

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll talk about Bidirectional Search (BiS). It’s an algorithm for finding the shortest (or the lowest-cost) path between the start and end nodes in a graph.
2. Search
Classical AI search algorithms grow a search tree over the graph at hand. The tree root is the start node, and it grows as the search algorithm visits other vertices. The algorithms stop after reaching the target node and including it in the tree. Breadth-First Search (BFS), Depth-First Search, Uniform-Cost Search (UCS), and A* are examples of such algorithms. They’re all instances of Best-First Search, which is unidirectional: the search spreads in waves from the single node and forms a tree.
2.1. Motivation for Bidirectional Search (BiS)
That’s a straightforward but not necessarily the best way to search for the best path. Let’s take a look at BFS. Its tree-like version has the  worst-case time and space complexities, where
worst-case time and space complexities, where  is the upper bound of the branching factor, and
is the upper bound of the branching factor, and  is the depth of the shallowest goal node. However, if we start the search from the goal node as well, we’ll have two trees with potentially fewer nodes.
is the depth of the shallowest goal node. However, if we start the search from the goal node as well, we’ll have two trees with potentially fewer nodes.
The two trees in Bidirectional BFS grow simultaneously in opposite directions. The forward search tree grows from the start node and tries to reach the goal node, as before. But, the reverse search tree grows from the goal as its root and tries to reach the start. When the two trees meet, we’ve got the shortest path between the start and goal vertices (under certain conditions). But, the total number of nodes in the trees is expected to be lower than if we grew a single tree from the start node:
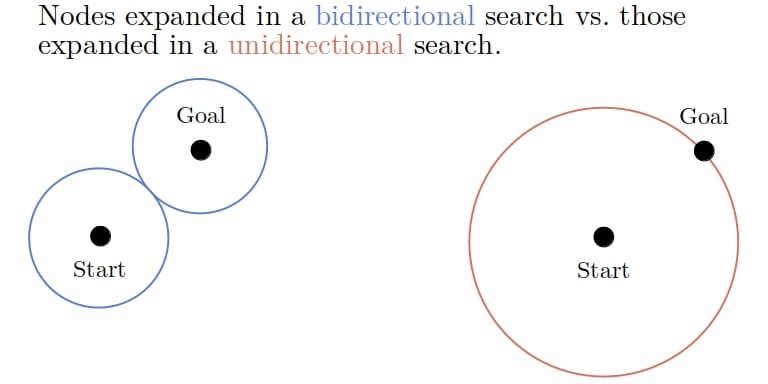
To see why that is, let’s imagine that the trees meet at the middle node on the path from the start to the goal. Then, the trees together contain at most  nodes. With a constant branching factor
nodes. With a constant branching factor  and
and  , unidirectional BFS would grow a tree with
, unidirectional BFS would grow a tree with  nodes in the worst-case scenario, whereas BiBFS’s trees would contain
nodes in the worst-case scenario, whereas BiBFS’s trees would contain  nodes together. That’s five billion times fewer nodes.
nodes together. That’s five billion times fewer nodes.
2.2. Base Algorithms for Bidirectional Search
BiS is a generic search technique. We can use any unidirectional algorithm to run the forward search and combine it with any single-source algorithm for the reverse search. They can but need not be the same. That means that BiS describes a plethora of methods we obtain by combining different base algorithms for the forward and reverse searches.
3. Reverse Edges
A directed edge from  to
to  represents an action the AI agent should take to get from to . However, the reverse search goes in the opposite direction, so it requires the reversal of all the edges in the graph. Therefore, to run a BiS, we have to traverse the graph in both directions.
represents an action the AI agent should take to get from to . However, the reverse search goes in the opposite direction, so it requires the reversal of all the edges in the graph. Therefore, to run a BiS, we have to traverse the graph in both directions.
Unlike the original forward edges, their reverse counterparts can but don’t have to denote actions. A reverse edge from to means that there is an action that leads from to . There need not be a real-world action that leads from to for the reverse arc  to exist. Reversal needs only to be computationally possible.
to exist. Reversal needs only to be computationally possible.
