

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss Kosaraju’s algorithm.
It’s one of the efficient algorithms for finding strongly connected components (SCCs) in directed graphs.
Let’s assume we have a directed graph  with
with  vertices and
vertices and  edges. We’ll denote the vertices of by
edges. We’ll denote the vertices of by  and the edges by
and the edges by  .
.
The notion of SCC for directed graphs is similar to the notion of connected components for undirected graphs. Formally, SCC in is a subset of , such that:
 in the same component, there’s a directed path from
in the same component, there’s a directed path from  to
to  and from to
and from to  SCC to SCC breaks the first condition
SCC to SCC breaks the first conditionAny non-empty directed graph contains at least one SCC, and SCCs naturally divide  into non-intersecting subsets. Let’s check out some examples.
into non-intersecting subsets. Let’s check out some examples.
The graph below contains four SCCs – each vertex is a separate SCC:
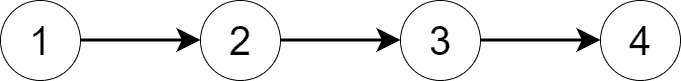
Below, we can see a bit more complex graph:
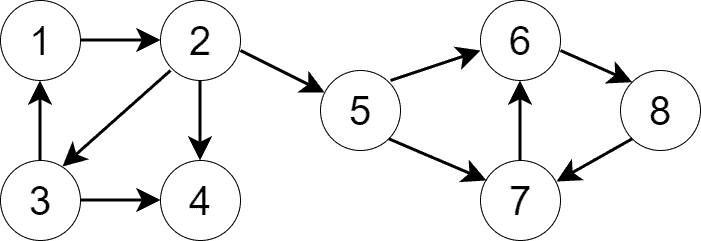
It also has four SCCs:
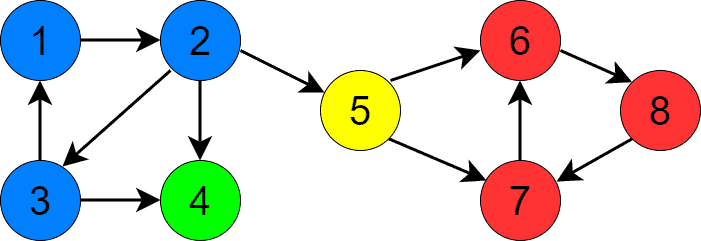
We’ve colored SCCs differently to distinguish them visually.
In this section, we’ll provide a step-by-step explanation of Kosaraju’s algorithm for finding SCCs. It has three steps.
In the first step, we perform a DFS traversal to define the priorities of the vertices. More specifically, for each vertex, we remember when DFS finishes processing. The later DFS is done with a vertex, the higher its priority. This step is similar to topological sorting, but it’s not the same since the latter is only possible for DAGs.
The previous section shows the result of running this step for the graph. We started the process from vertex 1 (but we could start from any node). The priorities are red numbers:
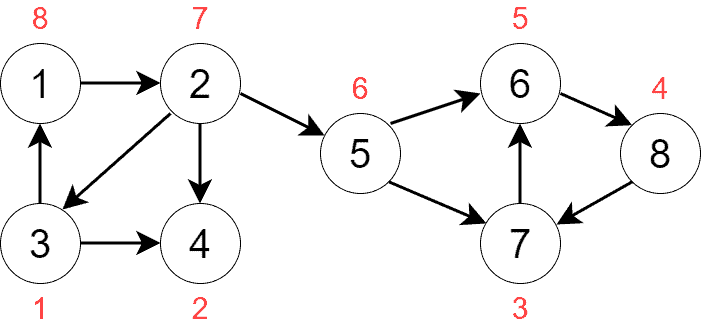
We push the vertices onto a stack during DFS traversal according to the priorities. The stack’s content at the end of the process will be: [3, 4, 7, 8, 6, 5, 2, 1].
In the second step, we build the transpose graph of . The transpose graph is a graph that consists of the same vertices as the original graph, but the edge directions are reverted. Here’s the transpose graph  of :
of :
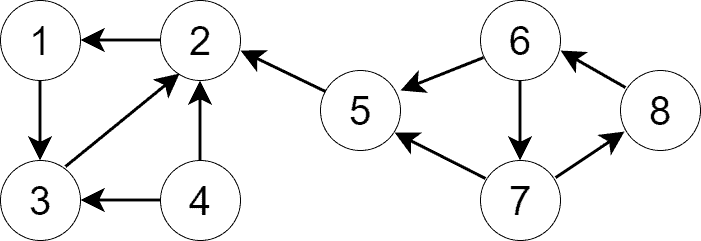
We can construct as a separate graph or invert the edges in .
