

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll present and compare two search algorithms. Those are Uniform-Cost Search (UCS) and Best-First Search.
In a search problem, we want to find the shortest sequence of actions that transform the start state to a goal state. A state can be anything. For example, a point on a map or an arrangement of the pieces on a chessboard.
We determine the sequence by finding the shortest path between the start and the goal in an abstract graph whose nodes represent the states, and the directed edges are the actions leading from one state to another. Searching through the graph, we create a search tree. Its nodes represent the paths to various states. The distinction between states and nodes in the tree is vital since multiple nodes may refer to the same state:
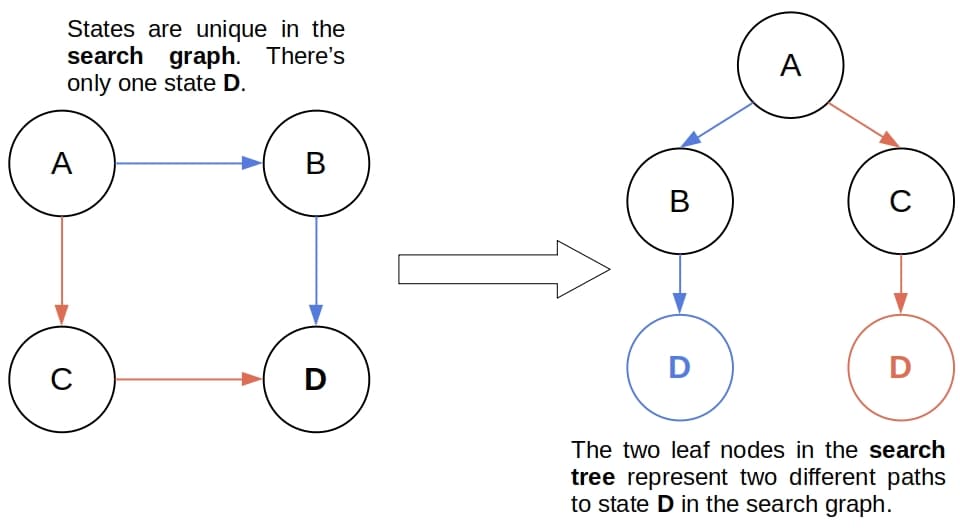
We usually denote a node by the end state of the path it represents.
The edges connecting the nodes in the search graph may have weights that we also call costs. In those cases, we aren’t interested in the path containing the fewest edges between the start and the goal but in the one with the lowest cost.
If there are multiple-goal states, we want the best of all the paths that lead to any goal.
We use a Uniform-Cost Search (UCS) to find the lowest-cost path between the nodes representing the start and the goal states.
UCS is very similar to Breadth-First Search. When all the edges have equal costs, Breadth-First Search finds the optimal solution. However, if the costs differ, it may return a sub-optimal path:
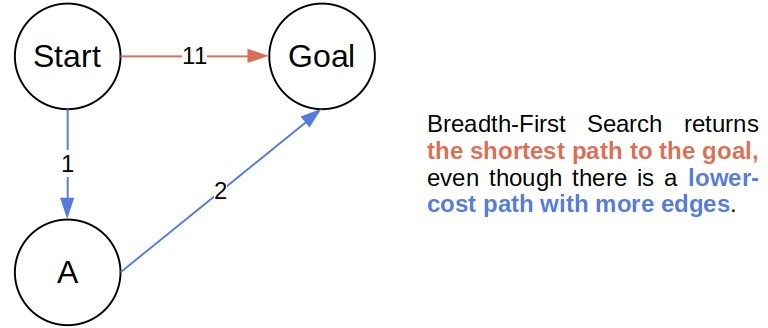
UCS improves on Breadth-First Search by introducing three modifications.
