

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Text mining, also known as text analysis, converts unstructured text into structured data to enable analysis.
In this tutorial, we’ll learn about text mining. But, before doing this, let’s take a quick look at the organization of the text data.
Text is one of the most common types of data in databases. Depending on the database, these data may be organized:
Text mining greatly benefits organizations because almost 80% of the world’s data is unstructured.
We can convert unstructured texts into a structured format utilizing text mining tools and natural language processing methodologies such as information extraction to enable analysis and the generation of high-quality insights.
This improves organizational decision-making, resulting in improved business outcomes.
Natural language processing is used automatically in text mining to glean insightful information from unstructured material. Text mining automates the process of categorizing texts by sentiment, topic, and intent by converting data into knowledge that computers can comprehend.
Businesses may now quickly, and efficiently examine complicated and large data sets thanks to text mining. Companies also use this effective technology to automate time-consuming and repetitive operations, saving their employees significant time and allowing customer service representatives to focus on what they do best.
Text mining, also known as text data mining, transforms unstructured information into a structured format to uncover significant patterns and new insights. Natural language processing (NLP) is a text-mining technology that assists computers in automatically understanding and analyzing human conversations. The relationship between text mining, data mining, natural language processing and information retrieval are shown in the following figure.
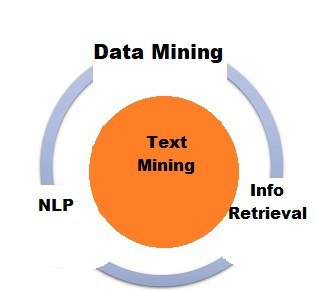
Companies can use advanced analytical approaches such as Naive Bayes, Support Vector Machines (SVM), and other deep learning algorithms to examine and discover hidden correlations within their unstructured data. In a word, text mining enables businesses to maximize the value of their data, which improves the quality of data-driven business choices.
“How does text mining accomplish all of this?” questions may arise. The response instantly introduces us to the idea of machine learning.
A branch of artificial intelligence called machine learning focuses on developing algorithms that let computers learn from examples how to perform specific tasks. Machine learning models must first be taught with data before they can automatically forecast with a particular level of accuracy. Automated text analysis is made possible by combining text mining and machine learning.
Text mining assists in studying massive amounts of raw data to uncover meaningful insights. It can be combined with machine learning to create text analysis models that learn to classify or extract specific information based on previous training.
Text mining may appear to be a complex topic, but it’s actually very simple to learn.
The first step in getting started with text mining is to collect data. Assume we want to investigate user interactions with our live chat system. The first step is to generate a document with this information.
Internal data (interactions via chats, emails, surveys, spreadsheets, databases, and so on) or external data (information gathered from social media, review sites, news outlets, and so on).
The second step is to prepare our data. Text mining systems use NLP techniques such as tokenization, parsing, lemmatization, stemming, and stop removal to generate inputs for machine learning models. The text analysis can now proceed.
Although “text mining” and “text analytics” are frequently used interchangeably in daily speech, they can also mean various things. Text mining and text analysis integrate machine learning, statistics, and linguistics to uncover linguistic and textual patterns and trends in unstructured data.
By transforming the data into a more structured format through text mining and text analysis, more quantitative insights can be found utilizing text analytics. Then, we can use data visualization techniques to share our findings with more people.
Therefore, the difference between text mining and text analytics can be explained accordingly. In essence, they both attempt to employ different approaches to handle the same problem (automatically analyzing raw text input). Text mining finds relevant information within a text and hence yields high-quality results.
Text analytics, on the other hand, focuses on discovering patterns and trends in massive data sets, yielding more quantitative results. Text analytics is commonly used to generate graphs, tables, and other visual outputs. The relationship between text mining and text analytics is shown in the following figure. It’s given together with the relevant concepts.
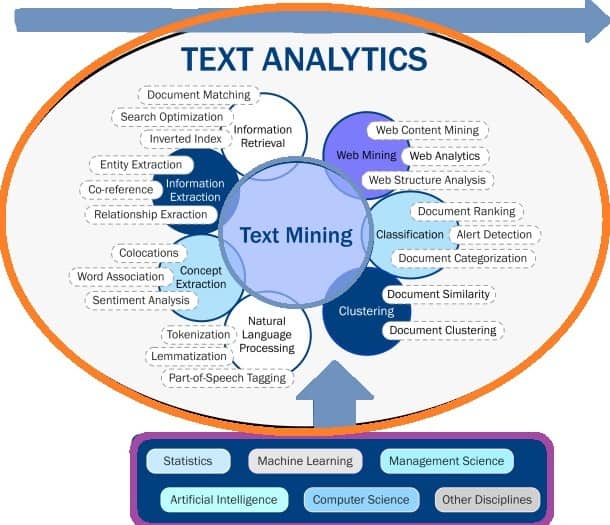
Text mining uses statistics, linguistics, and machine learning techniques to build models that learn from training data and can predict results on new information based on their prior experience.