In the third step, we perform a DFS traversal on  . Each DFS invocation finds one SCC. So, the number of SCCs is equal to the number of times we invoke DFS on . Each time we call a DFS procedure, we use the non-visited node with the highest priority.
. Each DFS invocation finds one SCC. So, the number of SCCs is equal to the number of times we invoke DFS on . Each time we call a DFS procedure, we use the non-visited node with the highest priority.
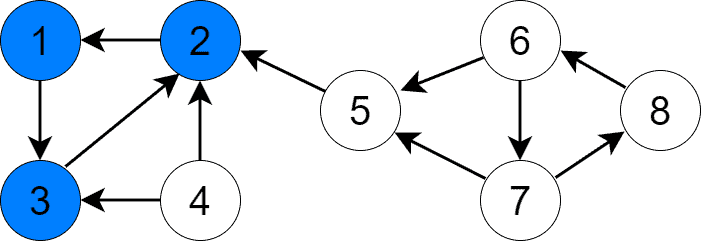
Let’s see how this step finds SCCs in our graph. After step 2, the highest-priority node is vertex 1, so we start the first DFS from that node. DFS visits vertices 1, 3, and 2 in this order and stops, finding us one SCC:
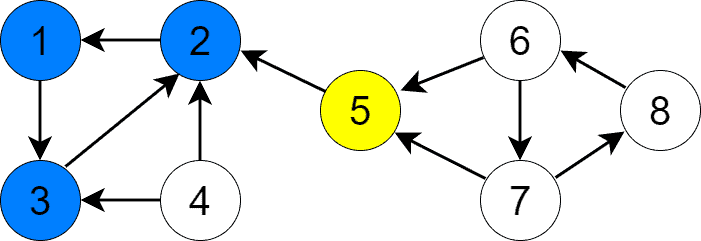
The next vertex with the highest priority is 5, as vertex 2 is already visited. We call DFS with node 5 as its argument and find the second SCC containing only that node:
Vertex 6 is the next vertex to visit. DFS visits 6, 7, and 8 in this order and returns:
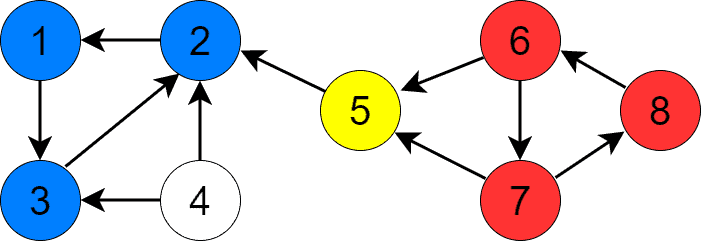
Lastly, we invoke DFS for vertex 4 and find the last SCC containing only that vertex:
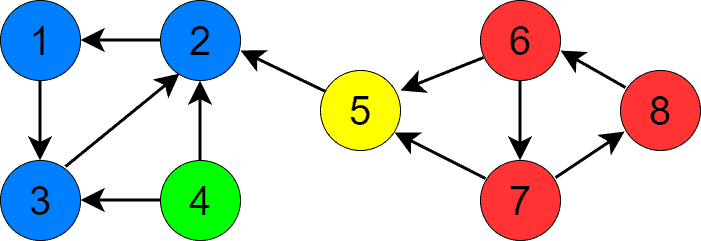
At this point, we’ve found all the SCCs and the algorithm terminates.
First, let’s implement DFS. We need two of them: the common one traversing a graph and the second one building vertex priorities. Below we can find the pseudocode for the common DFS:
algorithm CommonDFS(G, v, visited):
// INPUT
// G = the graph
// v = the starting vertex
// visited = an array to track if a vertex has been visited
// OUTPUT
// Visits all vertices reachable from v
visited[v] <- true
process vertex v
for u in G.neighbours[v]:
if visited[u] = false:
DFS(G, u, visited)Below is the pseudocode for the DFS procedure, which builds vertex priorities:
algorithm DFSWithVertexPriorities(G, v, priority, visited):
// INPUT
// G = the graph
// v = the starting vertex
// priority = a stack to push vertices by their priorities
// (the first pushed vertex has the lowest priority)
// visited = an array to track visited vertices
// OUTPUT
// Visits all vertices reachable from v
// and puts them into the priority stack according to the visited time.