First, it uses a priority queue as its frontier. It sorts the frontier nodes in the order of  , the cost of the path from the start node to the frontier nodes. When choosing a node for expansion, UCS selects from the frontier the one with the minimal value of
, the cost of the path from the start node to the frontier nodes. When choosing a node for expansion, UCS selects from the frontier the one with the minimal value of  , i.e., the one with the lowest cost.
, i.e., the one with the lowest cost.
However, once we add a node to the frontier, it doesn’t mean that we know the cost of the optimal path to the node’s state. If we expand a node  and find that the path through to its neighbor
and find that the path through to its neighbor  costs less than
costs less than  , where
, where  is a frontier node that represents the same state as , then we should remove from the frontier and replace it with . This queue update step is the second modification.
is a frontier node that represents the same state as , then we should remove from the frontier and replace it with . This queue update step is the second modification.
The third is applying the goal test after expanding the node, not when we put it in the frontier. If we test the nodes before storing them in the queue, we could return a sub-optimal path to the goal. Why? Because UCS can find a better path later in its execution.
Let’s take a look at the example of a sub-optimal path returned by Breadth-First Search. If we stop the search immediately after expanding  and realizing that the goal node
and realizing that the goal node  is its neighbor, we’ll miss the optimal path which passes through
is its neighbor, we’ll miss the optimal path which passes through  .
.
So, here’s the pseudocode of Uniform-Cost Search:
algorithm UniformCostSearch(s, goal, successors, c):
// INPUT
// s = the start node
// goal = a function that can check if a node is a goal node
// successors = a function that returns the nodes whose states we obtain
// by applying an action to the input node's state
// c = a function that returns the cost of an edge between two nodes
// OUTPUT
// The optimal path to a goal or failure if no node passes the goal test
g(s) <- 0 // g(node) is the cost of the path from s to the node
frontier <- a min-priority queue ordered by g, containing only s
expanded <- an empty set
while true:
if frontier is empty:
return failure
v <- pop the lowest-cost node from frontier
if goal(v) = true:
return v
expanded <- expanded + {v.state}
for w in successors(v):
if w.state not in expanded and no frontier node represents w.state:
g(w) <- g(v) + c(v, w)
Insert w in frontier
else if there is a frontier node u such that w.state = u.state
and g(v) + c(v, w) < g(u):
Remove u from frontier
Insert w in frontierThe version presented here is the graph-search version of the algorithm because it checks if a node’s state is already in the frontier before adding it. A tree-like search doesn’t test for repeated states and is best suitable for the trees. However, we can still use it on graphs in general if we’re ok with the risk of longer execution or running infinitely due to cycles.
We assume that each node that the call to  produces is a structure containing a pointer to the as its parent. So, once UCS returns a node, we can trace the path of actions easily.
produces is a structure containing a pointer to the as its parent. So, once UCS returns a node, we can trace the path of actions easily.
Let’s now show an example of UCS in action. We’ll use the same graph as before. In the beginning, only the start node is in the frontier, and its -value is 0:
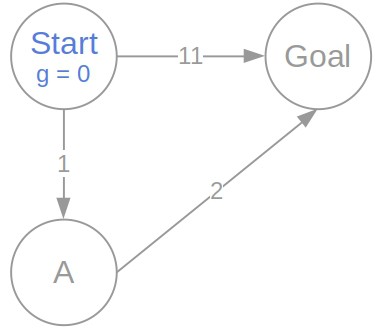
After expanding the start node, we get two nodes in the frontier, and , with the associated -values of 1 and  , respectively:
, respectively:
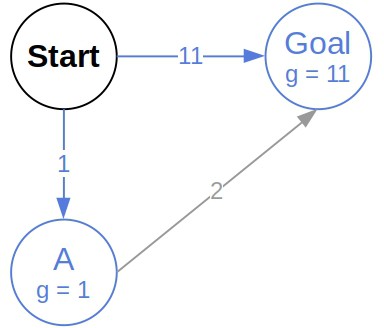
Since has a lower -value, we expand it and see that its successor has a lower cost than the node, also representing in the frontier. So, we replace the frontier with the ‘s successor:
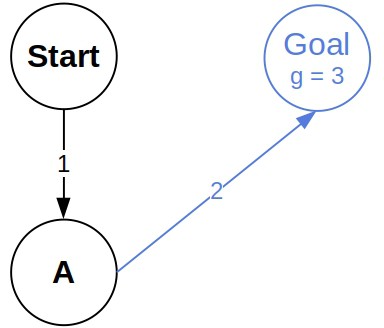
After expanding , we see that it passes the goal test, so we conclude that the optimal path is  .
