

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about using the K-Means clustering algorithm for classification.
Clustering and classification are two different types of problems we solve with Machine Learning. In the classification setting, our data have labels, and our goal is to learn a classifier that can accurately label those and other data points. In contrast, when we do clustering, the data aren’t labeled, and we aim to group instances into clusters by their similarity.
However, clustering algorithms, such as K-Means, can be integrated with a classifier or train one.
Let’s imagine a set of unlabeled data:
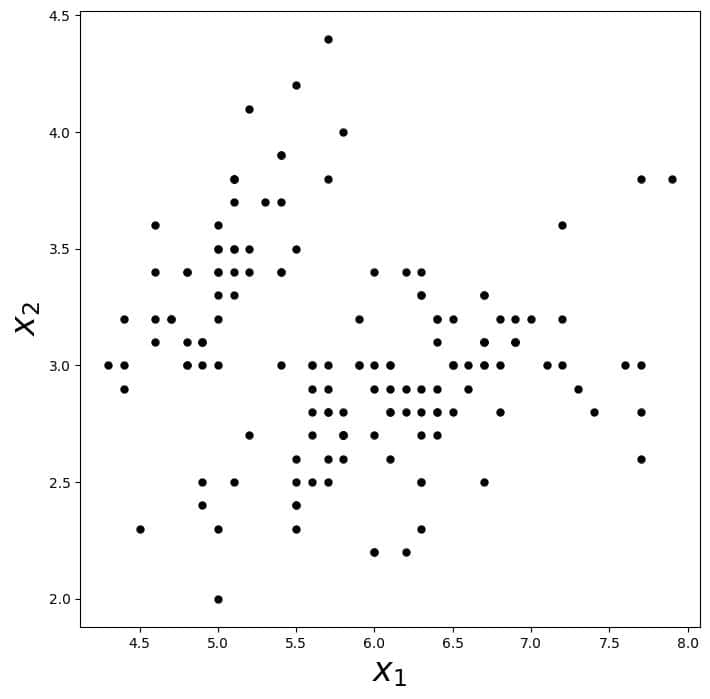
It’s the iris dataset. The  axis is sepal length, and
axis is sepal length, and  is sepal width.
is sepal width.
Now, we don’t have access to the labels but know that the instances belong to two or more classes. In this case, we first cluster the data with K-Means and then treat the clusters as separate classes. This way, we can label all the data (by assigning the instances to the closest cluster), preparing the dataset for training a classifier.
So, we first learn the class labels from the data and then train a classifier to discriminate between the classes discovered while clustering.
For example, K-Means finds these three clusters (classes) and centroids in the above data:
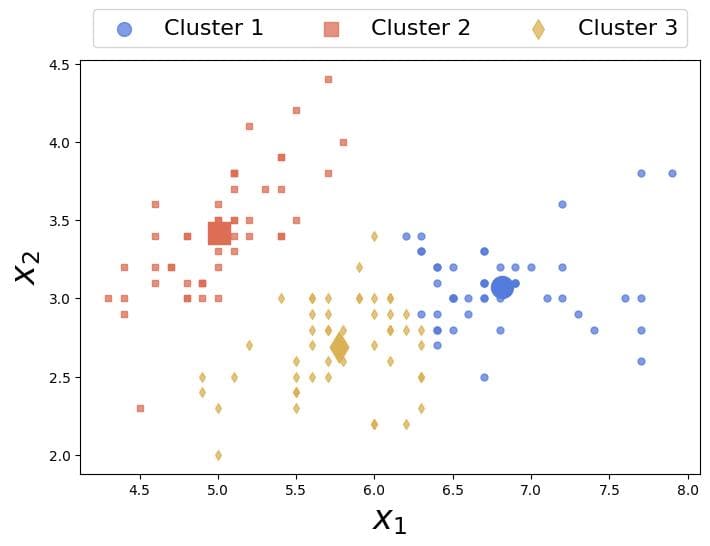 Then, we could train a neural network to differentiate between the three classes.
Then, we could train a neural network to differentiate between the three classes.
