

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: November 11, 2022
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In graph theory, the shortest path problem is about finding a path between two vertices in a graph such that the total sum of the path edge weights is minimum. We can use both Dijkstra’s algorithm and the uniform-cost search algorithm to find the shortest paths between vertices in a graph.
In this tutorial, we’ll introduce these two algorithms and compare them.
Given a source vertex  in a weighted directed graph
in a weighted directed graph  where all edge weights are non-negative, Dijkstra’s algorithm can find the shortest path between
where all edge weights are non-negative, Dijkstra’s algorithm can find the shortest path between  and every other vertex in
and every other vertex in  . Let’s first start with a general framework of the Dijkstra’s algorithm:
. Let’s first start with a general framework of the Dijkstra’s algorithm:
algorithm Dijkstra(G, s):
// INPUT
// G = weighted directed graph (G = (V, E))
// s = the source vertex
// OUTPUT
// dist = the shortest paths' weights from s to all vertices
for v in V:
dist[v] <- +infinity
dist[s] <- 0
Q <- empty vertex set
for v in V:
add v to Q with key dist[v]
while Q is not empty:
u <- the vertex in Q with smallest dist[u]
remove u from Q
visited[u] <- true
if dist[u] == +infinity:
break
for v in Adj(u) and not visited[v]:
dist <- dist[u] + w(u, v)
if dist < dist[v]:
dist[v] <- dist
update Q for vertex v
return dist
In this algorithm, we first set zero distance to our initial vertex and infinity to all other vertices. Also, we start with an initial vertex set,  , which contains all vertices in the graph
, which contains all vertices in the graph  .
.
At every iteration of the loop, we first extract the vertex  with the minimal distance value. Then, for each unvisited neighbor
with the minimal distance value. Then, for each unvisited neighbor  of
of  , we update its distance value with formula
, we update its distance value with formula ![dist[v] = min(dist[v], dist[u] + w(u, v))](/wp-content/ql-cache/quicklatex.com-f474433a6203531be59fc841927668cb_l3.svg "Rendered by QuickLaTeX.com") , where
, where  is the weight of edge
is the weight of edge  . In the end, for each vertex
. In the end, for each vertex  ,
, ![dist[v]](/wp-content/ql-cache/quicklatex.com-55c1ed9b03431d060d5915051ea21c36_l3.svg "Rendered by QuickLaTeX.com") contains the shortest path weight between
contains the shortest path weight between  and .
and .
The time complexity of Dijkstra’s algorithm depends on how we implement .
If we use a min-priority queue with binary min-heap, each extraction takes  time, where
time, where  is the number of vertices in . There are such operations. Also, we need to update the priority queue when we change the distance value of an adjacent vertex. Each update operation takes time. There are at most
is the number of vertices in . There are such operations. Also, we need to update the priority queue when we change the distance value of an adjacent vertex. Each update operation takes time. There are at most  such operations, where is the number of edges in .
such operations, where is the number of edges in .
Therefore, the overall time complexity of Dijkstra’s algorithm is  .
.
The general Dijkstra’s algorithm can find the shortest path between the source vertex and every other vertex in . In some applications, we only want to find the shortest path between a source vertex and a destination vertex  .
.
It is easy to extend the general Dijkstra’s algorithm to solve this single-pair shortest path problem. Firstly, we can stop the loop when we see the extracted vertex is our destination vertex . Secondly, we can use a new data structure  to record the previous vertex along the shortest path. In this way, we can build the whole shortest path after we finish the loop:
to record the previous vertex along the shortest path. In this way, we can build the whole shortest path after we finish the loop:
algorithm DijkstraPair(G, s, d):
// INPUT
// G = (V, E) = a weighted directed graph
// s = the source vertex
// d = the destination vertex
// OUTPUT
// The list of vertices on the shortest path between s and d
for v in V:
dist[v] <- +infinity
dist[s] <- 0
Q <- empty vertex set
for v in V:
add v to Q with key dist[v]
while Q is not empty:
u <- find the vertex in Q with smallest dist[u]
remove u from Q
if u = d:
break
visited[u] <- true
if dist[u] = +infinity:
break
for v in Adj(u) and not visited[v]:
dist <- dist[u] + w(u, v)
if dist < dist[v]:
dist[v] <- dist
update Q for vertex v
prev[v] <- u
return buildPath(s, d, prev)
In the  function, we start with the destination vertex and gradually add the previous vertices into the path based on the data in the . We stop building the path once we reach the source vertex :
function, we start with the destination vertex and gradually add the previous vertices into the path based on the data in the . We stop building the path once we reach the source vertex :
algorithm buildPath(s, d, prev):
// INPUT
// s = the source vertex
// d = the destination vertex
// prev = the map of previous vertices in shortest path
// OUTPUT
// The path from s to d
path <- create an empty list
v <- d
while v != s:
insert v at the front of path
v <- prev[v]
insert s at the front of path
return pathBest-first search is a search algorithm that traverses a graph by expanding the most promising vertex based on a specified rule. The uniform-cost search algorithm is a simple version of the best-first search scheme, where we only evaluate the cost to the start vertex when we choose a vertex to expand.