visited[v] <- true
for u in G.neighbours[v]:
if visited[u] = false:
DFSWithVertexPriorities(G, u, priority, visited)
priority.push(v)Now, we’ll implement the logic of the transform graph creation:
algorithm TransformGraphCreation(G):
// INPUT
// G = the original graph
// OUTPUT
// TG = the transpose graph of G
TG <- a new graph of N vertices
for v in G.V:
for u in G.neighbours[v]:
TG.neighbours[u].add(v)
return TGAll the pseudocodes are set up, it’s time to implement Kosaraju’s algorithm:
algorithm KosarajusAlgorithm(G):
// INPUT
// G = the input graph
// OUTPUT
// Strongly connected components are found
visited <- boolean array of size N containing false values
priority <- a vertex stack
for v in G.V:
if visited[v] = false:
PDFS(G, v, priority, visited)
TG <- TransformGraphCreation(G)
Clear array visited
while priority stack is not empty:
v <- priority.pop()
if visited[v] = false:
DFS(TG, v, visited)
process current SCCKosaraju’s algorithm correctly finds SCCs. But why? Let’s make some observations to improve the understanding of the algorithm.
The condensation graph  of
of  is a graph that has SCCs of as vertices. If contains edge
is a graph that has SCCs of as vertices. If contains edge  , such that
, such that  and
and  , then
, then  contains edge
contains edge  . is a DAG because otherwise, it would contain a cycle and all SCCs in the cycle may have been merged into a single SCC. That contradicts the definition of SCC, according to which we can’t merge several SCCs to get a new bigger SCC. Below is the of the graph from our previous examples:
. is a DAG because otherwise, it would contain a cycle and all SCCs in the cycle may have been merged into a single SCC. That contradicts the definition of SCC, according to which we can’t merge several SCCs to get a new bigger SCC. Below is the of the graph from our previous examples:
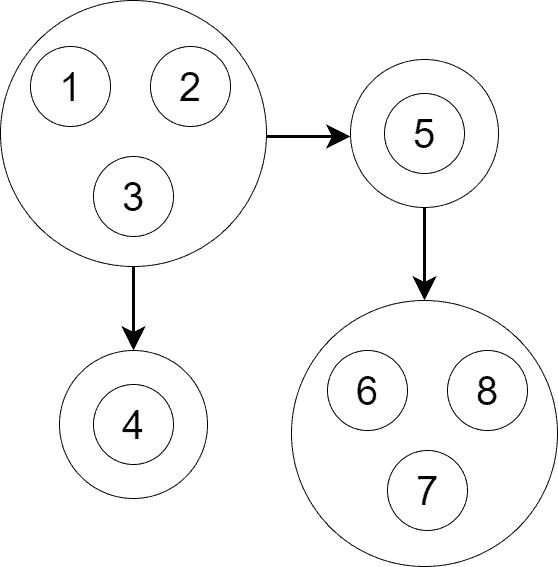
As we see, is a DAG and it contains four vertices. Each vertice corresponds to an SCC.
As is a DAG, it’s possible to perform topological sorting on it. If SCC2 goes after SCC1 in topological sorting order, then step 1 of Kosaraju’s algorithm makes at least one vertex of SCC1 have a higher priority than all the vertices of SCC2. By doing so, it guarantees SCC1 is traversed before SCC2 in step 3.
The transpose graph has the same SCCs as the original graph . Therefore, when we build , semantically, only edges between SCCs are inverted. also guarantees that when we start DFS in the highest priority vertex in step 3, DFS only visits the vertices in the SCC of that vertex. Inverting edges has the effect of isolating DFS from traversing outside of the current SCC. DFS can only visit the vertices in the current SCC and those of SCCs that have already been visited. DFS omits the latter.
We should use adjacency list representation for in Kosaraju’s algorithm to have DFS run in  time. The algorithm consists of three steps depending on the same variables and . So the algorithm’s complexity is the maximum of complexities of each step:
time. The algorithm consists of three steps depending on the same variables and . So the algorithm’s complexity is the maximum of complexities of each step:
, which runs in  , we need to go over all the vertices and edges, so it’s another operation, which also runs in
, we need to go over all the vertices and edges, so it’s another operation, which also runs in Thus, the overall complexity of Kosaraju’s algorithm is .
In this article, we covered Kosaraju’s algorithm. It’s a three-step algorithm for finding strongly connected components (SCCs).
Its first step is to run DFS to set the priorities of the vertices to their DFS exit times. Then, it builds the transpose of the original graph. Finally, the algorithm runs DFS on the transpose graph according to the vertex priorities defined in the first step. Each DFS invocation in the last step finds a separate SCC.