Text analytics, on the other hand, uses the results of text mining model studies to generate graphs and other sorts of data visualization.
The optimal course of action must be decided based on the type of information presented. Both approaches are frequently blended for each analysis, yielding more convincing results.
Text mining is a method that consists of various steps that let us infer information from unstructured text data. The process of cleaning and converting text data into a usable format is called text preprocessing, and it must be done before we can use any of the various text mining techniques.
Natural language processing (NLP) is a key component of this process, and to properly prepare data for analysis, it typically uses methods including language identification, tokenization, part-of-speech tagging, chunking, and syntax parsing.
After text preprocessing is finished, text mining techniques can be used to extract insights from the data. Among these widespread text mining methods are explained in the following sub-sections.
In this sub-section, we’ll learn about some basic methods like word frequency, collocation and concordance.
Word frequency can be used to find the most frequent terms or ideas in a data set. Discovering the most frequently used words in unstructured text can be useful when evaluating customer reviews, social media interactions, or consumer feedback.
If the words outrageous, overpriced, and overrated regularly show in our clients’ reviews, it could be a hint to us that there is a need to change our rates or target market.
Collocation is a group of words that commonly appear together. The two most common types of collocations are bigrams (a pair of words that are likely to go together, such as get started, save time, or decision making) and trigrams (a combination of three words, such as within walking distance or keep in touch). Collocations should be recognized and counted as a single word to increase the text’s granularity, better grasp its semantic structure, and ultimately produce more accurate text mining results.
Concordance is used to identify the specific context or instance in which a word or group of words appears. We know that human language may be ambiguous: the same term can be employed in various contexts. Analyzing a word’s concordance might help us to grasp its exact meaning, dependent on context.
Information retrieval retrieves relevant information or documents based on a predefined set of queries or phrases. Information retrieval systems use algorithms to monitor user activities and identify relevant information.
Library catalogue systems and well-known search engines such as Google are examples of typical information retrieval applications. The following are some examples of common information retrieval subtasks:
Tokenization is the technique of dividing long-form text into “tokens” of sentences and words. These are then utilized in the models for text clustering and document matching tasks, much like bag-of-words.
Stemming is the process of eliminating prefixes and suffixes from words to determine the base word form and meaning. This approach improves information retrieval by making indexing files smaller.
Natural language processing, which evolved from computational linguistics, employs techniques from various domains, including computer science, artificial intelligence, linguistics, and data science, to assist computers in comprehending human language in both written and verbal forms. It’s represented in the following figure:
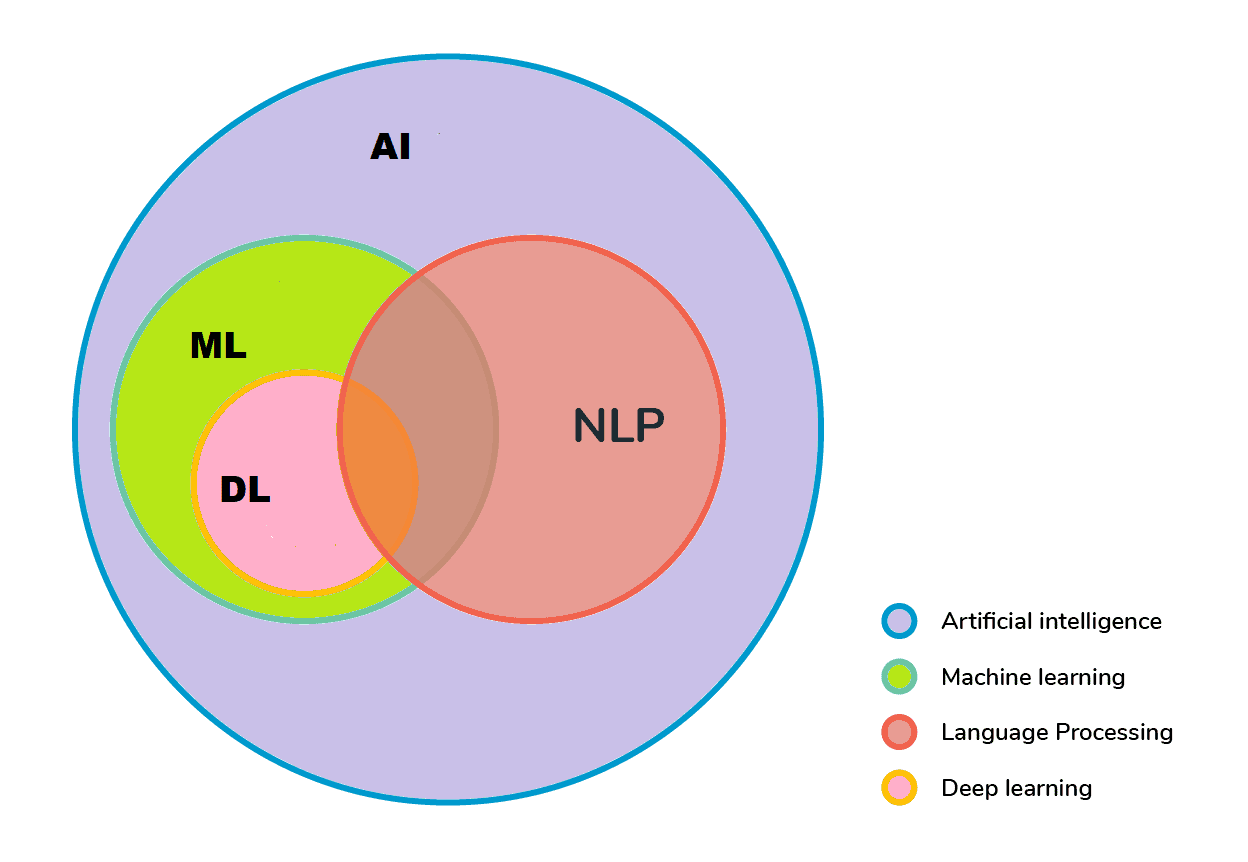