We can also use the uniform-cost search algorithm to find the shortest path between a source vertex and every other vertex in graph . In this algorithm, we first start with a single vertex and then gradually expand to other vertices. Similar to Dijkstra’s algorithm, we choose a vertex whose distance to is minimum in each expanding step.
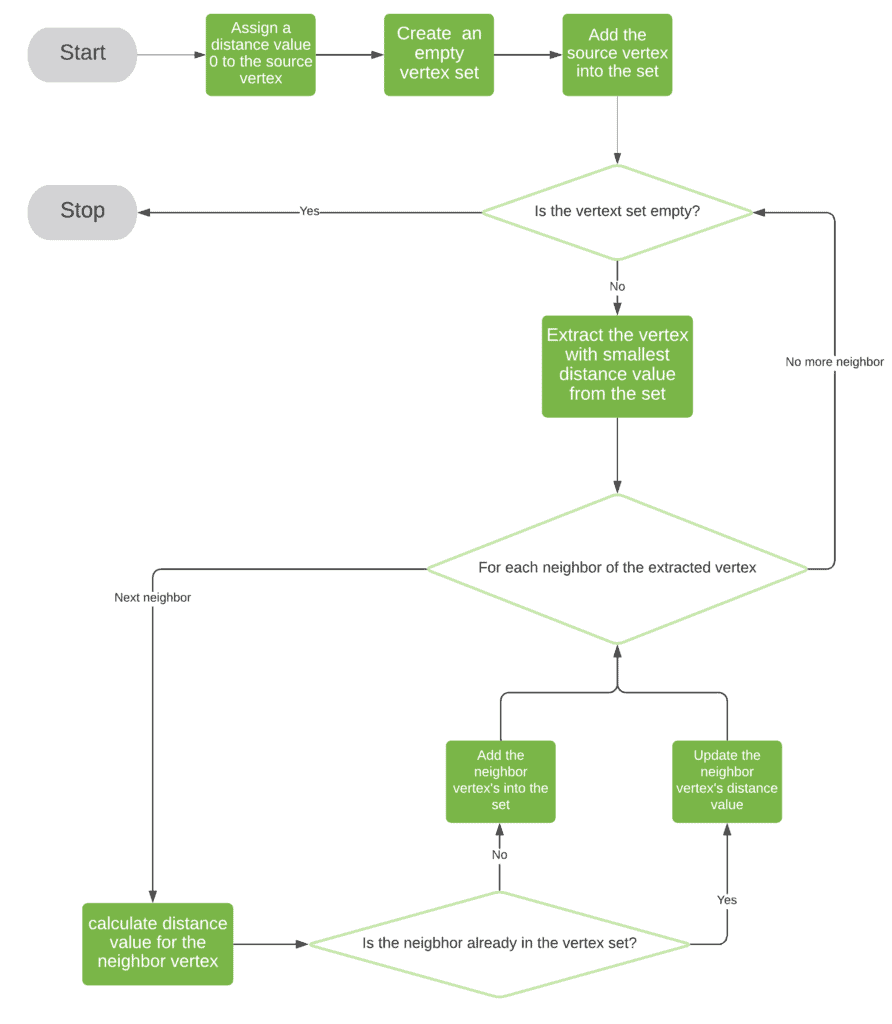
In this algorithm, we start with an initial vertex set, , which only contains the start vertex . Then, we use a loop to process vertices inside to calculate the shortest paths from the start vertex to all the other vertices in .
At every iteration of the loop, we first extract the vertex with the minimal distance value. Then, for each neighbor of , we calculate its distance value with formula , where is the weight of edge . If the neighbor vertex is already in the , we just update its associated distance value. Otherwise, we add the neighbor vertex into .
