

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about real-world examples of tree structures.
Specifically, we’ll discuss problems that arise in the areas of game development, databases, and machine learning and describe how tree structures help to solve these problems.
A tree is a widely used abstract data type that simulates a hierarchical tree structure, with a root value and subtrees of children with a parent node, represented as a set of linked nodes.
Tree structures are an irreplaceable part of nearly every computer science tutorial and algorithms that utilize trees are associated with logarithmic computational complexity, making them extremely fast and efficient:
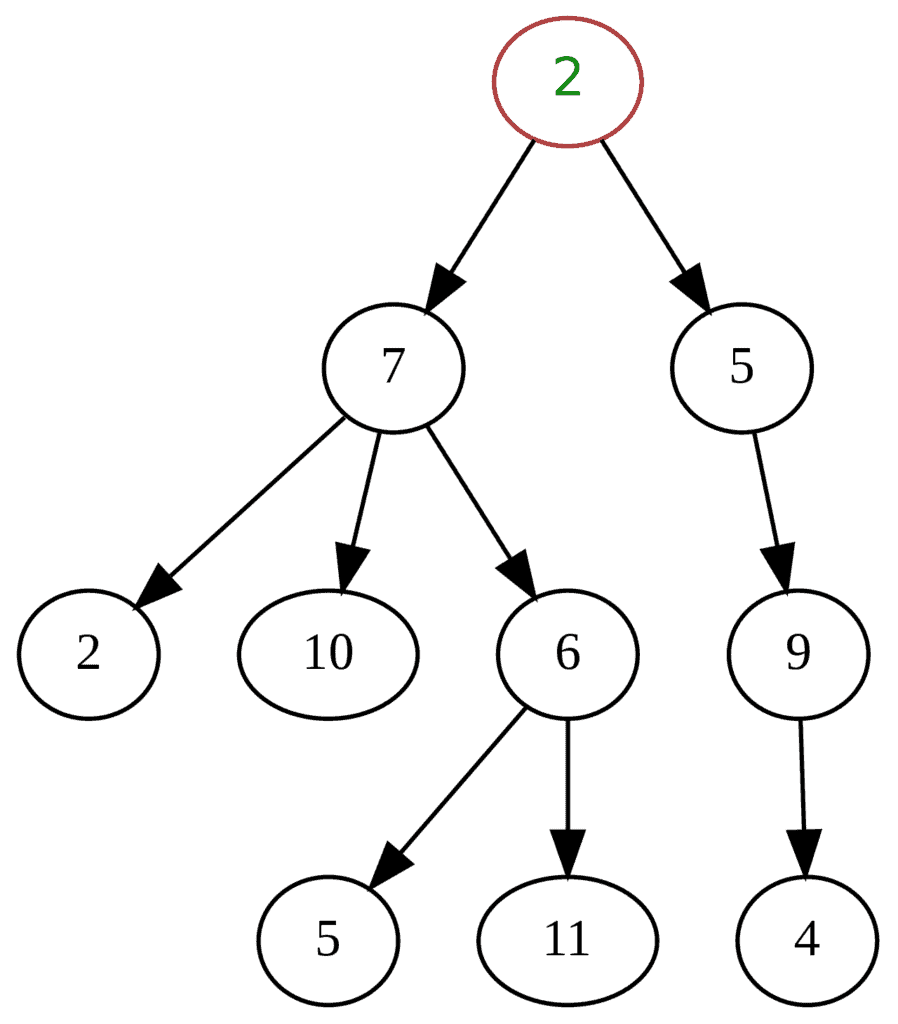
Most of us have either played or watched someone play a 3D video game. A typical scenario involves an avatar controlled by the player wandering around in a virtual environment and interacting with its surroundings. Such games usually contain many virtual entities, representing different objects. In order to have some degree of realism, the user’s avatar should at least interact with these entities as if they were solid objects (instead of passing through them).
For this purpose, collision detection is necessary. It can easily be seen that as the number of entities grows larger, naively checking for collisions with every object becomes computationally infeasible. As a matter of fact, most of these checks are redundant, as the objects and the avatar are too far away.
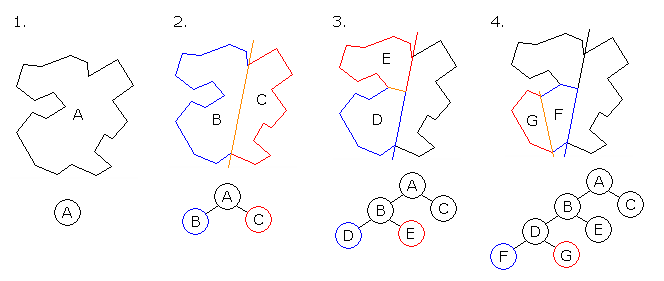
Space partitioning trees recursively divide the space into smaller and smaller cells until a specific cell size is reached. Leaf nodes correspond to regions of the virtual environment and contain the objects that are currently within it. Thus, checking for collisions boils down to finding the cell where the avatar currently is, and checking for collisions with objects only in the neighboring cells.
This process massively reduces the number of calculations and allows real-time collision detection. Examples of space partitioning trees include quadtrees (for dividing a 2d space) and octrees (for 3d spaces):
Databases are an integral part of any application. As time passes, applications become more data-hungry and having a convenient, easily accessible place to store data is very important.
Unfortunately, storage devices are generally slow, often requiring mechanical parts to move in order to access them, like in the case of traditional magnetic hard drives. As such, it is far too inconvenient to do exhaustive searches inside a database, in order to find a specific piece of information. As such, we would like to find the exact memory block where our data entry lies, so we can access it directly.