.
4. Analysis of UCS
We usually ask four questions about a search algorithm:
We answer those questions about UCS in this section.
If the search graph is finite, then the graph-search version of UCS is complete. If the graph is infinite, but no node has an infinite number of neighbors, and all the edges have a positive cost, then the graph-search UCS will also be complete. The condition that edge costs be strictly positive guarantees that there won’t be an infinite path with zero-cost edges whose nodes UCS would keep expanding forever.
However, the tree-like UCS may get stuck in a loop even if the graph is finite. For example, that can happen if there are cycles.
To prove the optimality of UCS, let’s first prove the following property:
Once UCS expands a node  , it has found the optimal path from the start node to
, it has found the optimal path from the start node to  :
:
In other words,  at the point of expanding , where
at the point of expanding , where  is the cost of the optimal path to the state represented by . (Technically, the nodes in the search tree represent the full paths, but it’s common to speak of the nodes as if they represent those paths’ end nodes.)
is the cost of the optimal path to the state represented by . (Technically, the nodes in the search tree represent the full paths, but it’s common to speak of the nodes as if they represent those paths’ end nodes.)
We’ll prove this property by induction on the cardinality of the set of expanded nodes,  . We’ll make use of the fact that
. We’ll make use of the fact that  for any node in the frontier. To see why it holds, let’s remember that we update the priority of any frontier state if we find a better path to it. So,
for any node in the frontier. To see why it holds, let’s remember that we update the priority of any frontier state if we find a better path to it. So,  is the upper bound of
is the upper bound of  . In the induction, we’ll prove that equality holds at the point when UCS pops the node from the frontier to expand it.
. In the induction, we’ll prove that equality holds at the point when UCS pops the node from the frontier to expand it.
In the base step, we have  . It’s the case when UCS pops the start node
. It’s the case when UCS pops the start node  from the queue. By definition,
from the queue. By definition,  , and that’s the cost of the optimal path from the start state to itself since we need not traverse any edge.
, and that’s the cost of the optimal path from the start state to itself since we need not traverse any edge.
Now, we formulate the inductive hypothesis that this property holds for any such that  . In the inductive step, we want to prove that it holds for any
. In the inductive step, we want to prove that it holds for any  .
.
By the inductive hypothesis, the property holds for  , so we only need to prove that it’s true for as well. We’ll do it by contradiction.
, so we only need to prove that it’s true for as well. We’ll do it by contradiction.
