

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: November 11, 2022
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss the problem of finding the path from the root to a node on a binary tree. This problem can have many versions. Thus, we’ll explain the general idea with an example.
Also, we’ll present two versions of the problem and describe the solutions to each one.
First of all, we need to define the path from the root to a node on a binary tree.
Let’s take the following example:
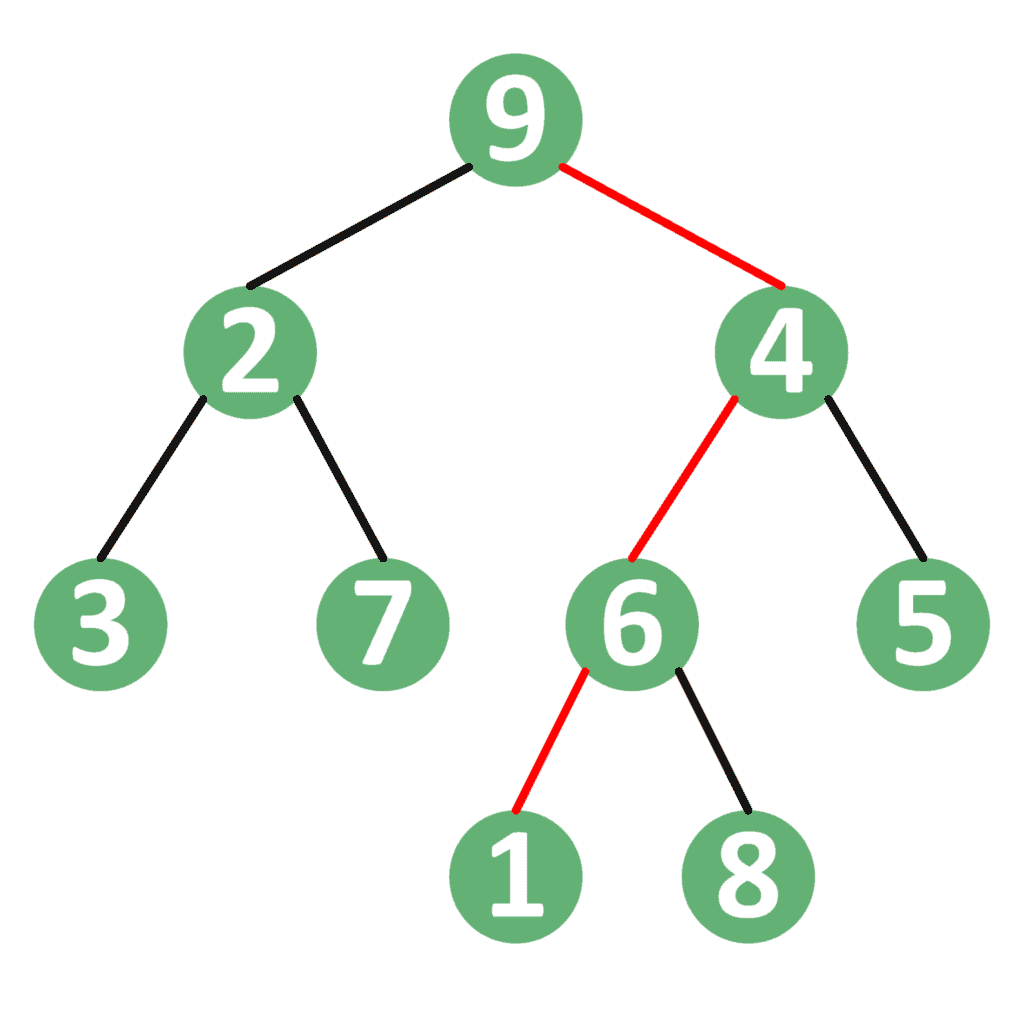
In the example, the root is node  . If we need to get the path from the root to node
. If we need to get the path from the root to node  , then we notice that it goes from the root to nodes
, then we notice that it goes from the root to nodes  ,
,  , and then node .