We don’t have to train a classifier on top of the clustered data. Instead, we can use the clusters’ centroids for classification. The labeling rule is straightforward. Find the closest centroid and assign the new instance to that cluster:
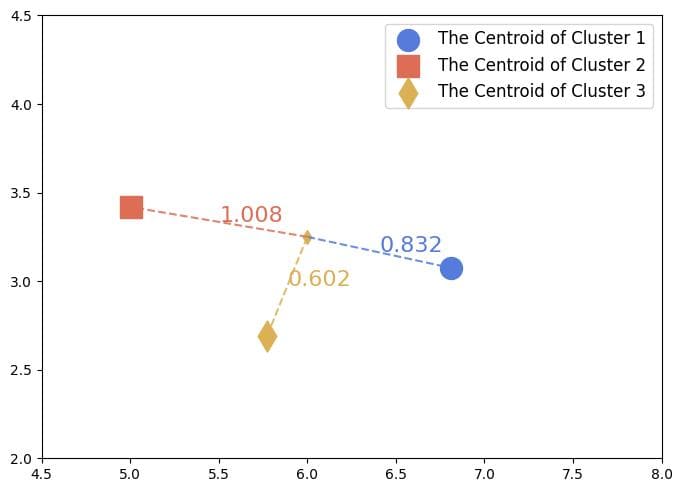
Since the third cluster’s center is the closest to the instance in between the clusters, we give it the label  .
.
The data weren’t labeled in the previous two methods. So, we used K-Means to learn the labels and built a classifier on top of its results by assuming that the clustering errors were negligible.
The assumption, however, may not hold. K-Means requires us to choose the number of clusters in advance. We can go with the elbow heuristic to decide how many clusters to have, but we could be wrong. Even if we identify the correct number of classes, the labels we get with K-Means may be incorrect. That can happen if the distance metric we use doesn’t reflect the similarity between the same-labeled instances.
Unfortunately, this issue is something we can’t resolve. Since we start from the unlabeled data, there’s no ground truth with which we can compare the results of K-Means.
We should also keep in mind that if we discover classes with K-Means or any other clustering algorithm, it’s up to us to determine what each represents.
If our data is labeled, we can still use K-Means, even though it’s an unsupervised algorithm. We only need to adjust the training process. Since now we do have the ground truth, we can measure the quality of clustering via the actual labels. Even more so, we don’t have to guess the number of clusters–we set it to the number of classes.
Once we identify the clusters, we classify a new object by its proximity to the centroids.
Formally, let  be our dataset, where the
be our dataset, where the  are objects, and the
are objects, and the  are their labels. In the usual K-Means, we form
are their labels. In the usual K-Means, we form  clusters by minimizing the withing-group distances. If
clusters by minimizing the withing-group distances. If  is the
is the  th cluster and the number of instances in it, we find the centroids by minimizing:
th cluster and the number of instances in it, we find the centroids by minimizing:
(1) 
We can do that using, e.g., the Expectation-Maximization algorithm.
However, since we know the  , we can also aim to maximize the purity of
, we can also aim to maximize the purity of  . The goal is to have each class appear in only one cluster.
. The goal is to have each class appear in only one cluster.
For example, the Gini impurity index tells us how heterogeneous a cluster is:
![\[G_j = 1 - \sum_{k=1}^{d} \left( \frac{n_{k, j}}{n_j} \right)^2 \qquad n_{k, j} = \left| \{ x_{\ell} \in C_j : y_{\ell} = k \} \right| \quad j=1,2,\ldots,d\]](/wp-content/ql-cache/quicklatex.com-1c1acac9d191db4837207935fb88a0ea_l3.svg "Rendered by QuickLaTeX.com")
We can minimize the probability of error by minimizing the average index even though we don’t explicitly optimize accuracy or the error risk:
(2) 
That’s because we’ll try to force all the instances of the same class into a single cluster, which will separate the classes as much as possible.
We can also combine the average Gini index with the inter-cluster distances. That way, we minimize the withing-cluster distances and the error probability at the same time:
(3) 
It’s interesting to note that K-Means acts as a regularization technique. Since it forms clusters by grouping near objects, the training process has an incentive to find geometrically well-shaped groups. That could prevent overfitting.
To control the trade-off between accuracy and generalization capability, we can include a regularization coefficient  into the objective function (3):
into the objective function (3):
(4) 
A higher  means that we’re more interested in compact shapes than purity, whereas lower values put more weight on minimizing the classification error.
means that we’re more interested in compact shapes than purity, whereas lower values put more weight on minimizing the classification error.
In this article, we showed how to use K-means for classification. Even though it’s an unsupervised clustering algorithm, we can apply it to classification problems.