

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
How to Find the Minimum Difference Between Elements in an Array
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll show how to find the two numbers with the minimum absolute difference in an array.
2. The Minimal Difference
We have a numerical array ![a=[a_1, a_2, \ldots, a_n]](/wp-content/ql-cache/quicklatex.com-ab69e48e98f035d4a2ca8900d620e676_l3.svg "Rendered by QuickLaTeX.com") and want to find the two closest numbers.
and want to find the two closest numbers.
For example, if ![a=[1, 5, 31, 7, 11]](/wp-content/ql-cache/quicklatex.com-6ff169d2c107358bb4493ac2ba5870f0_l3.svg "Rendered by QuickLaTeX.com") , the minimal absolute difference is between
, the minimal absolute difference is between  and
and  , so our algorithm should output the pair
, so our algorithm should output the pair  .
.
3. Solution
Let’s suppose that we’ve sorted  in the non-decreasing order:
in the non-decreasing order:  . Then, the closest number to each
. Then, the closest number to each  is immediately before or right after it. In other words, we need to check only the differences between the consecutive elements if the array is sorted (the order doesn’t matter).
is immediately before or right after it. In other words, we need to check only the differences between the consecutive elements if the array is sorted (the order doesn’t matter).
So, we can find the minimal difference by iterating over the sorted and computing  for each
for each  . For instance, sorting , we get
. For instance, sorting , we get ![[1, 5, 7, 11, 31]](/wp-content/ql-cache/quicklatex.com-7ebc2da9577456b5cb31fe53713975c6_l3.svg "Rendered by QuickLaTeX.com") . The absolute differences between consecutive elements are
. The absolute differences between consecutive elements are  , respectively. Therefore, the answer is the second pair: .
, respectively. Therefore, the answer is the second pair: .
3.1. Pseudocode
Here’s the pseudocode:
algorithm FindTwoClosestNumbers(a):
// INPUT
// a = an array of n numbers
// OUTPUT
// (p, q) = a pair with the minimal absolute difference in a
a <- sort a
(p, q) <- (a[1], a[2])
for i <- 3 to n:
if |a[i-1] - a[i]| < |p - q|:
(p, q) <- (a[i-1], a[i])
return (p, q)First, we sort the array. Then, we declare the first pair  as the current closest pair and loop over the rest. We update the current closest pair if we find two consecutive numbers with a smaller absolute difference.
as the current closest pair and loop over the rest. We update the current closest pair if we find two consecutive numbers with a smaller absolute difference.
3.2. Complexity
What’s the time complexity of this approach? It depends on the sorting algorithm because the search for the minimal difference in the sorted array is  in the worst and average cases. With Merge Sort, the sorting part takes
in the worst and average cases. With Merge Sort, the sorting part takes  time in the worst case, so the entire algorithm’s complexity is
time in the worst case, so the entire algorithm’s complexity is  .
.
If we used Quicksort, whose worst-case time complexity is  , our approach would also be quadratic in the worst case. However, Quicksort is log-linear in the average case and has a smaller multiplicative coefficient than the Merge Sort. For that reason, pairing the linear search with Quicksort instead of Merge Sort may work faster in practice, although the latter is asymptotically more favorable.
, our approach would also be quadratic in the worst case. However, Quicksort is log-linear in the average case and has a smaller multiplicative coefficient than the Merge Sort. For that reason, pairing the linear search with Quicksort instead of Merge Sort may work faster in practice, although the latter is asymptotically more favorable.
Now, the question is: can we do better?
4. Rabin’s Algorithm in One Dimension
And the answer is that we can, at least when it comes to probabilistic time complexity. In 1976, Michael O. Rabin formulated a randomized algorithm for finding the closest pair in  and proved it achieved a linear time complexity with high probability. For
and proved it achieved a linear time complexity with high probability. For  , the closest-pair problem reduces to ours.
, the closest-pair problem reduces to ours.