For example, if time is a feature of the nodes, and each forward action has a non-zero duration, then reverse actions will be impossible (unless we’ve got a time machine). Nevertheless, if we’re able to define them computationally, we can use BiS.
4. Bidirectional UCS
When making a case for Bidirectional Search, we said we aimed for the forward and reverse searches to meet somewhere in the graph. That means that they both have reached the same node. However, there are other things we should know to implement a bidirectional algorithm:
- Should we alternate between the searches? If yes, how?
- Does the optimal path necessarily pass through the meeting point?
We’ll answer both questions on the example of Bidirectional UCS (BiUCS).
4.1. Alternation
Conceptually, we are running two searches in parallel. But, in practice, we can’t execute both at the same time on the same CPU. What we can do is interleave the forward and reverse searches.
Let’s define a search step as the body of the main unidirectional UCS loop. In BiUCS, we also have a single main loop, but in each iteration, we choose which search to advance. One strategy could be to alternate between the searches: run a forward, then reverse, then forward again, then reverse again, and so on. The other way would be to execute a step of the search whose frontier’s top node is closer to its source (the start or the goal). Which one is better?
The latter strategy is more consistent with the spirit of unidirectional UCS, and that is to expand the frontier node that’s closest to the source. Since we have two frontiers in BiUCS, we choose the node closer to its frontier’s source. But, the strategy may degenerate to running the search in one direction only. For example, if the edges’ costs exponentially increase with the proximity to the goal, we may not execute any reverse step. To avoid this scenario, we can alternate between the searches by following each forward step by reverse and each reverse step by a forward one. Still, both strategies will work under the stopping criterion we describe next.
4.2. Stopping Condition
We said that the aim of bidirectional search was for the forward and reverse searches to meet at some node . Algorithmically, that’s the point when we reach in one direction after expanding it in the other search. But should we stop the whole algorithm at that point and claim we’ve found the optimal path (through )?
Just as we shouldn’t stop unidirectional UCS after adding a goal node to the frontier, we shouldn’t terminate the bidirectional variant if a node is expanded in one search and put into the frontier in the other. The reason is that there may be a lower-cost path to from the source of the second frontier it’s been added to.
So, what’s the correct stopping condition? Let’s say that  is the cost of the best path we’ve found so far (initially, we set it to
is the cost of the best path we’ve found so far (initially, we set it to  ). Whenever we reach a node we’ve expanded in the other search, we update if a better path goes through the node. Let
). Whenever we reach a node we’ve expanded in the other search, we update if a better path goes through the node. Let  be the current distance from the start and
be the current distance from the start and  the current distance from the goal node. Let
the current distance from the goal node. Let  and
and  be the distances to the top nodes in the forward and reverse frontier queues, respectively. Then, we can stop the algorithm if:
be the distances to the top nodes in the forward and reverse frontier queues, respectively. Then, we can stop the algorithm if:
![\[top_F + top_R \geq \mu\]](/wp-content/ql-cache/quicklatex.com-19ae67782a819c647fd51dcf49546c4d_l3.svg "Rendered by QuickLaTeX.com")
4.3. Correctness of the Stopping Condition
Let’s suppose that the stopping condition  has obtained. For any node unexpanded in the forward search, it holds that
has obtained. For any node unexpanded in the forward search, it holds that  , where
, where  is the actual distance from the start. Similar holds if is unexpanded in the reverse search:
is the actual distance from the start. Similar holds if is unexpanded in the reverse search:  , where
, where  is the actual distance from the goal.
is the actual distance from the goal.
Now, let’s suppose that we’ve expanded a node at a subsequent forward step and that its successor has already been expanded in the reverse search. The path through and will cost  where:
where:
![\[g_F^*(v) \geq top_F\]](/wp-content/ql-cache/quicklatex.com-eb642b540b2d6be79e5f5ff54d24603a_l3.svg "Rendered by QuickLaTeX.com")
because we’ve added to the forward frontier and will expand it later, and:
![\[g_R^*(v) \geq top_R\]](/wp-content/ql-cache/quicklatex.com-894fa2d5163d37e7c34e7ed8368dea29_l3.svg "Rendered by QuickLaTeX.com")
because we’ve expanded after the stopping condition. So the path’s cost will be  .