We keep this looping process until is empty. The time complexity of the uniform-cost algorithm is also  , if we use a min-priority queue to implement .
, if we use a min-priority queue to implement .
We can translate the flowchart of the uniform-cost search algorithm into the pseudocode:
algorithm UniformCost(G, s):
// INPUT
// G = (V, E) = a weighted directed graph
// s = the source vertex
// OUTPUT
// dist = the shortest paths' weights from s to all vertices
dist[s] <- 0
Q <- create an empty vertex set
add s to Q with key dist[s]
while Q is not empty:
u <- find the vertex in Q with smallest dist[u]
remove u from Q
for v in Adj(u):
dist <- dist[u] + w(u, v)
if v in Q:
if dist < dist[v]:
dist[v] <- dist
update Q for vertex v
else:
dist[v] <- dist
add v to Q with key dist[v]
return dist
Similarly, we can extend the uniform-cost algorithm to solve the single-pair shortest path problem:
algorithm UniformCostPair(G, s, d):
// INPUT
// G = (V, E) = a weighted directed graph
// s = the source vertex
// d = the destination vertex
// OUTPUT
// The path from s to d
dist[s] <- 0
Q <- create an empty vertex set
add s to Q with key dist[s]
while Q is not empty:
u <- find the vertex in Q with smallest dist[u]
remove u from Q
if u = d:
break
for v in Adj(u):
dist <- dist[u] + w(u, v)
if v in Q:
if dist < dist[v]:
dist[v] <- dist
prev[v] <- u
update Q for vertex v
else:
dist[v] <- dist
add v to Q with key dist[v]
prev[v] <- u
return buildPath(s, d, prev)
In this algorithm, we stop the loop when we see the extracted vertex is our destination vertex . Also, we use a data structure to record the previous vertex along the shortest path. In the end, we call the function to construct the shortest path.
Both Dijkstra’s algorithm and the uniform-cost algorithm can solve the shortest path problem with the same time complexity. They have similar code structures. Also, we use the same formula, , to update the distance value of each vertex.
The main difference between these two algorithms is how we store vertices in . In Dijkstra’s algorithm, we initialize with all vertices in . Therefore, Dijkstra’s algorithm is only applicable for explicit graphs where we know all vertices and edges.
However, the uniform-cost search algorithm starts with the source vertex and gradually traverses the necessary graph parts. Therefore, it is applicable for both explicit graphs and implicit graphs.
For the single-pair shortest path problem, Dijkstra’s algorithm has more memory requirements as we store the entire graph in memory. By contrast, the uniform-cost search algorithm only stores the source vertex at the beginning and stops expanding once we reach the destination vertex. Therefore, the uniform-cost search algorithm may only store a partial graph in the end.
Although both algorithms have the same time complexity on the single-pair shortest path problem, Dijkstra’s algorithm can be more time consuming due to memory requirements.
When we implement with a min-heap priority queue, each queue operation takes  time, where
time, where  is the number of vertices in . Dijkstra’s algorithm puts all vertices into at the beginning. For a large graph, its vertices will create a big overhead when performing operations on .
is the number of vertices in . Dijkstra’s algorithm puts all vertices into at the beginning. For a large graph, its vertices will create a big overhead when performing operations on .
However, the uniform-cost search algorithm starts with a single vertex and gradually includes other vertices during the path building. Therefore, we’ll work on a much smaller number of vertices when we do priority queue operations.
Another small difference between these two algorithms is the final distance values on vertices that are not reachable from the source vertex. In Dijkstra’s algorithm, if there is no path between the source vertex and a vertex , its distance value () is  . However, in the uniform-cost search algorithm, we cannot find such value in the final distance map, i.e., does not exist.
. However, in the uniform-cost search algorithm, we cannot find such value in the final distance map, i.e., does not exist.
We can use a table to summarize our comparison results:
| Initialization | Memory Requirement | Running Time | Application | |
|---|---|---|---|---|
| Dijkstra’s algorithm | A set of all vertices in G | Need to store the whole graph | Slower due to large memory requirement | Explicit graphs only |
| Uniform-cost search algorithm | A set with only the source vertex | Only store necessary vertices | Faster due to less memory requirement | Implicit and explicit graphs |
In this tutorial, we showed both Dijkstra’s algorithm and the uniform-cost search algorithm. Also, we extended both algorithms to solve the single-pair shortest path problem. By comparing these two algorithms, we can see that the uniform-cost search algorithm can perform better than Dijkstra’s algorithm on large graphs.