4.1. The Idea
The main idea is as follows. First, we sample  pairs
pairs  of numbers from (
of numbers from ( ) and compute the minimal difference between the pairs. Let’s denote it as
) and compute the minimal difference between the pairs. Let’s denote it as  . Afterward, we sort all the numbers into consecutive segments of length .
. Afterward, we sort all the numbers into consecutive segments of length .
Then, the closest two numbers are either in the same segment or in two neighboring ones:
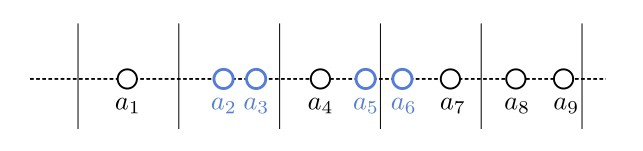
So, we iterate over the segments and find the closest pairs in each segment and every two consecutive ones, keeping track of the minimal difference calculated. In the end, it corresponds to the actual minimum difference in .
4.2. Pseudocode
Here’s the pseudocode:
algorithm RabinsAlgorithm(a):
// INPUT
// a = an array of n numbers
// OUTPUT
// (p, q) = a pair with the minimal absolute difference in a
S <- sample n pairs of elements (a[i], a[j]) (i != j)
δ <- compute the minimal difference between the numbers in the same pairs in S
(p, q) <- the closest pair in S
segments <- make an empty dictionary
for i <- 1 to n:
k <- floor(a_i / δ)
Insert a[i] into segments[k]
for k in sort(segments.keys):
(x_k, z_k) <- find the closest pair in segments[k]
(p, q) <- the closer between (p, q) and (x_k, z_k)
if k > 1 and segments[k-1] exists:
Find the closest pair of points (x_k, z_{k-1}) such that
x_k is in segments[k] and
z_{k-1] is in segments[k-1]
(p, q) <- the closer between (p, q) and (x_k, z_{k-1})
return (p, q)First, we sample  pairs and determine the closest one. Let be the absolute difference between those two numbers. Then, we divide the array into
pairs and determine the closest one. Let be the absolute difference between those two numbers. Then, we divide the array into  -wide segments (let’s suppose there are
-wide segments (let’s suppose there are  of those). We can determine the segment into which
of those). We can determine the segment into which  falls by rounding down the quotient
falls by rounding down the quotient  . So, we keep the numbers that belong to the same segment in the same entry of
. So, we keep the numbers that belong to the same segment in the same entry of  , a dictionary whose integer keys identify the -wide segments, and the values are arrays (lists or trees) of the corresponding elements.
, a dictionary whose integer keys identify the -wide segments, and the values are arrays (lists or trees) of the corresponding elements.
Afterward, we loop over the keys in in the sorted order. The closest two numbers in the entire array are either in the same segment or two consecutive ones. So, looping over ![segments[1], segments[2], \ldots, segments[m]](/wp-content/ql-cache/quicklatex.com-56f5da9da96e3fe8e8a19bed8bb6ae5a_l3.svg "Rendered by QuickLaTeX.com") , we compare the current closest pair
, we compare the current closest pair  to the closest one in each
to the closest one in each ![segments[k]](/wp-content/ql-cache/quicklatex.com-c9a86830938b4f3835d257329ddcb85a_l3.svg "Rendered by QuickLaTeX.com") . If
. If ![segments[k-1]](/wp-content/ql-cache/quicklatex.com-b93ff05c675d240d1279186ba0f87983_l3.svg "Rendered by QuickLaTeX.com") exists, we compare to the two numbers such that one belongs to and the other to .
exists, we compare to the two numbers such that one belongs to and the other to .
4.3. Time Complexity
This algorithm has a linear expected time complexity with high probability, even if we use the quadratic brute-force approach to find the closest pairs in individual segments.
5. Conclusion
In this article, we showed how to find the closest two numbers in an array. We presented two algorithms: one based on sorting and the other randomized. The former is log-linear in the worst case if we use Merge Sort, but the latter achieves a linear expected time with high probability.