So, this is the state of UCS at this point. We chose to pop it from the frontier and expand it, and we’ve got a path to  whose cost is
whose cost is  :
:
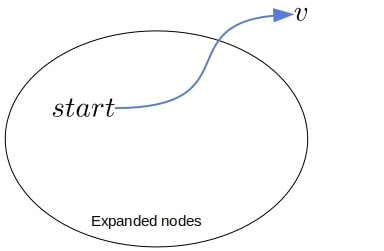
Now, the frontier separates the expanded nodes from the unexpanded ones. So, any path from the start node to an unexpanded node passes through a vertex in the frontier. With that in mind, let’s imagine an alternative path to :
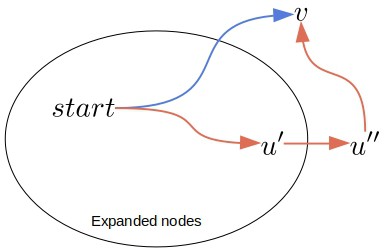
and suppose that it’s the optimal path to , so the blue path isn’t. Then, it holds:
(1)
The last expanded node on the alternative path is  , and the first frontier node it passes through is
, and the first frontier node it passes through is  . The part of the path from to may contain any number of edges. So, provided that the edges have non-negative costs, it must hold that the alternative path’s cost to is at least
. The part of the path from to may contain any number of edges. So, provided that the edges have non-negative costs, it must hold that the alternative path’s cost to is at least  :
:
(2)
Since the edge  is on an optimal path, is expanded, and is its neighbor, the -value of when we pop it will be equal to
is on an optimal path, is expanded, and is its neighbor, the -value of when we pop it will be equal to  :
:
(3)
Also, since UCS chose for expansion, that means that has the minimum -value among all the nodes in the frontier, including . So:
(4)
Chaining the formulae, we get:
(5)
which is a contradiction. So, once we expand , no other path to its state can have a cost lower than . Therefore,  . But, the condition is that all the edges have non-negative costs.
. But, the condition is that all the edges have non-negative costs.
This means that once UCS expands a goal node, it’s found the optimal path to its state. However, there may be more than one goal state. Because the edge costs are non-negative, and UCS expands the frontier nodes in the order of their -value, then any goal node expanded after the first goal node will be on the path that’s at least as costly as that of the first goal.
So, indeed, UCS is optimal and expands nodes in order of their states’ optimal path cost.
Let’s denote the minimal cost of an edge in the search graph as  . Also, let
. Also, let  be the cost of the optimal path to any goal node. For UCS to be complete, we assume that
be the cost of the optimal path to any goal node. For UCS to be complete, we assume that  .
.
Then, the depth in the search tree at which UCS finds the closest goal node is at most  . If
. If  is the upper bound of the branching factor, then the time complexity of the tree-like UCS is
is the upper bound of the branching factor, then the time complexity of the tree-like UCS is  .
.
The same goes for the space complexity. Since the frontier may hold all the nodes at the depth of the closest goal, the space complexity is also .
When it comes to the graph-search UCS, its time complexity is bounded by the size of the graph. If  denotes the nodes, and
denotes the nodes, and  is the set of edges, then the worst-case time complexity of graph-search UCS is
is the set of edges, then the worst-case time complexity of graph-search UCS is  . The space complexity is also .
. The space complexity is also .
Best-First Search (BeFS) is a generic search algorithm. It has all the input arguments of UCS and one additional. The extra argument is an evaluation function  . BeFS uses it to order its frontier that’s implemented as a priority queue:
. BeFS uses it to order its frontier that’s implemented as a priority queue:
algorithm BestFirstSearch(s, goal, successors, c, f):
// INPUT
// s = the start node
// goal = the function that checks if a node is a goal node
// successors = the function that returns the nodes whose states we obtain by applying an action to the input node's state
// c = the function that returns the cost of an edge between two nodes
// f = the function to order the frontier by
// OUTPUT
// The optimal path to a goal or failure if no node passes the goal test
g(s) <- 0
// g(node) is the cost of the path from s to the node
frontier <- a min-priority queue ordered by f, containing only s
reached <- a dictionary of the form {state: node}, containing only s.state: s
while frontier is not empty:
v <- pop the min-f node from frontier
if goal(v) = true:
return v
reached <- expanded + {v.state}
for w in EXPAND(v):
if w.state not in reached or g(w) < g(reached[w.state]):
reached[w.state] <- w
Insert w into frontier
return failure
function EXPAND(v):
for w in successors(v):
g(w) <- g(v) + c(v, w)
yield wBeFS is a generic algorithm because we can change its search strategy by changing the evaluation function.
The formulation presented in Algorithm 2 is the graph-search version of BeFS because it checks for repeated states. That way, BeFS avoids exploring redundant paths. For example, a path to node is redundant if node denotes the same state as , but the path to is shorter. However, to avoid redundant paths, graph-search BeFS requires a lot of memory.
