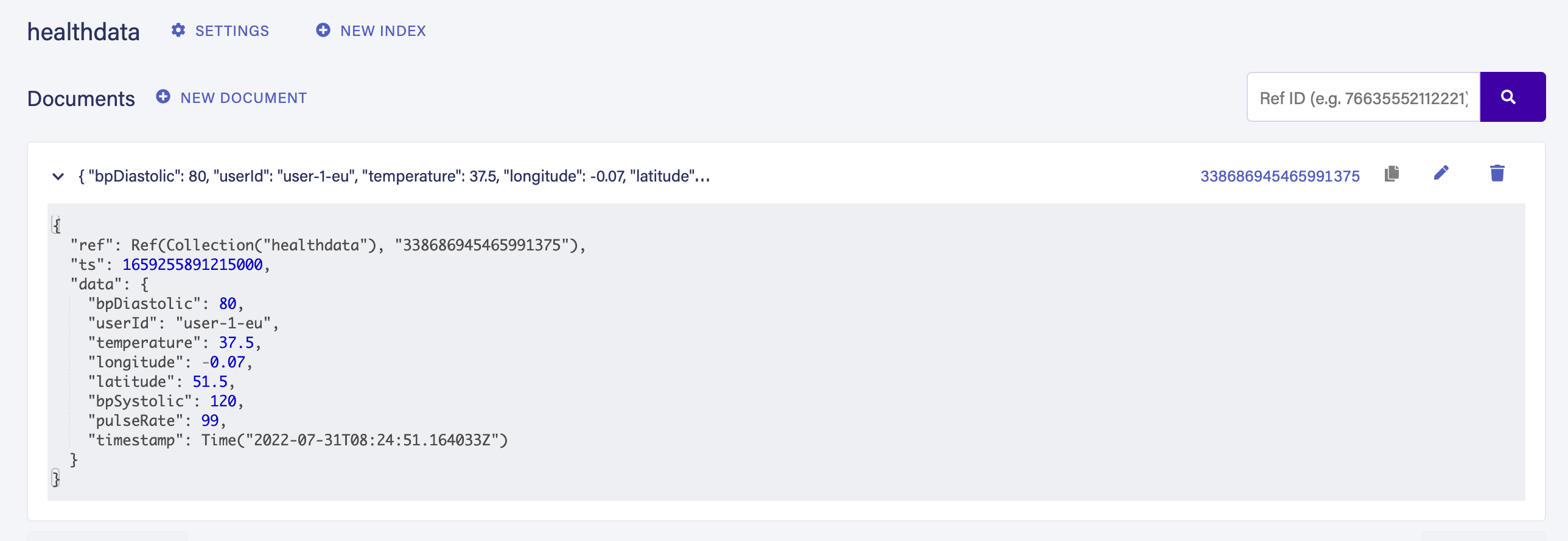
Similarly, we can add the test for the US region:
@Test
void givenUSRegion_whenProcess_thenRequestSentToUSRegion() {
HealthData healthData = new HealthData("user-1-us", //
38.0f, //
100f, //
115, 85, //
40.75, -74.30, //
ZonedDateTime.now());
when(geoLocationService.getRegion(40.75, -74.30)).thenReturn("US");
defaultHealthService.process(healthData);
}9. Conclusion
In this article, we’ve explored how we can leverage Fauna’s Distributed, Document-relational and serverless features to use it as a database for IoT applications. Fauna’s Region groups infrastructure addresses locality concerns and mitigates the Edge servers’ latency issues.
All the code shown here is available over on Github.