, and then node .
Similarly, if we need to go from the root to node  , we’ll pass through node
, we’ll pass through node  .
.
In general, there are two ways to get the path to a node in a tree. Either we start from the root and move to the child that is an ancestor to the target node. Or, we start from the target node and keep moving up to its parent until we reach the root.
Both approaches are perfectly fine. However, it depends on the information stored inside each node of the tree. For example, if each node doesn’t contain a pointer to its parent, then we can’t use the second approach.
It’s important to note that, starting from the root, we can find a single path that connects the root with a specific node. The reason is that trees are undirected graphs that don’t contain cycles. Hence, we can find only one sequence on nodes that starts from the root and ends at each node.
Depending on the property of the path, the problem can have many versions. In this tutorial, we’ll discuss two versions of this problem.
In this version of the problem, we’re given a binary tree rooted at some node. We’re asked to return a list that contains all the nodes starting from the root and ending at a given target node.
This problem can be solved using two approaches. Let’s discuss each of them separately.
The top-down approach performs a DFS (Depth First Search) operation starting from the root. In each step, it recursively searches for the target node starting from the left and right children.
Let’s take a look at the implementation of the top-down approach:
algorithm FindPathTopDown(root, target):
// INPUT
// root = the root of the binary tree
// target = the target node
// OUTPUT
// path from the root to the target node
path <- []
result <- DFS(root, target)
if result = true:
return path
else:
return null
function DFS(u, target):
if u = null:
return false
append u to path
if u = target:
return true
result <- DFS(u.left, target)
if result = true:
return true
result <- DFS(u.right, target)
if result = true:
return true
else:
remove the last element from path
return false
Firstly, we initialize the  list to be empty. This list will be used to store the nodes in the current path that the DFS function is exploring.
list to be empty. This list will be used to store the nodes in the current path that the DFS function is exploring.
Secondly, we perform a DFS call starting from the current node. We pass the target node as well so that the DFS function can stop when it reaches the target node. If the DFS function returns  , then the node was found, and we return the nodes stored inside the list .
, then the node was found, and we return the nodes stored inside the list .
Otherwise, we simply return  indicating that the target node doesn’t exist in this branch of the tree.
indicating that the target node doesn’t exist in this branch of the tree.
Inside the DFS function, we start by checking whether we reached a value. If so, we simply return  indicating that the target node isn’t found in this branch. Otherwise, we add the current node to the path.
indicating that the target node isn’t found in this branch. Otherwise, we add the current node to the path.
If we reached the target node, then we return , which should stop the function from going deeper inside the tree. Otherwise, we perform a recursive call for the left and right children.
If one of these calls return , we stop immediately and return true as well to prevent the function from going deeper inside the tree.
If both functions return  , then the target node wasn’t found inside this branch of the tree. In this case, we remove the current node from the path and return indicating that the searching operation should continue from other nodes.
, then the target node wasn’t found inside this branch of the tree. In this case, we remove the current node from the path and return indicating that the searching operation should continue from other nodes.
The complexity of the top-down approach is  , where
, where  is the number of nodes inside the binary tree.
is the number of nodes inside the binary tree.
In this approach, we reverse the process. Instead of starting from the root, we start from the target node.
Let’s take a look at the implementation of the bottom-up approach:
algorithm FindPathBottomUp(root, target):
// INPUT
// root = the root of the binary tree
// target = the target node
// OUTPUT
// path from the root to the target node
path <- []
u <- target
while u != root:
add u to path
u <- u.parent
add root to path
reverse path
return pathWe start from the target node. In each step, we move up to the parent of the current node.
This process continues until we reach the root. Once we reach the root, it means we found the needed path. Hence, we stop the  loop.
loop.
However, we have one thing to pay attention to. Since the  loop breaks once we reach the root, it means the root won’t be added to the list. Hence, we add the root to the list once the loop is finished.
loop breaks once we reach the root, it means the root won’t be added to the list. Hence, we add the root to the list once the loop is finished.