If we can’t store all the nodes in the memory, we can use the tree-like BeFS. We obtain it by removing all the references to  from Algorithm 2. However, we risk getting stuck in infinite cycles, which are special cases of redundant paths.
from Algorithm 2. However, we risk getting stuck in infinite cycles, which are special cases of redundant paths.
A compromise could be to check only for cycles. We can do that when we expand in Algorithm 2. For each child , we should check if  appears on the path to . That can be done by following the pointers until we reach the start node. So, we won’t get stuck in a loop, but we may explore more paths than necessary.
appears on the path to . That can be done by following the pointers until we reach the start node. So, we won’t get stuck in a loop, but we may explore more paths than necessary.
If we define  as the cost of the path from the start node to , then we get UCS. If we set to be the depth of in the search tree, BeFS becomes Breadth-First Search. Could we get Depth-First Search (DFS)? Yes, we can, if we set to be the negative depth of . However, DFS is usually implemented as a recursive algorithm.
as the cost of the path from the start node to , then we get UCS. If we set to be the depth of in the search tree, BeFS becomes Breadth-First Search. Could we get Depth-First Search (DFS)? Yes, we can, if we set to be the negative depth of . However, DFS is usually implemented as a recursive algorithm.
We can get BeFS to simulated informed search strategies as well. For instance, if we use as the heuristic estimate  of the distance to the goal, we get the Greedy Best-First Search (GBFS), which isn’t an optimal algorithm. But, if we combine the of UCS with of GBFS, we get the famous A* algorithm:
of the distance to the goal, we get the Greedy Best-First Search (GBFS), which isn’t an optimal algorithm. But, if we combine the of UCS with of GBFS, we get the famous A* algorithm:
![\[f(u) = \underbrace{\text{the cost of the path from the start node to }u}_{g(u)} + \underbrace{\text{the estimate of the cost of the path from }u \text{ to a goal state}}_{h(u)}\]](/wp-content/ql-cache/quicklatex.com-a7aec1324f24aa0d954f918da60bfdb4_l3.svg "Rendered by QuickLaTeX.com")
The completeness, optimality, and complexity of BeFS depend on the choice of the evaluation function.
For example, we won’t get an optimal algorithm if we use only a heuristic to order the frontier. If we use the negative depth, we get DFS, which isn’t a complete algorithm. However, if we use the depth of a node as the evaluation function, we get Breadth-First Search, which is completely under certain conditions.
Unlike UCS that is a fully specified uninformed algorithm, BeFS is a generic form of search method. Using different evaluation functions, BeFS can simulate numerous search techniques, both informed and informed. Without fully specifying the ordering strategy, we can’t run BeFS.
What makes such a profound difference is precisely the function  used for ordering the frontier. In BeFS, is an input parameter that we can vary. In contrast, we can’t change the way UCS sorts its queue.
used for ordering the frontier. In BeFS, is an input parameter that we can vary. In contrast, we can’t change the way UCS sorts its queue.
Which is better? When should we use BeFS and when UCS? First of all, since UCS is an instance of BeFS, we’re technically executing BeFS when we run UCS. But, the BeFS formulation of UCS may be slower in practice since the frontier ordering function is an actual function that would add its frames to the recursion stack. The alternative is to implement UCS from scratch and without any reference to BeFS.
We can implement any BeFS strategy without calling the BeFS routine. Moreover, those implementations can be faster because ordering the frontier doesn’t involve calling a function of its own.
However, it’s easier to implement an algorithm by specifying only the function for the frontier instead of coding the entire algorithm. That’s certainly the case if we want to switch from one search strategy to another.
In this article, we talked about Uniform-Cost Search (UCS) and Best-First Search (BeFS). The former is a fully specified uninformed search strategy, whereas the latter is a generic algorithm that can simulate various search methods, both informed and uninformed. While we can simulate UCS with BeFS, native UCS implementations will usually execute faster.




