

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Word embedding is an essential tool for natural language processing (NLP). It has become increasingly popular in recent years due to its ability to capture the semantic meaning of words.
A word embedding is a vector representation of a word in a high-dimensional space. The dimensionality of word embedding is a crucial factor in determining the quality and effectiveness of the embedding.
In this tutorial, we’ll explain the concept of the dimensionality of a word embedding. We’ll also learn how to decide the dimensionality of a word embedding when applying it in the NLP tasks.
In general, the dimensionality of word embedding refers to the number of dimensions in which the vector representation of a word is defined. This is typically a fixed value determined while creating the word embedding. The dimensionality of the word embedding represents the total number of features that are encoded in the vector representation.
Different methods to generate word embeddings can result in different dimensionality. Most commonly, word embeddings have dimensions ranging from 50 to 300, although higher or lower dimensions are also possible.
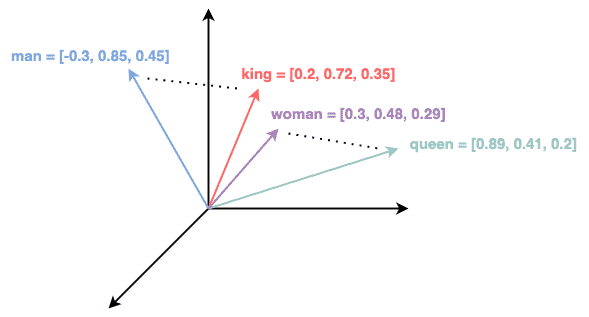
For example, the figure below shows the word embeddings for “king”, “queen”, “man”, and “women” in a 3-dimensional space:
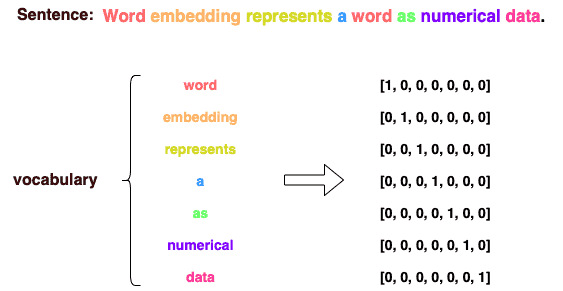
There are multiple ways to generate word representation. One of the classic methods is one-hot encoding, which represents each word in a vocabulary as a binary vector. The dimensionality of the embedding is equal to the size of the vocabulary, and each element of the vector corresponds to a word in the vocabulary.
For example, in the sentence “Word embedding represents a word as numerical data.”, there are 7 unique words. Thus, the dimensionality of the word embedding is 7:
TF-IDF is another commonly used technique to represent words in natural language processing tasks. It is a numerical statistic that reflects how important a word is to a document in a corpus. While using TF-IDF to generate word representations, we build a TF-IDF matrix that calculates the TF-IDF score for all the vocabulary in the corpus. The size of a TF-IDF matrix depends on the number of documents in the corpus and the size of the vocabulary of unique words.
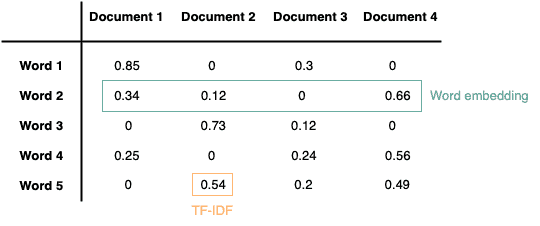
The figure below gives an example of the word embedding for “word 2”. Given a corpus with 4 documents and 5 unique words, the dimensionality of its word embedding is 4:
Recently, distributed representations have been widely used in NLP tasks. A distributed representation of a word is a technique for representing the word as a high-dimensional vector in a continuous vector space. The basic idea behind distributed representation is that words with similar meanings or occurring in similar contexts are closer to each other in the high-dimensional space.
With the development of neural networks, scientists introduced more advanced methods that generate distributed word representations, such as Word2vec, GloVe, BERT, etc.
By using deep learning techniques, the embeddings are learned by the hidden layer of the embedding model. And they are able to capture the semantic and syntactic relationships between words. However, the features of the embedding no long have any meanings. In the meanwhile, there is no universal number for the word embedding dimension. The dimensionality of word embedding depends on different methods and use cases.
Deciding on the appropriate dimensionality for a word embedding depends on several factors, such as the size and nature of the dataset we are using, the specific NLP task we are working on, and the computational resources available to us.
Here are some general guidelines to consider when deciding on the dimensionality of word embedding.
Larger datasets can support higher-dimensional embeddings as they provide more training data to inform the model. As a rule of thumb, a dataset with less than 100,000 sentences may benefit from a lower-dimensional embedding (e.g., 50-100 dimensions), while a larger dataset may benefit from a higher-dimensional embedding (e.g., 200-300 dimensions).
The NLP task we are working on can also inform the dimensionality of our word embedding.
For example, tasks that require a high level of semantic accuracy, such as sentiment analysis or machine translation, may benefit from a higher-dimensional embedding. However, easier tasks such as named entity recognition or part-of-speech tagging may not require as high of a dimensional embedding.
The dimensionality of our word embedding will also affect the computational resources required to train and use the model. Higher-dimensional embeddings require more memory and processing power, so it’s important to consider the computational resources available when deciding on the dimensionality of our word embedding.
Ultimately, the best approach is to experiment with different dimensionalities and evaluate the performance of our model on a validation set. We can gradually increase or decrease the dimensionality until we find the optimal balance between semantic accuracy and computational efficiency for our specific use case.
In this article, we talked about word embedding and the dimensionality of word embedding.
The dimension of the word embedding produced by classic word embedding methods, such as one-hot encoding and TF-IDF, is highly dependent on the size of the corpus and vocabulary. On the other hand, for distributed representations such as Word2vec and GloVe, the optimal dimensionality depends on factors such as the size of the training dataset, the computational resources available, and the specific task at hand. And it is usually set empirically.