Assuming that each  operation adds the node to the end of the list, we’ll end up with a reversed path that starts from the target node and ends at the root. Thus, we reverse the list before returning it.
operation adds the node to the end of the list, we’ll end up with a reversed path that starts from the target node and ends at the root. Thus, we reverse the list before returning it.
The complexity of the bottom-up approach is  , where
, where  is the height of the tree. The reason is that we only explore the needed path inside the tree. Thus, we might finish without exploring all the nodes inside the tree.
is the height of the tree. The reason is that we only explore the needed path inside the tree. Thus, we might finish without exploring all the nodes inside the tree.
Of course, the worst case is when  . In this case, the complexity will be
. In this case, the complexity will be  , but this is only correct for almost linear trees.
, but this is only correct for almost linear trees.
The bottom-up approach is better in terms of complexity and is usually the recommended approach to use.
However, it has two main requirements. The first requirement is that we should be able to get a pointer to the target node quickly. Thus, we’d be able to start from the target node instead of starting from the root.
On the other hand, the second requirement is that we should have the parent of each node stored inside the node structure. Otherwise, we won’t be able to move to the parent in each step.
If one of these two requirements isn’t possible to achieve, then we should consider using the top-down approach instead.
In this problem, we’re asked to find all the paths inside a binary tree that start from the root, such that the sum of the values inside each node of the path equal to a target sum.
Let’s have a look at the top-down and bottom-up approaches in the case of this problem.
The top-down approach is similar to the one presented above. Let’s take a look at the top-down approach implementation:
algorithm FindAllPathsTargetSum(root, target):
// INPUT
// root = the root of the binary tree
// target = the target sum
// OUTPUT
// all paths from the root with a target sum
path <- []
answer <- []
DFS(root, 0, target)
return answer
function DFS(u, sum, target):
if u = null:
return
append u to path
sum <- sum + u.value
if sum = target:
add path to answer
DFS(u.left, sum, target)
DFS(u.right, sum, target)
remove the last element from path
We start by initializing the list that will store the current path we’re traversing. Also, we initialize the  list that will store the answer.
list that will store the answer.
After that, we call the DFS function and return the answer.
Moving to the DFS function, it takes the current node, the current sum, and the target sum as parameters.
First of all, we check whether we reached , then we simply return. Otherwise, we add the current node to the path and increment the sum. If the sum reaches the target sum, we store a copy of the list inside the answer.
Note that, in case we reached the target sum, we don’t stop the function. The reason is that if some nodes have a zero value, we want to allow the function to extend the path a little more.
The next step is to perform a recursive DFS call for both the left and the right children with the updated sum. Once these calls are finished, we remove the current node from the path to allow exploring other ones inside the tree.
The complexity of the top-down approach is  , where is the number of nodes, and is the height of the tree. The reason is that whenever we reach a node, we might have a valid answer, and we need to store a copy of it to the answer.
, where is the number of nodes, and is the height of the tree. The reason is that whenever we reach a node, we might have a valid answer, and we need to store a copy of it to the answer.
Hence, we might need to copy the list at most times. Also, the list can have at most nodes because any path that starts from the root can have at most nodes.
Note that, in this problem, there is no point in starting from the target node and move up to the parent each time until we reach the root. The reason is that we don’t have a target node. Instead, we have a target sum that we need to achieve.
In this case, we’d need to start from every node inside the tree and keep moving up to the root while accumulating the sum of nodes’ values. If we follow this approach, we’ll end up with an approach that has a worse complexity than the top-down approach.
Besides, we’d need to have direct access to each node inside the tree and be able to move from each node to its parent.
Hence, there is no point in solving this problem using the bottom-up approach.
In this tutorial, we discussed the problem of finding the paths inside a binary tree that starts from the root and has a specific property.
Firstly, we discussed the problem of finding the path that ends at a target node. We presented two approaches to solving this problem.
Secondly, we explained the problem of finding all paths that have a target sum. For this version, we only explained the top-down approach.