Fortunately, databases internally contain access structures called indexes, that do just that!
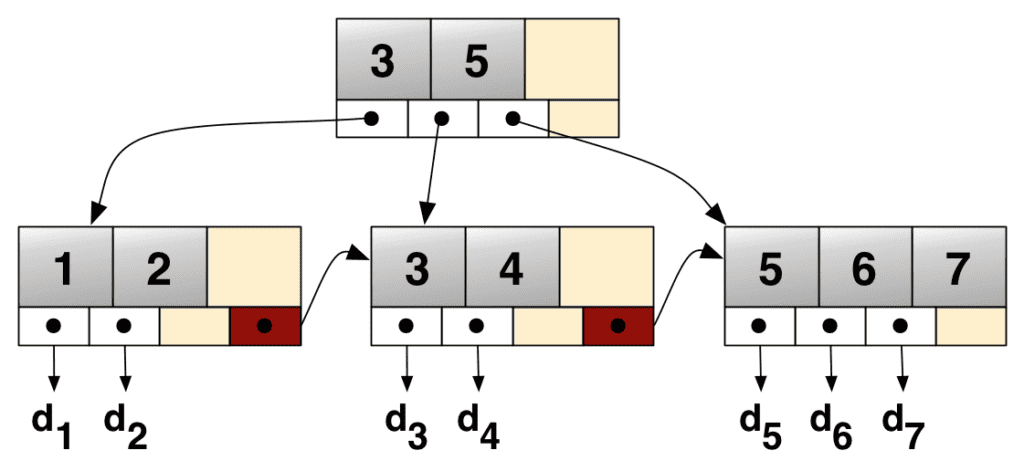
Database indexes are usually based on a special tree structure, called B+ Trees. Given a query key, we want to access a memory block that contains the data entry that satisfies the query. B+ trees divide the possible key values into intervals, the intervals becoming smaller and smaller as we traverse down the tree.
Leaf nodes contain pointers to the memory blocks that contain the data entries within their interval. Pointers to the previous and next leaves also guarantee easy access between them.
In order to access a data entry that satisfies a query, we traverse the tree and find the leaf node whose interval contains the query key. We then follow the pointer of that leaf node and retrieve the appropriate memory block from the storage device.
This is, of course, an oversimplified version of the process. Database indexes have other needs they must accommodate, adding to the complexity of the problem. However, B+ trees form the foundation, upon which this mechanism is built:
So far we have described problems that use trees as a convenience mechanism, in order to reduce complexity and allow faster operations. But how about a method in which the tree itself is the centerpiece?
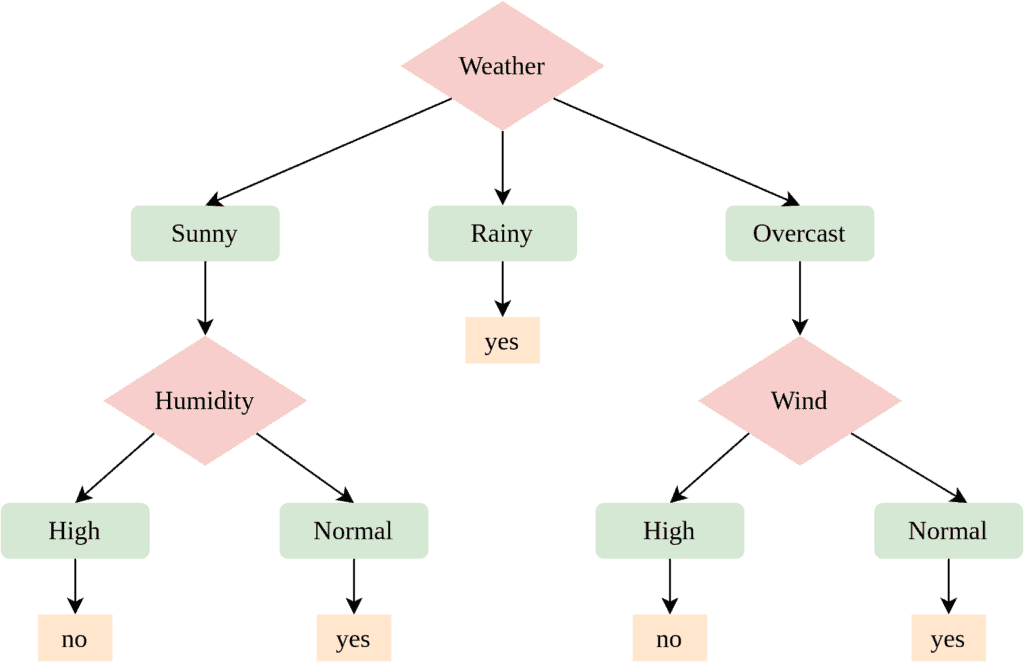
Decision trees are a simple, yet effective machine learning tool, commonly used in decision analysis, where we are trying to determine the optimal action for a problem while taking multiple factors into consideration.
A decision tree needs a “state”, represented as a set of attributes, and outputs a “decision”. Each node describes a value check for one of the attributes and branches out to as many new nodes as there are possible values.
On the other hand, leaf nodes correspond to decisions. Given a set of attributes that apply to a particular problem, we traverse the tree by following branches that correspond to our attribute values and make the decision specified by the leaf node we reach:
In this article, we discussed several use-case scenarios of tree structures to highlight their importance. While applications are by no means limited to the ones mentioned above, we chose these specific applications because the reader is most likely already familiar with them.
Through this article, we’re hoping to ignite interest in these structures, and motivate the reader to learn more about them.