Computers can “read” by examining grammar and sentence structure using natural language processing subtasks. Here are some examples of typical sub-tasks:
The summarization technique uses a summary of a lengthy text to create a quick, thorough overview of a document’s key topics.
Part-of-Speech (PoS) tagging technique assigns a tag to each token in a document depending on the part of speech it represents, such as nouns, verbs, adjectives, and so on. This level enables semantic analysis of unstructured text.
Text categorization, or text classification, is the process of evaluating text documents and categorizing them according to preset topics or categories. This subtask simplifies the process of categorizing synonyms and abbreviations.
Sentiment analysis allows us to monitor changes in consumer attitudes over time by detecting positive or negative sentiments from internal or external data sources. It’s frequently used to present data on consumer perceptions about names, goods, and services. These insights can motivate companies to engage with customers, enhance workflows, and enhance user experiences.
When reading through many documents, information extraction extracts the relevant information. It also stresses structured data extraction from free text and database storage of extracted entities, attributes, and relationship data.
The following are examples of common information extraction subtasks:
Data mining is the process of discovering patterns and meaningful insights in massive data collections. This strategy, which evaluates structured and unstructured data to reveal new information, is commonly used in marketing and sales to investigate consumer behaviour.
Text mining is a branch of data mining since it focuses on providing unstructured data structure and analyzing it to provide unique insights. Textual data analysis incorporates all of the previously listed data mining methodologies.
Text analytics software has altered how many industries work by allowing them to improve product user experiences and make faster and wiser business choices. Here are some examples of use cases:
Every day, people and businesses generate massive volumes of data. Approximately 80% of all text data is unstructured, which means it lacks a fixed structure, cannot be searched for, and is extremely difficult to manage. To put it another way, it’s entirely ineffective.
For businesses, organizing, categorizing, and extracting pertinent information from raw data is a significant problem. For this goal, text mining is essential.
Unstructured text data in a company setting can include emails, comments made on social media, conversations, support tickets, surveys, etc. Manually sorting through all of this information frequently fails. It’s costly and time-consuming, but it’s also imprecise and impractical to scale.
However, text mining has shown to be a dependable and economical method for achieving accuracy, scalability, and quick reaction times. More specifically, the following are some of its key advantages:
As an example, consider tagging. Adding categories to emails or support tickets requires work for most teams, frequently leading to errors and inconsistencies. Automating this process produces more accurate findings and ensures that a consistent set of rules is applied to every ticket and saves a significant amount of time.
In this tutorial, we learned about text mining. In this context, we discussed its description, how it works, text mining methodologies, text mining use cases, and the usefulness of text mining.