.
In the other case, we expanded in the reverse search before the stopping condition was obtained, so we can’t conclude that  . However, since has not been reverse-expanded yet, we know that . The path’s cost is also
. However, since has not been reverse-expanded yet, we know that . The path’s cost is also  , so we have:
, so we have:
![\[g_F^*(u) + g_R^*(u) \geq top_F + top_R \geq \mu\]](/wp-content/ql-cache/quicklatex.com-1b1179a097b4bab14fbc31a070e5eced_l3.svg "Rendered by QuickLaTeX.com")
Therefore, is the cost of the optimal path, which proves the correctness of the stopping condition.
4.4. Pseudocode of Bidirectional Search
Finally, here’s the pseudocode of BiUCS:
algorithm BidirectionalUCS(s, t, succ_F, succ_R, c):
// INPUT
// s = the start node
// t = the goal node
// succ_F = the function returning the forward successors of a node
// succ_R = the function returning the reverse successors of a node
// c = the cost function
// OUTPUT
// The optimal path between s and t if it exists; failure otherwise
Q_F, Q_R <- make min-priority queues for the frontiers,
initially containing only s and t
// Q_F is ordered by g_F, and Q_R is ordered by g_R
expanded_F, expanded_R <- make forward and reverse lookup tables
search_F <- (Q_F, expanded_F, succ_F)
search_R <- (Q_R, expanded_R, succ_R)
solution <- failure
mu <- infinity
while top_F + top_R < mu:
if at least one queue is non-empty:
Choose the search to advance.
else:
return solution
if forward search was chosen:
(solution, mu) <- STEP(search_F, search_R, solution, mu)
else:
(solution, mu) <- STEP(search_R, search_F, solution, mu)
return solutionThe  function is responsible for advancing the searches through the graph and updating . Here’s how it works:
function is responsible for advancing the searches through the graph and updating . Here’s how it works:
algorithm STEP(search_1, search_2, solution, mu):
// INPUT
// search_1 = the triple (Q_1, expanded_1, succ_1) chosen search direction
// search_2 = the triple (Q_2, expanded_2, succ_2) other search direction
// solution = the current best solution path
// mu = the cost of the current best-solution's path
// OUTPUT
// the updated solution path and its cost
u <- pop the min-g_1 node from Q_1
for v in succ_1(u):
if v not in expanded_1 union Q_1 or g_1(u) + c(u, v) < g_1(v):
g_1(v) <- g_1(u) + c(u, v)
Add v to Q_1
if v in expanded_2 and g1(v) + g2(v) < mu:
solution <- reconstruct the path through u and v
mu <- g_1(v) + g_2(v)
return (solution, mu)5. Discussion
BiS is possible only if we have explicit goal nodes. If we only have a goal test, then we can’t run the reverse search. That’s also the case if the reverse edges aren’t computationally tractable.
Having more than one goal node isn’t a problem as long as they’re all explicit. Which one do we choose as the source of the reverse search? Neither. We construct an artificial goal node, link it to the actual goals with zero-cost edges, and set it as the reverse source.
BiS is expected to find the optimal path faster than a unidirectional search but is harder to implement and debug. While possible, combining different algorithms for forward and reverse searches may not be justified. If all the edges have constant costs, our best choices are BFS or Iterative Deepening for both searches. In the case that the edge costs differ, we should bidirectionalize UCS or A*.
Finally, the stopping condition may be difficult to formulate and prove. If we design it right, our BiS can be both optimal and complete. The former means that it cannot return a suboptimal path, whereas the latter means that it always terminates returning either a path or a notification of failure. The stopping condition depends on the base algorithms.
6. Conclusion
In this article, we presented generic Bidirectional Search (BiS) and Bidirectional UCS (BiUCS). BiS is a generic search algorithm that runs two unidirectional algorithms in parallel: one that grows its search tree from the start to the goal, and the other that does so from the goal to the start. In general, we expect BiS to find the optimal path faster than single-source algorithms. But, it requires careful design, especially concerning the stopping criteria, and is harder to implement and debug.